 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUBLICSPEAK: Hearing the Public with a Probabilistic Framework in Local Government
Mar 14, 2025Local governments around the world are making consequential decisions on behalf of their constituents, and these constituents are responding with requests, advice, and assessments of their officials at public meetings. So many small meetings cannot be covered by traditional newsrooms at scale. We propose PUBLICSPEAK, a probabilistic framework which can utilize meeting structure, domain knowledge, and linguistic information to discover public remarks in local government meetings. We then use our approach to inspect the issues raised by constituents in 7 cities across the United States. We evaluate our approach on a novel dataset of local government meetings and find that PUBLICSPEAK improves over state-of-the-art by 10% on average, and by up to 40%.
Doubly robust nearest neighbors in factor models
Nov 28, 2022In this technical note, we introduce an improved variant of nearest neighbors for counterfactual inference in panel data settings where multiple units are assigned multiple treatments over multiple time points, each sampled with constant probabilities. We call this estimator a doubly robust nearest neighbor estimator and provide a high probability non-asymptotic error bound for the mean parameter corresponding to each unit at each time. Our guarantee shows that the doubly robust estimator provides a (near-)quadratic improvement in the error compared to nearest neighbor estimators analyzed in prior work for these settings.
Fast Physical Activity Suggestions: Efficient Hyperparameter Learning in Mobile Health
Dec 21, 2020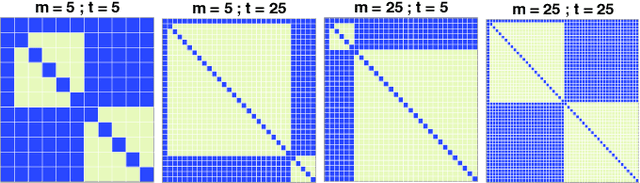
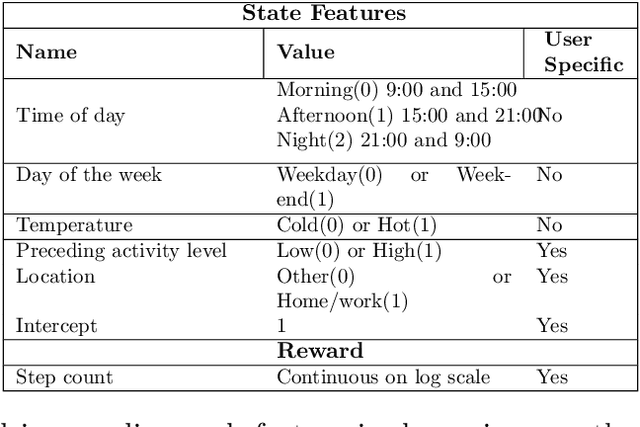
Users can be supported to adopt healthy behaviors, such as regular physical activity, via relevant and timely suggestions on their mobile devices. Recently, reinforcement learning algorithms have been found to be effective for learning the optimal context under which to provide suggestions. However, these algorithms are not necessarily designed for the constraints posed by mobile health (mHealth) settings, that they be efficient, domain-informed and computationally affordable. We propose an algorithm for providing physical activity suggestions in mHealth settings. Using domain-science, we formulate a contextual bandit algorithm which makes use of a linear mixed effects model. We then introduce a procedure to efficiently perform hyper-parameter updating, using far less computational resources than competing approaches. Not only is our approach computationally efficient, it is also easily implemented with closed form matrix algebraic updates and we show improvements over state of the art approaches both in speed and accuracy of up to 99% and 56% respectively.
