 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Actor-Critic Contextual Bandit for Mobile Health (mHealth) Interventions
Feb 27, 2018
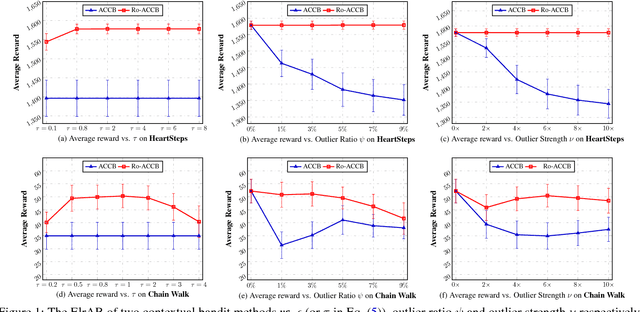
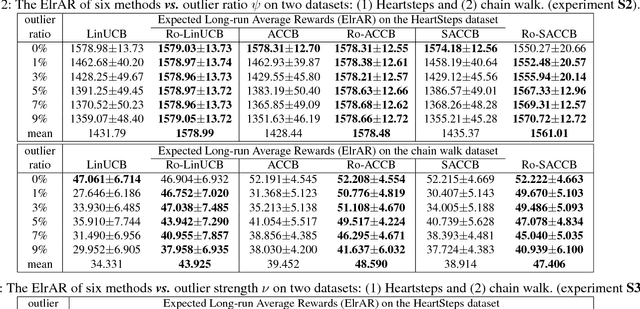

We consider the actor-critic contextual bandit for the mobile health (mHealth) intervention. State-of-the-art decision-making algorithms generally ignore the outliers in the dataset. In this paper, we propose a novel robust contextual bandit method for the mHealth. It can achieve the conflicting goal of reducing the influence of outliers while seeking for a similar solution compared with the state-of-the-art contextual bandit methods on the datasets without outliers. Such performance relies on two technologies: (1) the capped-$\ell_{2}$ norm; (2) a reliable method to set the thresholding hyper-parameter, which is inspired by one of the most fundamental techniques in the statistics. Although the model is non-convex and non-differentiable, we propose an effective reweighted algorithm and provide solid theoretical analyses. We prove that the proposed algorithm can find sufficiently decreasing points after each iteration and finally converges after a finite number of iterations. Extensive experiment results on two datasets demonstrate that our method can achieve almost identical results compared with state-of-the-art contextual bandit methods on the dataset without outliers, and significantly outperform those state-of-the-art methods on the badly noised dataset with outliers in a variety of parameter settings.
Adaptive Graph Convolutional Neural Networks
Jan 10, 2018

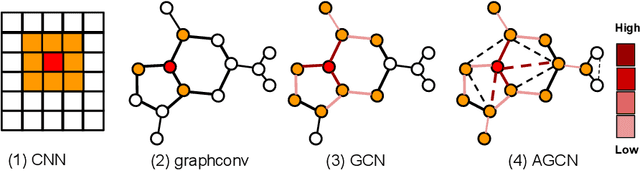

Graph Convolutional Neural Networks (Graph CNNs) are generalizations of classical CNNs to handle graph data such as molecular data, point could and social networks. Current filters in graph CNNs are built for fixed and shared graph structure. However, for most real data, the graph structures varies in both size and connectivity. The paper proposes a generalized and flexible graph CNN taking data of arbitrary graph structure as input. In that way a task-driven adaptive graph is learned for each graph data while training. To efficiently learn the graph, a distance metric learning is proposed. Extensive experiments on nine graph-structured datasets have demonstrated the superior performance improvement on both convergence speed and predictive accuracy.
