 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-EMT-NAS: Multi-Objective Continuous Transfer of Architectural Knowledge Between Tasks from Different Datasets
Jul 18, 2024



Deploying models across diverse devices demands tradeoffs among multiple objectives due to different resource constraints. Arguably, due to the small model trap problem in multi-objective neural architecture search (MO-NAS) based on a supernet, existing approaches may fail to maintain large models. Moreover, multi-tasking neural architecture search (MT-NAS) excels in handling multiple tasks simultaneously, but most existing efforts focus on tasks from the same dataset, limiting their practicality in real-world scenarios where multiple tasks may come from distinct datasets. To tackle the above challenges, we propose a Multi-Objective Evolutionary Multi-Tasking framework for NAS (MO-EMT-NAS) to achieve architectural knowledge transfer across tasks from different datasets while finding Pareto optimal architectures for multi-objectives, model accuracy and computational efficiency. To alleviate the small model trap issue, we introduce an auxiliary objective that helps maintain multiple larger models of similar accuracy. Moreover, the computational efficiency is further enhanced by parallelizing the training and validation of the weight-sharing-based supernet. Experimental results on seven datasets with two, three, and four task combinations show that MO-EMT-NAS achieves a better minimum classification error while being able to offer flexible trade-offs between model performance and complexity, compared to the state-of-the-art single-objective MT-NAS algorithms. The runtime of MO-EMT-NAS is reduced by 59.7% to 77.7%, compared to the corresponding multi-objective single-task approaches.
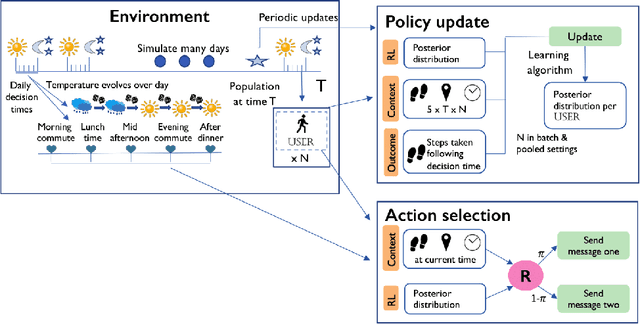
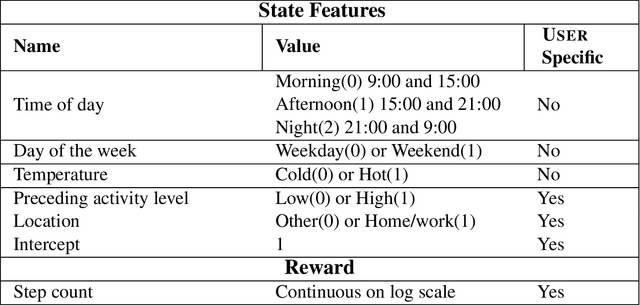