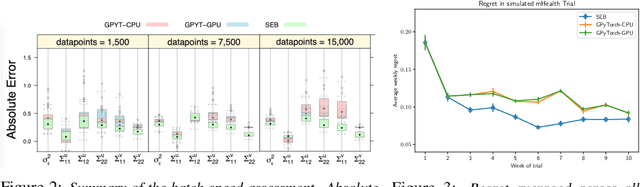
IntelligentPooling: Practical Thompson Sampling for mHealth
Jul 31, 2020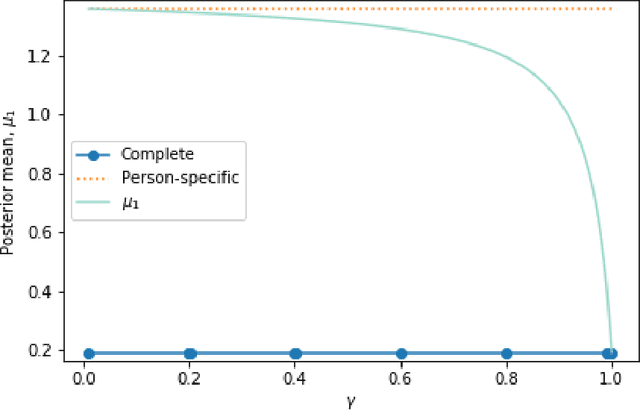
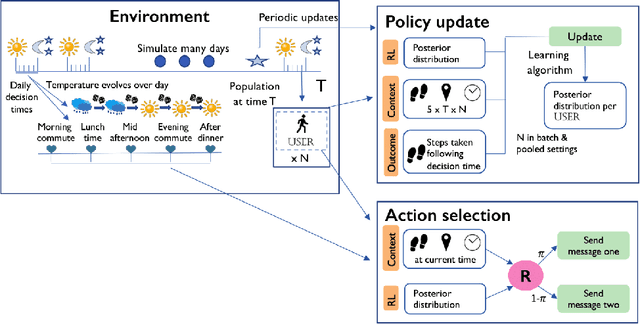

In mobile health (mHealth) smart devices deliver behavioral treatments repeatedly over time to a user with the goal of helping the user adopt and maintain healthy behaviors. Reinforcement learning appears ideal for learning how to optimally make these sequential treatment decisions. However, significant challenges must be overcome before reinforcement learning can be effectively deployed in a mobile healthcare setting. In this work we are concerned with the following challenges: 1) individuals who are in the same context can exhibit differential response to treatments 2) only a limited amount of data is available for learning on any one individual, and 3) non-stationary responses to treatment. To address these challenges we generalize Thompson-Sampling bandit algorithms to develop IntelligentPooling. IntelligentPooling learns personalized treatment policies thus addressing challenge one. To address the second challenge, IntelligentPooling updates each user's degree of personalization while making use of available data on other users to speed up learning. Lastly, IntelligentPooling allows responsivity to vary as a function of a user's time since beginning treatment, thus addressing challenge three. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art. We demonstrate the promise of this approach and its ability to learn from even a small group of users in a live clinical trial.
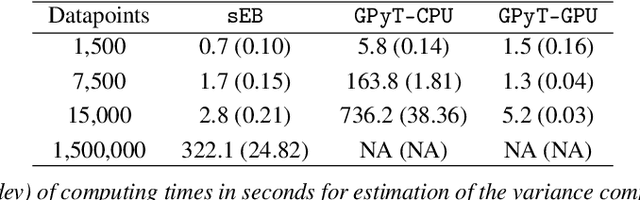
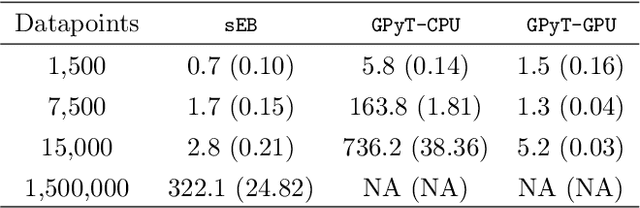
Streamlined Empirical Bayes Fitting of Linear Mixed Models in Mobile Health
Mar 28, 2020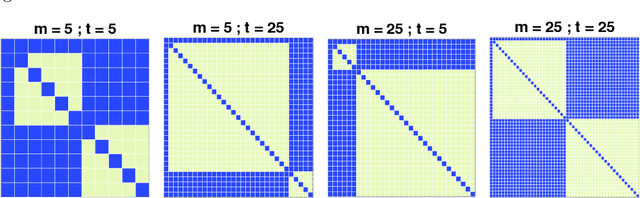