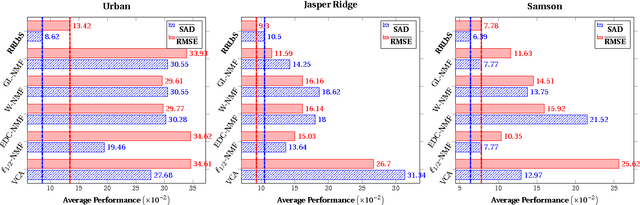
Hyperspectral Unmixing: Ground Truth Labeling, Datasets, Benchmark Performances and Survey
Oct 11, 2017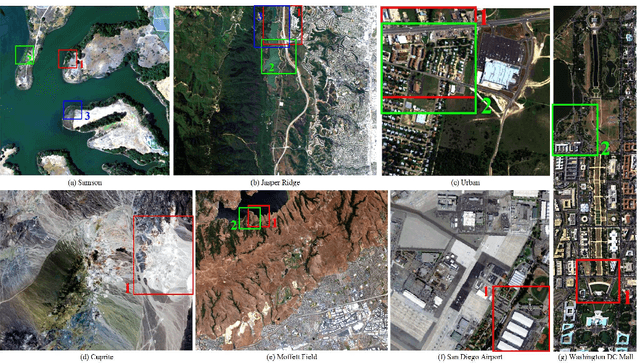
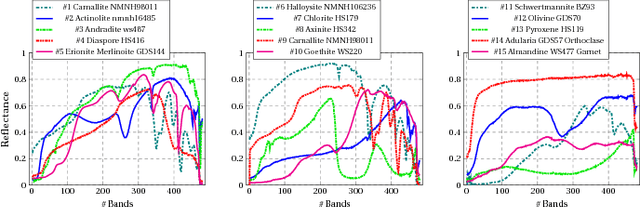
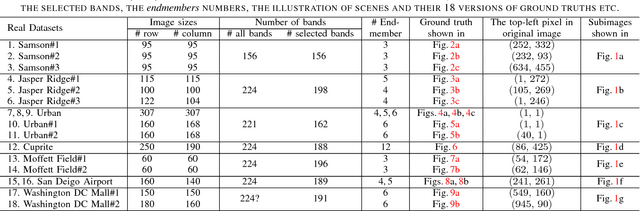
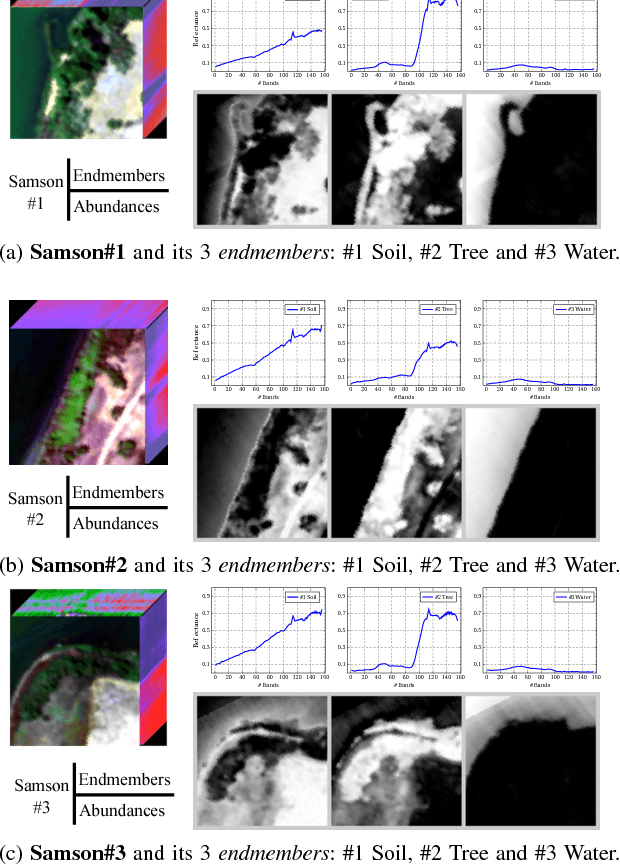
Hyperspectral unmixing (HU) is a very useful and increasingly popular preprocessing step for a wide range of hyperspectral applications. However, the HU research has been constrained a lot by three factors: (a) the number of hyperspectral images (especially the ones with ground truths) are very limited; (b) the ground truths of most hyperspectral images are not shared on the web, which may cause lots of unnecessary troubles for researchers to evaluate their algorithms; (c) the codes of most state-of-the-art methods are not shared, which may also delay the testing of new methods. Accordingly, this paper deals with the above issues from the following three perspectives: (1) as a profound contribution, we provide a general labeling method for the HU. With it, we labeled up to 15 hyperspectral images, providing 18 versions of ground truths. To the best of our knowledge, this is the first paper to summarize and share up to 15 hyperspectral images and their 18 versions of ground truths for the HU. Observing that the hyperspectral classification (HyC) has much more standard datasets (whose ground truths are generally publicly shared) than the HU, we propose an interesting method to transform the HyC datasets for the HU research. (2) To further facilitate the evaluation of HU methods under different conditions, we reviewed and implemented the algorithm to generate a complex synthetic hyperspectral image. By tuning the hyper-parameters in the code, we may verify the HU methods from four perspectives. The code would also be shared on the web. (3) To provide a standard comparison, we reviewed up to 10 state-of-the-art HU algorithms, then selected the 5 most benchmark HU algorithms, and compared them on the 15 real hyperspectral datasets. The experiment results are surely reproducible; the implemented codes would be shared on the web.