Did we personalize? Assessing personalization by an online reinforcement learning algorithm using resampling
Apr 24, 2023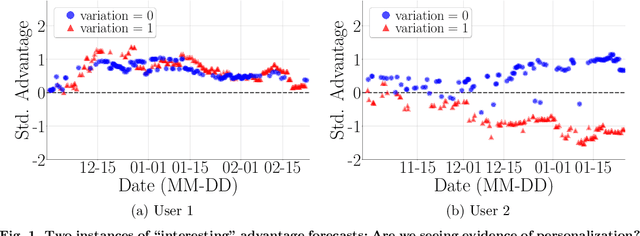
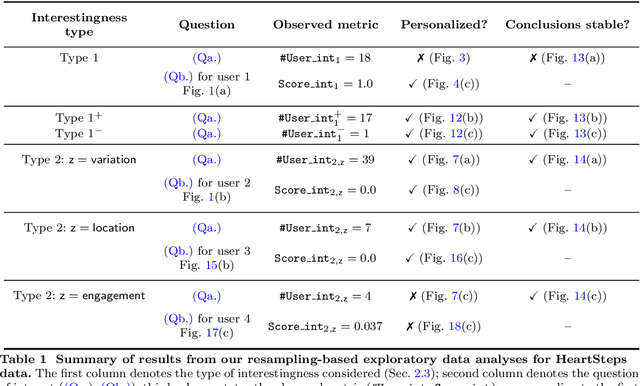
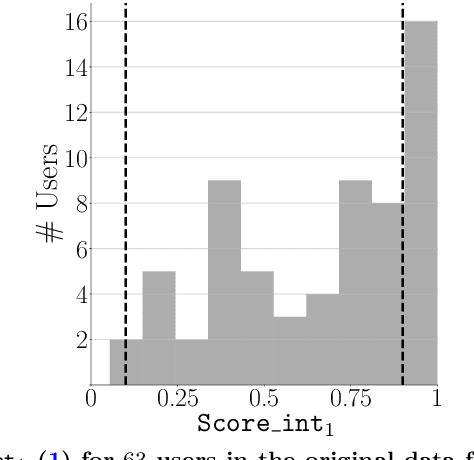
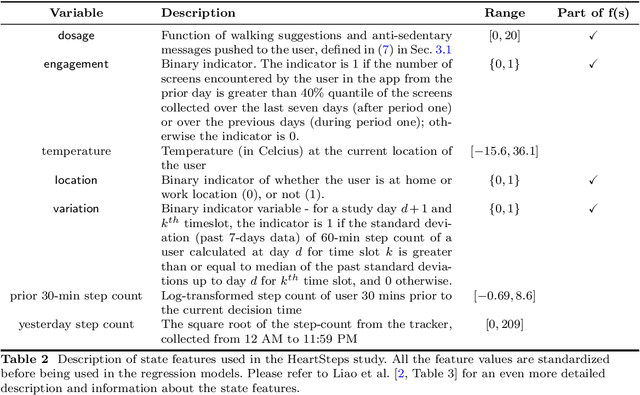
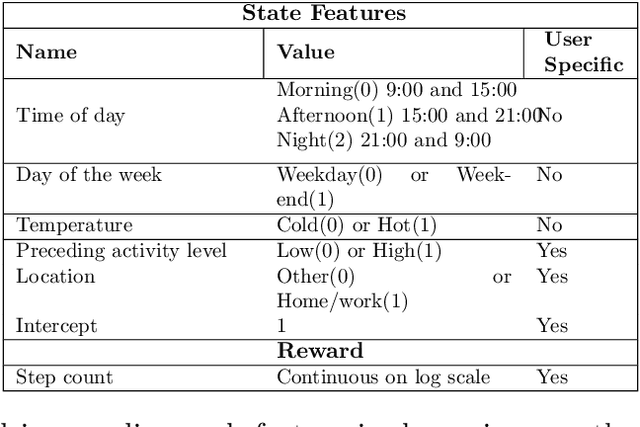
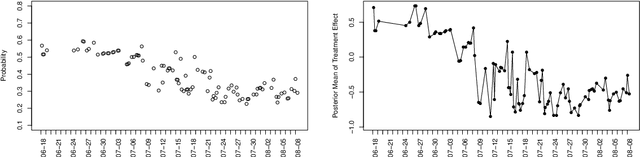
There is a growing interest in using reinforcement learning (RL) to personalize sequences of treatments in digital health to support users in adopting healthier behaviors. Such sequential decision-making problems involve decisions about when to treat and how to treat based on the user's context (e.g., prior activity level, location, etc.). Online RL is a promising data-driven approach for this problem as it learns based on each user's historical responses and uses that knowledge to personalize these decisions. However, to decide whether the RL algorithm should be included in an ``optimized'' intervention for real-world deployment, we must assess the data evidence indicating that the RL algorithm is actually personalizing the treatments to its users. Due to the stochasticity in the RL algorithm, one may get a false impression that it is learning in certain states and using this learning to provide specific treatments. We use a working definition of personalization and introduce a resampling-based methodology for investigating whether the personalization exhibited by the RL algorithm is an artifact of the RL algorithm stochasticity. We illustrate our methodology with a case study by analyzing the data from a physical activity clinical trial called HeartSteps, which included the use of an online RL algorithm. We demonstrate how our approach enhances data-driven truth-in-advertising of algorithm personalization both across all users as well as within specific users in the study.