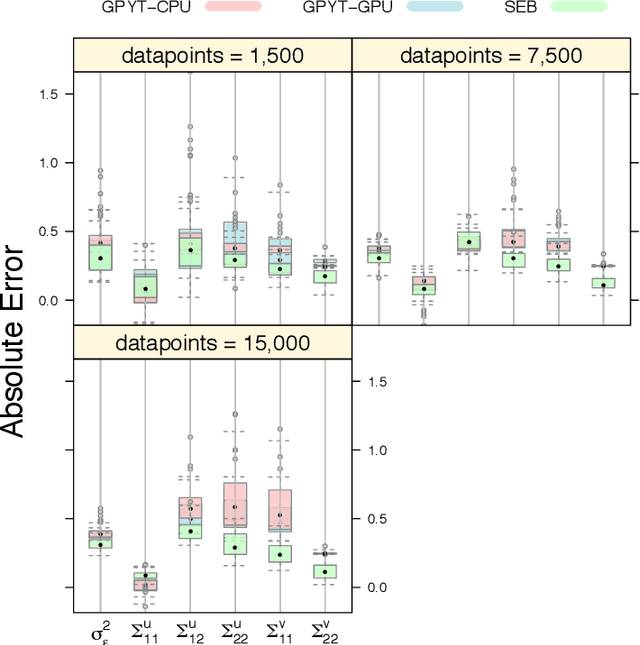
To effect behavior change a successful algorithm must make high-quality decisions in real-time. For example, a mobile health (mHealth) application designed to increase physical activity must make contextually relevant suggestions to motivate users. While machine learning offers solutions for certain stylized settings, such as when batch data can be processed offline, there is a dearth of approaches which can deliver high-quality solutions under the specific constraints of mHealth. We propose an algorithm which provides users with contextualized and personalized physical activity suggestions. This algorithm is able to overcome a challenge critical to mHealth that complex models be trained efficiently. We propose a tractable streamlined empirical Bayes procedure which fits linear mixed effects models in large-data settings. Our procedure takes advantage of sparsity introduced by hierarchical random effects to efficiently learn the posterior distribution of a linear mixed effects model. A key contribution of this work is that we provide explicit updates in order to learn both fixed effects, random effects and hyper-parameter values. We demonstrate the success of this approach in a mobile health (mHealth) reinforcement learning application, a domain in which fast computations are crucial for real time interventions. Not only is our approach computationally efficient, it is also easily implemented with closed form matrix algebraic updates and we show improvements over state of the art approaches both in speed and accuracy of up to 99% and 56% respectively.
Rapidly Personalizing Mobile Health Treatment Policies with Limited Data
Feb 23, 2020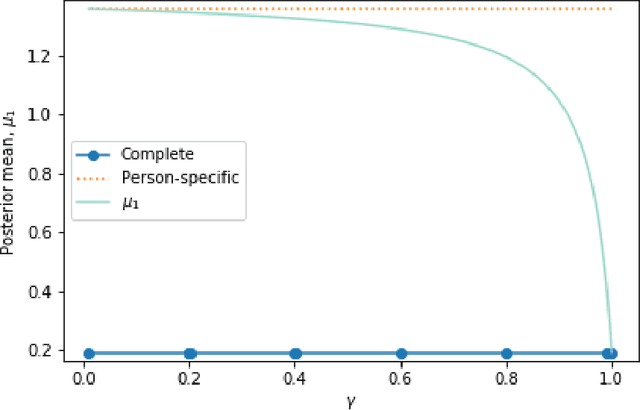
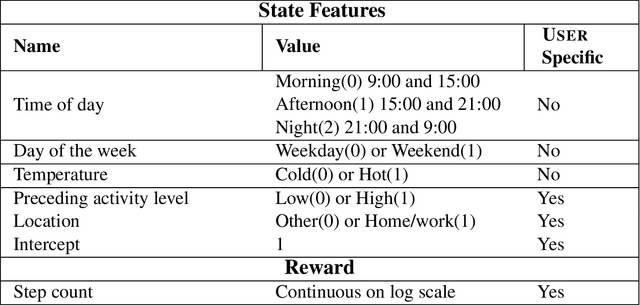
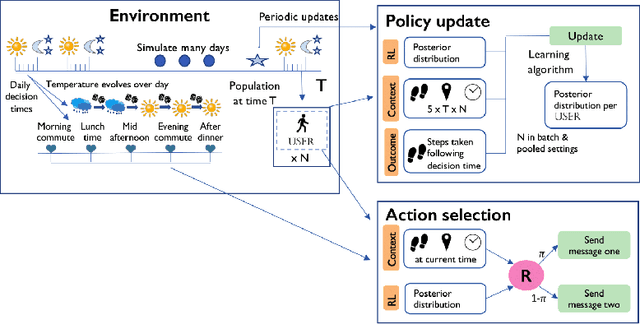