Effective Spectral Unmixing via Robust Representation and Learning-based Sparsity
Aug 26, 2017
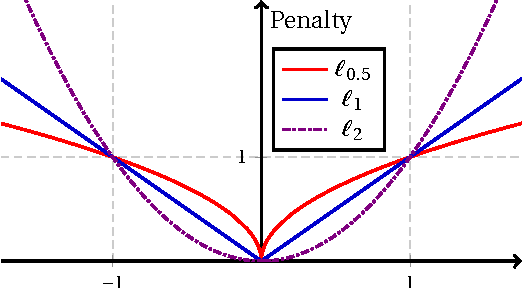

Hyperspectral unmixing (HU) plays a fundamental role in a wide range of hyperspectral applications. It is still challenging due to the common presence of outlier channels and the large solution space. To address the above two issues, we propose a novel model by emphasizing both robust representation and learning-based sparsity. Specifically, we apply the $\ell_{2,1}$-norm to measure the representation error, preventing outlier channels from dominating our objective. In this way, the side effects of outlier channels are greatly relieved. Besides, we observe that the mixed level of each pixel varies over image grids. Based on this observation, we exploit a learning-based sparsity method to simultaneously learn the HU results and a sparse guidance map. Via this guidance map, the sparsity constraint in the $\ell_{p}\!\left(\!0\!<\! p\!\leq\!1\right)$-norm is adaptively imposed according to the learnt mixed level of each pixel. Compared with state-of-the-art methods, our model is better suited to the real situation, thus expected to achieve better HU results. The resulted objective is highly non-convex and non-smooth, and so it is hard to optimize. As a profound theoretical contribution, we propose an efficient algorithm to solve it. Meanwhile, the convergence proof and the computational complexity analysis are systematically provided. Extensive evaluations verify that our method is highly promising for the HU task---it achieves very accurate guidance maps and much better HU results compared with state-of-the-art methods.
Cohesion-based Online Actor-Critic Reinforcement Learning for mHealth Intervention
Aug 23, 2017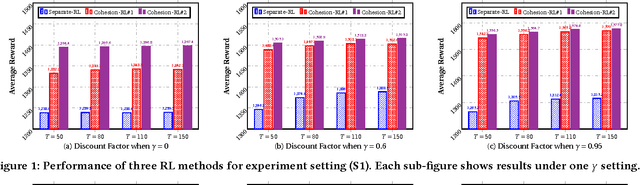

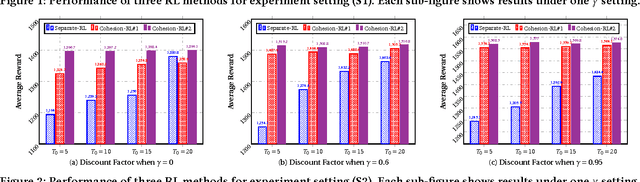
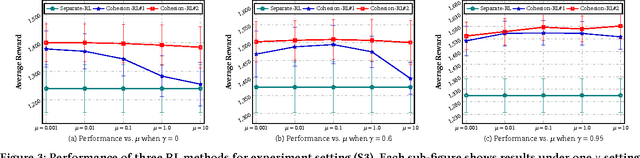
In the wake of the vast population of smart device users worldwide, mobile health (mHealth) technologies are hopeful to generate positive and wide influence on people's health. They are able to provide flexible, affordable and portable health guides to device users. Current online decision-making methods for mHealth assume that the users are completely heterogeneous. They share no information among users and learn a separate policy for each user. However, data for each user is very limited in size to support the separate online learning, leading to unstable policies that contain lots of variances. Besides, we find the truth that a user may be similar with some, but not all, users, and connected users tend to have similar behaviors. In this paper, we propose a network cohesion constrained (actor-critic) Reinforcement Learning (RL) method for mHealth. The goal is to explore how to share information among similar users to better convert the limited user information into sharper learned policies. To the best of our knowledge, this is the first online actor-critic RL for mHealth and first network cohesion constrained (actor-critic) RL method in all applications. The network cohesion is important to derive effective policies. We come up with a novel method to learn the network by using the warm start trajectory, which directly reflects the users' property. The optimization of our model is difficult and very different from the general supervised learning due to the indirect observation of values. As a contribution, we propose two algorithms for the proposed online RLs. Apart from mHealth, the proposed methods can be easily applied or adapted to other health-related tasks. Extensive experiment results on the HeartSteps dataset demonstrates that in a variety of parameter settings, the proposed two methods obtain obvious improvements over the state-of-the-art methods.
