 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference After Adaptive Sampling in Non-Markovian Environments
Feb 14, 2022
There is a great desire to use adaptive sampling methods, such as reinforcement learning (RL) and bandit algorithms, for the real-time personalization of interventions in digital applications like mobile health and education. A major obstacle preventing more widespread use of such algorithms in practice is the lack of assurance that the resulting adaptively collected data can be used to reliably answer inferential questions, including questions about time-varying causal effects. Current methods for statistical inference on such data are insufficient because they (a) make strong assumptions regarding the environment dynamics, e.g., assume a contextual bandit or Markovian environment, or (b) require data to be collected with one adaptive sampling algorithm per user, which excludes data collected by algorithms that learn to select actions by pooling the data of multiple users. In this work, we make initial progress by introducing the adaptive sandwich estimator to quantify uncertainty; this estimator (a) is valid even when user rewards and contexts are non-stationary and highly dependent over time, and (b) accommodates settings in which an online adaptive sampling algorithm learns using the data of all users. Furthermore, our inference method is robust to misspecification of the reward models used by the adaptive sampling algorithm. This work is motivated by our work designing experiments in which RL algorithms are used to select actions, yet reliable statistical inference is essential for conducting primary analyses after the trial is over.
Streamlined Empirical Bayes Fitting of Linear Mixed Models in Mobile Health
Mar 28, 2020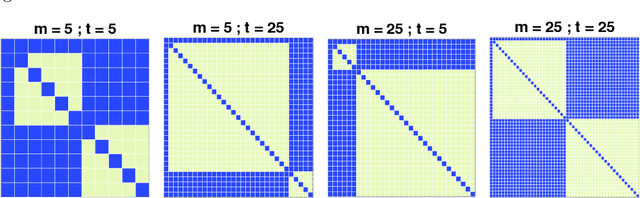
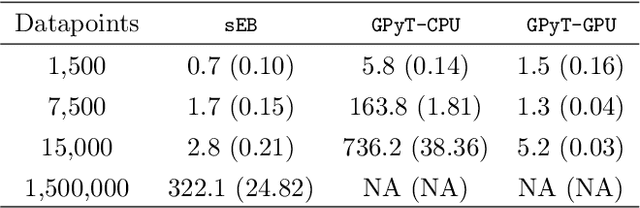
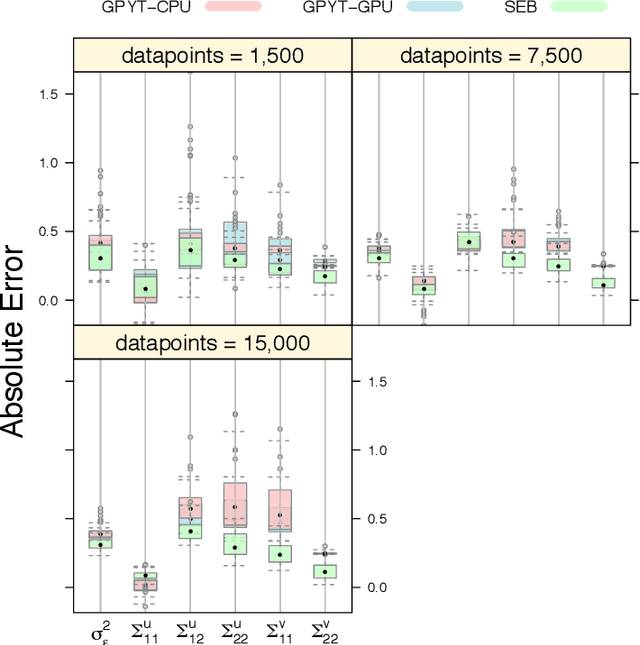
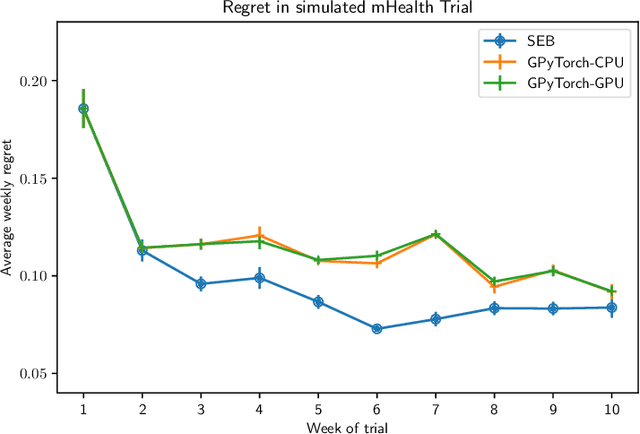
To effect behavior change a successful algorithm must make high-quality decisions in real-time. For example, a mobile health (mHealth) application designed to increase physical activity must make contextually relevant suggestions to motivate users. While machine learning offers solutions for certain stylized settings, such as when batch data can be processed offline, there is a dearth of approaches which can deliver high-quality solutions under the specific constraints of mHealth. We propose an algorithm which provides users with contextualized and personalized physical activity suggestions. This algorithm is able to overcome a challenge critical to mHealth that complex models be trained efficiently. We propose a tractable streamlined empirical Bayes procedure which fits linear mixed effects models in large-data settings. Our procedure takes advantage of sparsity introduced by hierarchical random effects to efficiently learn the posterior distribution of a linear mixed effects model. A key contribution of this work is that we provide explicit updates in order to learn both fixed effects, random effects and hyper-parameter values. We demonstrate the success of this approach in a mobile health (mHealth) reinforcement learning application, a domain in which fast computations are crucial for real time interventions. Not only is our approach computationally efficient, it is also easily implemented with closed form matrix algebraic updates and we show improvements over state of the art approaches both in speed and accuracy of up to 99% and 56% respectively.