Robust Batch Policy Learning in Markov Decision Processes
Nov 10, 2020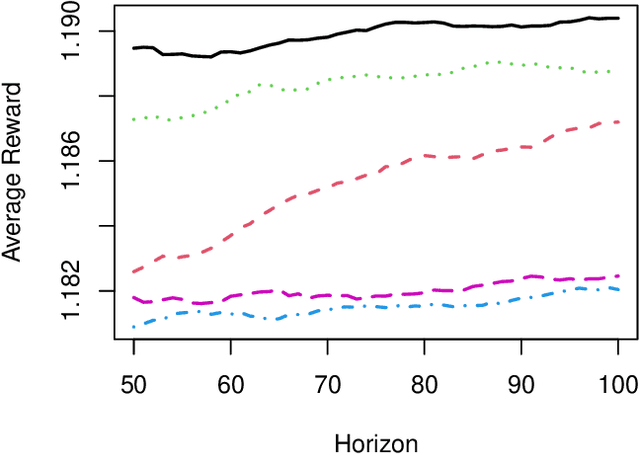
We consider a varying horizon Markov decision process (MDP), where each policy is evaluated by a set containing average rewards over different horizon lengths with different reference distributions. Given a pre-collected dataset of multiple trajectories generated by some behavior policy, our goal is to learn a robust policy in a pre-specified policy class that can approximately maximize the smallest value of this set. Leveraging semi-parametric statistics, we develop an efficient policy learning method for estimating the defined robust optimal policy that can efficiently break the curse of horizon. A rate-optimal regret bound up to a logarithmic factor is established in terms of the number of trajectories and the number of decision points. Our regret guarantee subsumes the long-term average reward MDP setting as a special case.
IntelligentPooling: Practical Thompson Sampling for mHealth
Jul 31, 2020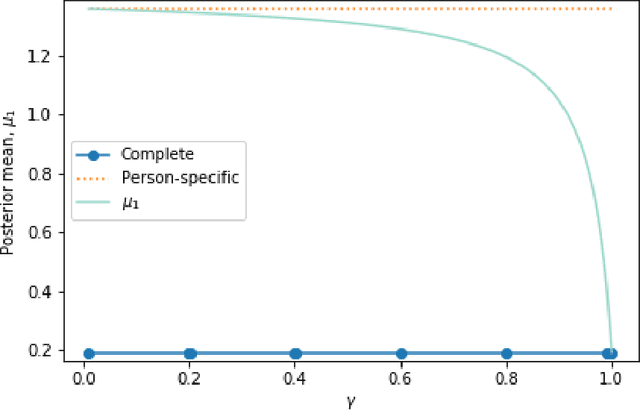

In mobile health (mHealth) smart devices deliver behavioral treatments repeatedly over time to a user with the goal of helping the user adopt and maintain healthy behaviors. Reinforcement learning appears ideal for learning how to optimally make these sequential treatment decisions. However, significant challenges must be overcome before reinforcement learning can be effectively deployed in a mobile healthcare setting. In this work we are concerned with the following challenges: 1) individuals who are in the same context can exhibit differential response to treatments 2) only a limited amount of data is available for learning on any one individual, and 3) non-stationary responses to treatment. To address these challenges we generalize Thompson-Sampling bandit algorithms to develop IntelligentPooling. IntelligentPooling learns personalized treatment policies thus addressing challenge one. To address the second challenge, IntelligentPooling updates each user's degree of personalization while making use of available data on other users to speed up learning. Lastly, IntelligentPooling allows responsivity to vary as a function of a user's time since beginning treatment, thus addressing challenge three. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art. We demonstrate the promise of this approach and its ability to learn from even a small group of users in a live clinical trial.