Robust Contextual Bandit via the Capped-$\ell_{2}$ norm
Aug 17, 2017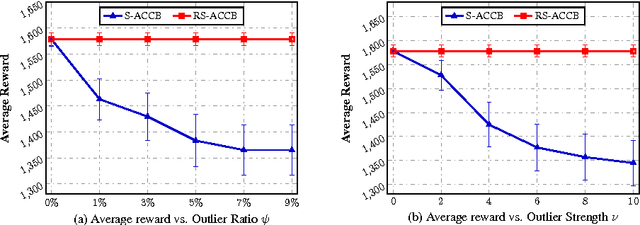
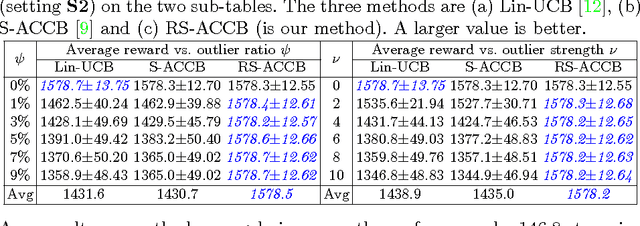
This paper considers the actor-critic contextual bandit for the mobile health (mHealth) intervention. The state-of-the-art decision-making methods in mHealth generally assume that the noise in the dynamic system follows the Gaussian distribution. Those methods use the least-square-based algorithm to estimate the expected reward, which is prone to the existence of outliers. To deal with the issue of outliers, we propose a novel robust actor-critic contextual bandit method for the mHealth intervention. In the critic updating, the capped-$\ell_{2}$ norm is used to measure the approximation error, which prevents outliers from dominating our objective. A set of weights could be achieved from the critic updating. Considering them gives a weighted objective for the actor updating. It provides the badly noised sample in the critic updating with zero weights for the actor updating. As a result, the robustness of both actor-critic updating is enhanced. There is a key parameter in the capped-$\ell_{2}$ norm. We provide a reliable method to properly set it by making use of one of the most fundamental definitions of outliers in statistics. Extensive experiment results demonstrate that our method can achieve almost identical results compared with the state-of-the-art methods on the dataset without outliers and dramatically outperform them on the datasets noised by outliers.
Group-driven Reinforcement Learning for Personalized mHealth Intervention
Aug 14, 2017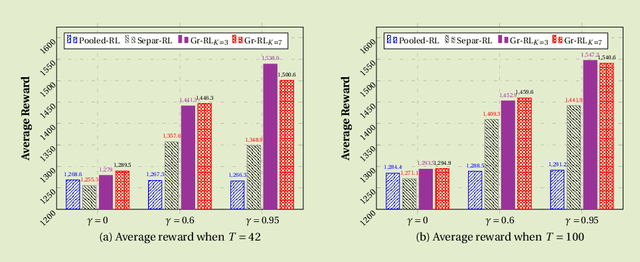
Due to the popularity of smartphones and wearable devices nowadays, mobile health (mHealth) technologies are promising to bring positive and wide impacts on people's health. State-of-the-art decision-making methods for mHealth rely on some ideal assumptions. Those methods either assume that the users are completely homogenous or completely heterogeneous. However, in reality, a user might be similar with some, but not all, users. In this paper, we propose a novel group-driven reinforcement learning method for the mHealth. We aim to understand how to share information among similar users to better convert the limited user information into sharper learned RL policies. Specifically, we employ the K-means clustering method to group users based on their trajectory information similarity and learn a shared RL policy for each group. Extensive experiment results have shown that our method can achieve clear gains over the state-of-the-art RL methods for mHealth.