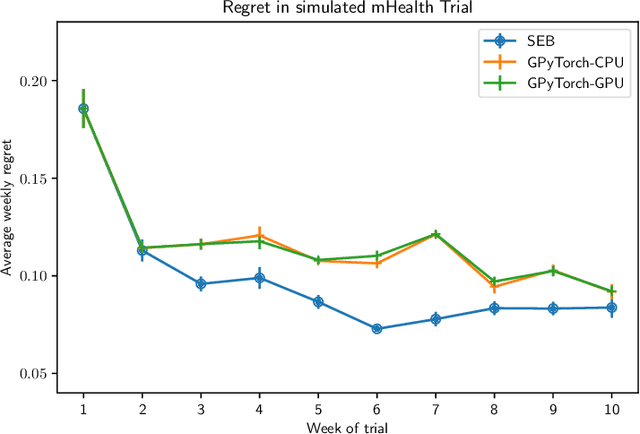
In mobile health (mHealth), reinforcement learning algorithms that adapt to one's context without learning personalized policies might fail to distinguish between the needs of individuals. Yet the high amount of noise due to the in situ delivery of mHealth interventions can cripple the ability of an algorithm to learn when given access to only a single user's data, making personalization challenging. We present IntelligentPooling, which learns personalized policies via an adaptive, principled use of other users' data. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art across all generative models. Additionally, we inspect the behavior of this approach in a live clinical trial, demonstrating its ability to learn from even a small group of users.
Personalizing Intervention Probabilities By Pooling
Dec 02, 2018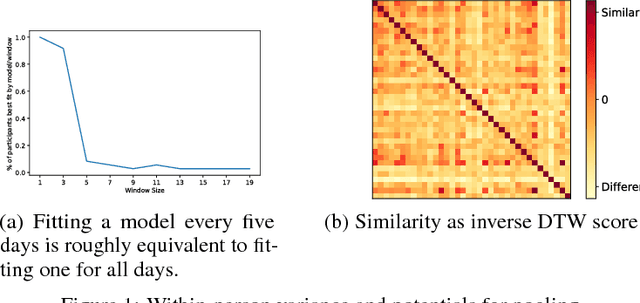
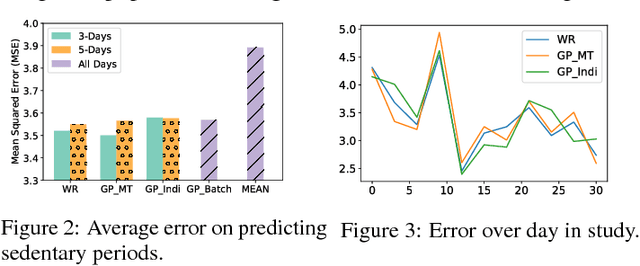
In many mobile health interventions, treatments should only be delivered in a particular context, for example when a user is currently stressed, walking or sedentary. Even in an optimal context, concerns about user burden can restrict which treatments are sent. To diffuse the treatment delivery over times when a user is in a desired context, it is critical to predict the future number of times the context will occur. The focus of this paper is on whether personalization can improve predictions in these settings. Though the variance between individuals' behavioral patterns suggest that personalization should be useful, the amount of individual-level data limits its capabilities. Thus, we investigate several methods which pool data across users to overcome these deficiencies and find that pooling lowers the overall error rate relative to both personalized and batch approaches.