Batch Policy Learning in Average Reward Markov Decision Processes
Jul 23, 2020
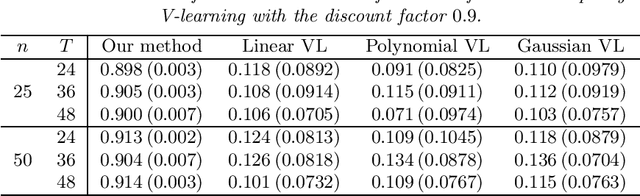
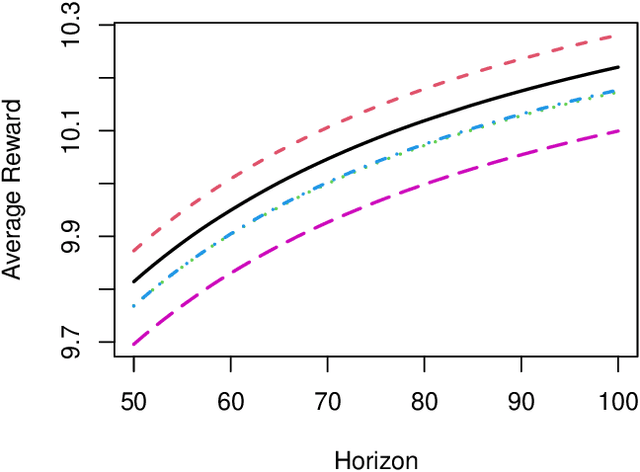
We consider the batch (off-line) policy learning problem in the infinite horizon Markov Decision Process. Motivated by mobile health applications, we focus on learning a policy that maximizes the long-term average reward. We propose a doubly robust estimator for the average reward and show that it achieves semiparametric efficiency given multiple trajectories collected under some behavior policy. Based on the proposed estimator, we develop an optimization algorithm to compute the optimal policy in a parameterized stochastic policy class. The performance of the estimated policy is measured by the difference between the optimal average reward in the policy class and the average reward of the estimated policy and we establish a finite-sample regret guarantee. To the best of our knowledge, this is the first regret bound for batch policy learning in the infinite time horizon setting. The performance of the method is illustrated by simulation studies.
Rapidly Personalizing Mobile Health Treatment Policies with Limited Data
Feb 23, 2020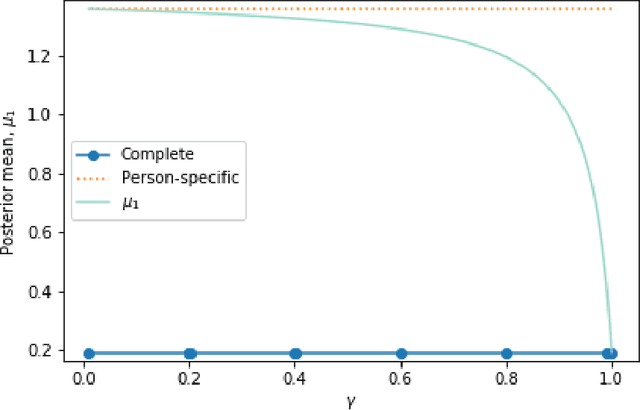
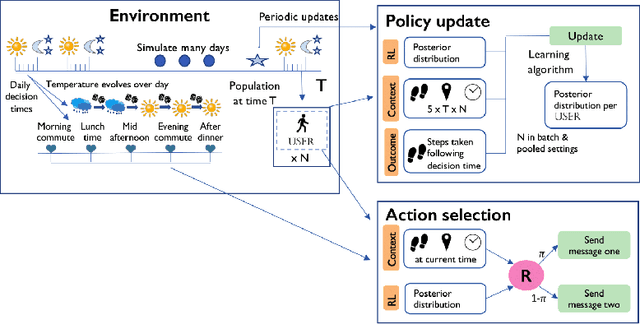

In mobile health (mHealth), reinforcement learning algorithms that adapt to one's context without learning personalized policies might fail to distinguish between the needs of individuals. Yet the high amount of noise due to the in situ delivery of mHealth interventions can cripple the ability of an algorithm to learn when given access to only a single user's data, making personalization challenging. We present IntelligentPooling, which learns personalized policies via an adaptive, principled use of other users' data. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art across all generative models. Additionally, we inspect the behavior of this approach in a live clinical trial, demonstrating its ability to learn from even a small group of users.