Accurate Urban Road Centerline Extraction from VHR Imagery via Multiscale Segmentation and Tensor Voting
Feb 25, 2016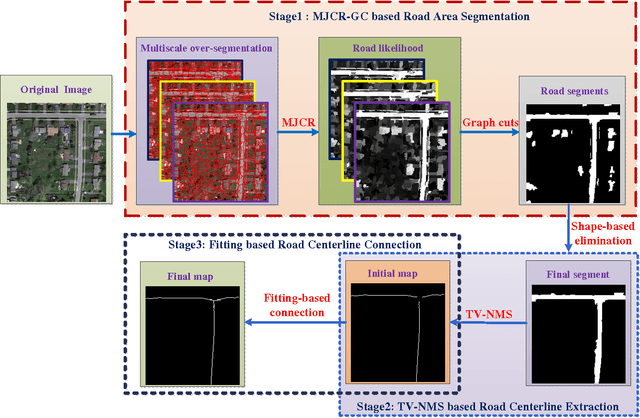
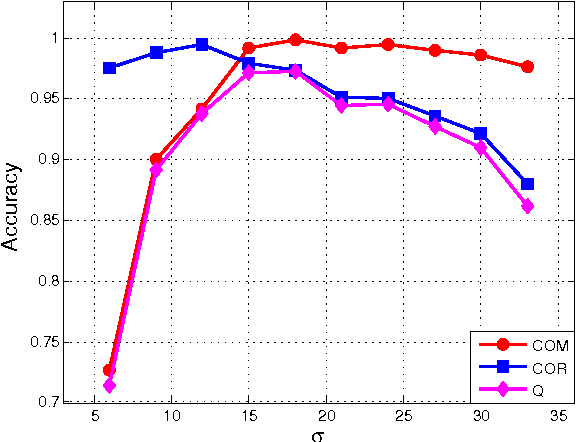
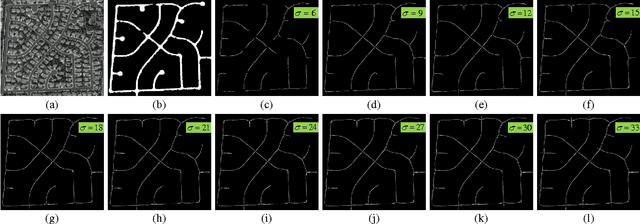
It is very useful and increasingly popular to extract accurate road centerlines from very-high-resolution (VHR) re- mote sensing imagery for various applications, such as road map generation and updating etc. There are three shortcomings of current methods: (a) Due to the noise and occlusions (owing to vehicles and trees), most road extraction methods bring in heterogeneous classification results; (b) Morphological thinning algorithm is widely used to extract road centerlines, while it pro- duces small spurs around the centerlines; (c) Many methods are ineffective to extract centerlines around the road intersections. To address the above three issues, we propose a novel method to ex- tract smooth and complete road centerlines via three techniques: the multiscale joint collaborative representation (MJCR) & graph cuts (GC), tensor voting (TV) & non-maximum suppression (NMS) and fitting based connection algorithm. Specifically, a MJCR-GC based road area segmentation method is proposed by incorporating mutiscale features and spatial information. In this way, a homogenous road segmentation result is achieved. Then, to obtain a smooth and correct road centerline network, a TV-NMS based centerline extraction method is introduced. This method not only extracts smooth road centerlines, but also connects the discontinuous road centerlines. Finally, to overcome the ineffectiveness of current methods in the road intersection, a fitting based road centerline connection algorithm is proposed. As a result, we can get a complete road centerline network. Extensive experiments on two datasets demonstrate that our method achieves higher quantitative results, as well as more satisfactory visual performances by comparing with state-of-the- art methods.
Spectral Unmixing via Data-guided Sparsity
Nov 17, 2014
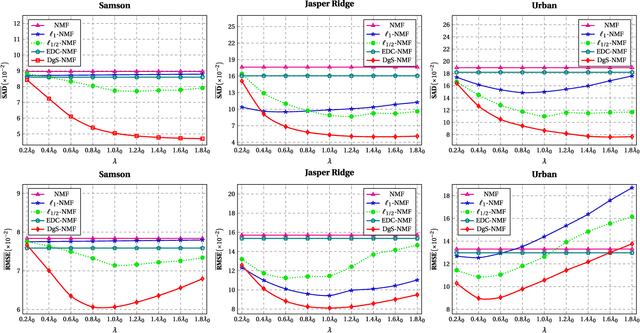
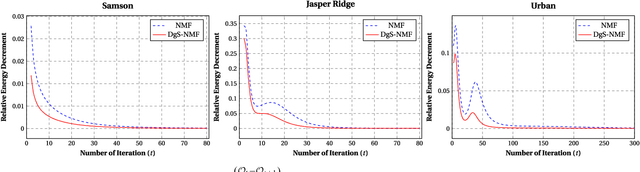
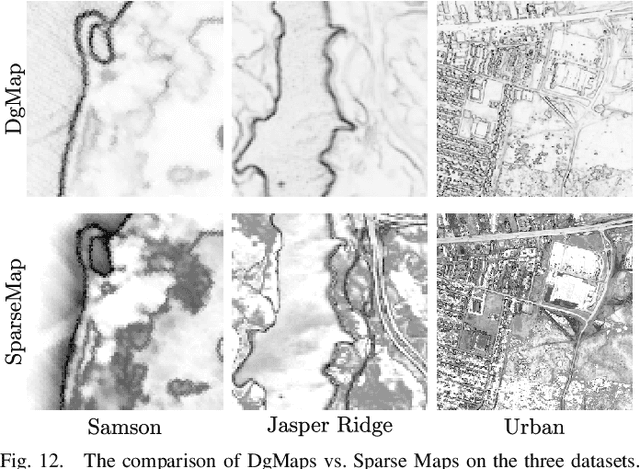
Hyperspectral unmixing, the process of estimating a common set of spectral bases and their corresponding composite percentages at each pixel, is an important task for hyperspectral analysis, visualization and understanding. From an unsupervised learning perspective, this problem is very challenging---both the spectral bases and their composite percentages are unknown, making the solution space too large. To reduce the solution space, many approaches have been proposed by exploiting various priors. In practice, these priors would easily lead to some unsuitable solution. This is because they are achieved by applying an identical strength of constraints to all the factors, which does not hold in practice. To overcome this limitation, we propose a novel sparsity based method by learning a data-guided map to describe the individual mixed level of each pixel. Through this data-guided map, the $\ell_{p}(0<p<1)$ constraint is applied in an adaptive manner. Such implementation not only meets the practical situation, but also guides the spectral bases toward the pixels under highly sparse constraint. What's more, an elegant optimization scheme as well as its convergence proof have been provided in this paper. Extensive experiments on several datasets also demonstrate that the data-guided map is feasible, and high quality unmixing results could be obtained by our method.
10,000+ Times Accelerated Robust Subset Selection (ARSS)
Nov 17, 2014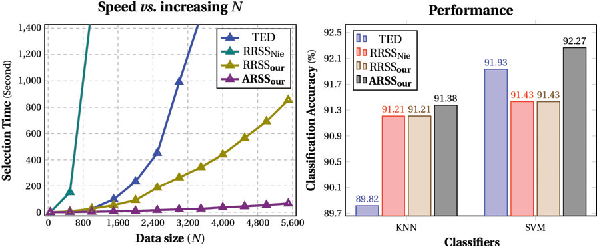

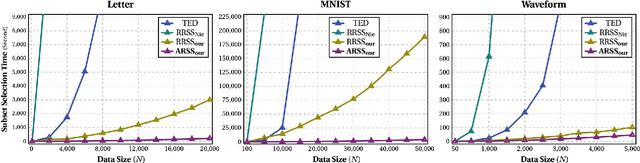

Subset selection from massive data with noised information is increasingly popular for various applications. This problem is still highly challenging as current methods are generally slow in speed and sensitive to outliers. To address the above two issues, we propose an accelerated robust subset selection (ARSS) method. Specifically in the subset selection area, this is the first attempt to employ the $\ell_{p}(0<p\leq1)$-norm based measure for the representation loss, preventing large errors from dominating our objective. As a result, the robustness against outlier elements is greatly enhanced. Actually, data size is generally much larger than feature length, i.e. $N\gg L$. Based on this observation, we propose a speedup solver (via ALM and equivalent derivations) to highly reduce the computational cost, theoretically from $O(N^{4})$ to $O(N{}^{2}L)$. Extensive experiments on ten benchmark datasets verify that our method not only outperforms state of the art methods, but also runs 10,000+ times faster than the most related method.