Off-Policy Estimation of Long-Term Average Outcomes with Applications to Mobile Health
Dec 30, 2019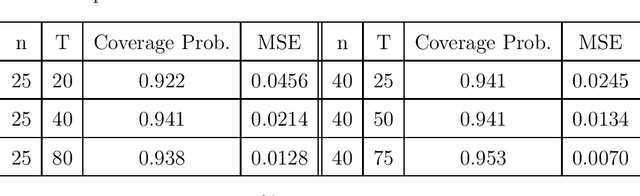
With the recent advancements in wearables and sensing technology, health scientists are increasingly developing mobile health (mHealth) interventions. In mHealth interventions, mobile devices are used to deliver treatment to individuals as they go about their daily lives, generally designed to impact a near time, proximal outcome such as stress or physical activity. The mHealth intervention policies, often called Just-In-time Adaptive Interventions, are decision rules that map a user's context to a particular treatment at each of many time points. The vast majority of current mHealth interventions deploy expert-derived policies. In this paper, we provide an approach for conducting inference about the performance of one or more such policies. In particular, we estimate the performance of a mHealth policy using historical data that are collected under a possibly different policy. Our measure of performance is the average of proximal outcomes (rewards) over a long time period should the particular mHealth policy be followed. We provide a semi-parametric efficient estimator as well as the confidence intervals. This work is motivated by HeartSteps, a mobile health physical activity intervention.
Personalized HeartSteps: A Reinforcement Learning Algorithm for Optimizing Physical Activity
Sep 08, 2019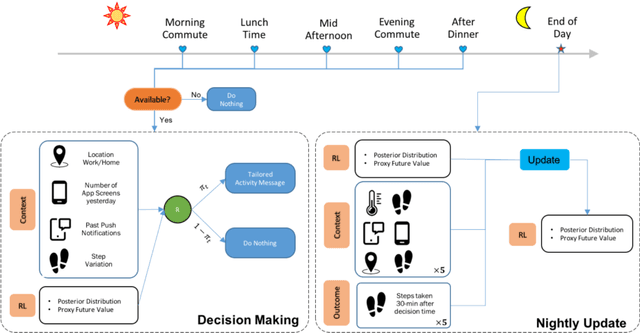


With the recent evolution of mobile health technologies, health scientists are increasingly interested in developing just-in-time adaptive interventions (JITAIs), typically delivered via notification on mobile device and designed to help the user prevent negative health outcomes and promote the adoption and maintenance of healthy behaviors. A JITAI involves a sequence of decision rules (i.e., treatment policy) that takes the user's current context as input and specifies whether and what type of an intervention should be provided at the moment. In this paper, we develop a Reinforcement Learning (RL) algorithm that continuously learns and improves the treatment policy embedded in the JITAI as the data is being collected from the user. This work is motivated by our collaboration on designing the RL algorithm in HeartSteps V2 based on data from HeartSteps V1. HeartSteps is a physical activity mobile health application. The RL algorithm developed in this paper is being used in HeartSteps V2 to decide, five times per day, whether to deliver a context-tailored activity suggestion.
Cohesion-based Online Actor-Critic Reinforcement Learning for mHealth Intervention
Aug 23, 2017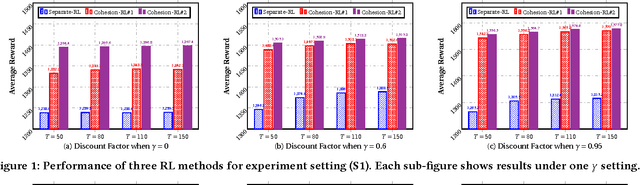

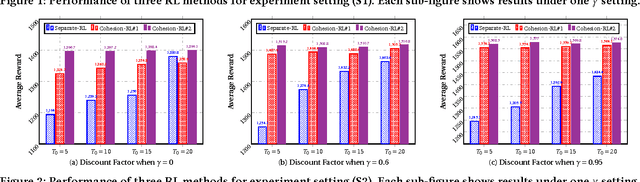
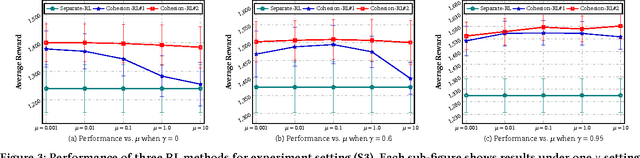
In the wake of the vast population of smart device users worldwide, mobile health (mHealth) technologies are hopeful to generate positive and wide influence on people's health. They are able to provide flexible, affordable and portable health guides to device users. Current online decision-making methods for mHealth assume that the users are completely heterogeneous. They share no information among users and learn a separate policy for each user. However, data for each user is very limited in size to support the separate online learning, leading to unstable policies that contain lots of variances. Besides, we find the truth that a user may be similar with some, but not all, users, and connected users tend to have similar behaviors. In this paper, we propose a network cohesion constrained (actor-critic) Reinforcement Learning (RL) method for mHealth. The goal is to explore how to share information among similar users to better convert the limited user information into sharper learned policies. To the best of our knowledge, this is the first online actor-critic RL for mHealth and first network cohesion constrained (actor-critic) RL method in all applications. The network cohesion is important to derive effective policies. We come up with a novel method to learn the network by using the warm start trajectory, which directly reflects the users' property. The optimization of our model is difficult and very different from the general supervised learning due to the indirect observation of values. As a contribution, we propose two algorithms for the proposed online RLs. Apart from mHealth, the proposed methods can be easily applied or adapted to other health-related tasks. Extensive experiment results on the HeartSteps dataset demonstrates that in a variety of parameter settings, the proposed two methods obtain obvious improvements over the state-of-the-art methods.
Group-driven Reinforcement Learning for Personalized mHealth Intervention
Aug 14, 2017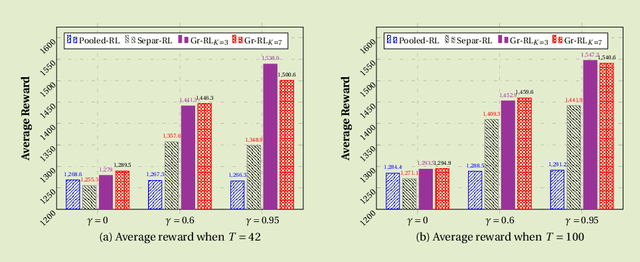
Due to the popularity of smartphones and wearable devices nowadays, mobile health (mHealth) technologies are promising to bring positive and wide impacts on people's health. State-of-the-art decision-making methods for mHealth rely on some ideal assumptions. Those methods either assume that the users are completely homogenous or completely heterogeneous. However, in reality, a user might be similar with some, but not all, users. In this paper, we propose a novel group-driven reinforcement learning method for the mHealth. We aim to understand how to share information among similar users to better convert the limited user information into sharper learned RL policies. Specifically, we employ the K-means clustering method to group users based on their trajectory information similarity and learn a shared RL policy for each group. Extensive experiment results have shown that our method can achieve clear gains over the state-of-the-art RL methods for mHealth.