 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Entropy Regularization for Multi-modal Antenna Affiliation Identification
Jan 29, 2026Accurate antenna affiliation identification is crucial for optimizing and maintaining communication networks. Current practice, however, relies on the cumbersome and error-prone process of manual tower inspections. We propose a novel paradigm shift that fuses video footage of base stations, antenna geometric features, and Physical Cell Identity (PCI) signals, transforming antenna affiliation identification into multi-modal classification and matching tasks. Publicly available pretrained transformers struggle with this unique task due to a lack of analogous data in the communications domain, which hampers cross-modal alignment. To address this, we introduce a dedicated training framework that aligns antenna images with corresponding PCI signals. To tackle the representation alignment challenge, we propose a novel Token Entropy Regularization module in the pretraining stage. Our experiments demonstrate that TER accelerates convergence and yields significant performance gains. Further analysis reveals that the entropy of the first token is modality-dependent. Code will be made available upon publication.
FlowletFormer: Network Behavioral Semantic Aware Pre-training Model for Traffic Classification
Aug 27, 2025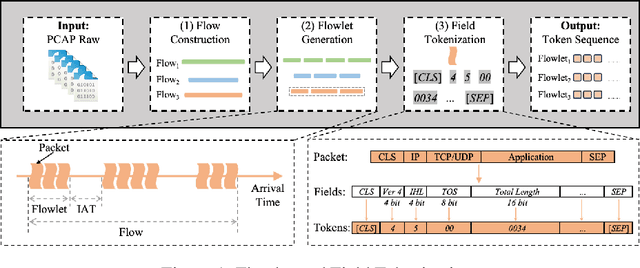
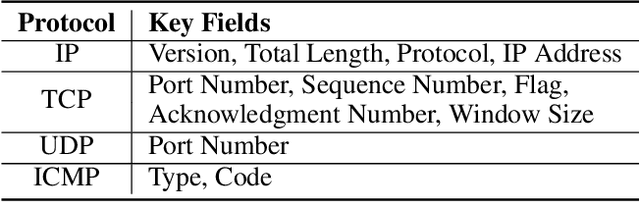
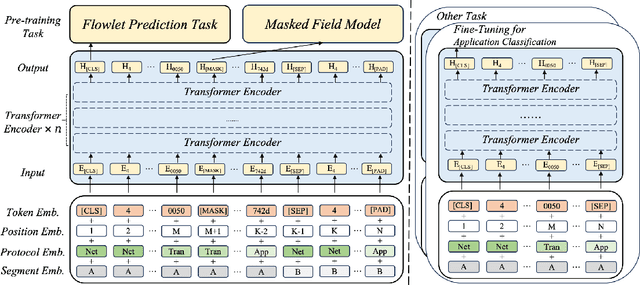
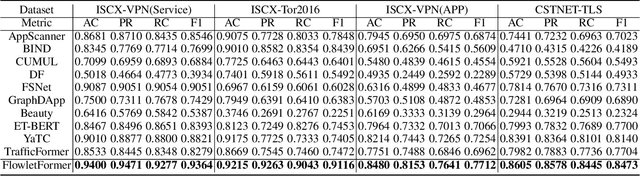
Network traffic classification using pre-training models has shown promising results, but existing methods struggle to capture packet structural characteristics, flow-level behaviors, hierarchical protocol semantics, and inter-packet contextual relationships. To address these challenges, we propose FlowletFormer, a BERT-based pre-training model specifically designed for network traffic analysis. FlowletFormer introduces a Coherent Behavior-Aware Traffic Representation Model for segmenting traffic into semantically meaningful units, a Protocol Stack Alignment-Based Embedding Layer to capture multilayer protocol semantics, and Field-Specific and Context-Aware Pretraining Tasks to enhance both inter-packet and inter-flow learning. Experimental results demonstrate that FlowletFormer significantly outperforms existing methods in the effectiveness of traffic representation, classification accuracy, and few-shot learning capability. Moreover, by effectively integrating domain-specific network knowledge, FlowletFormer shows better comprehension of the principles of network transmission (e.g., stateful connections of TCP), providing a more robust and trustworthy framework for traffic analysis.
Enabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance
Jul 23, 2025Large language model (LLM) agents often struggle in environments where rules and required domain knowledge frequently change, such as regulatory compliance and user risk screening. Current approaches, like offline fine-tuning and standard prompting, are insufficient because they cannot effectively adapt to new knowledge during actual operation. To address this limitation, we propose the Adaptive Reflective Interactive Agent (ARIA), an LLM agent framework designed specifically to continuously learn updated domain knowledge at test time. ARIA assesses its own uncertainty through structured self-dialogue, proactively identifying knowledge gaps and requesting targeted explanations or corrections from human experts. It then systematically updates an internal, timestamped knowledge repository with provided human guidance, detecting and resolving conflicting or outdated knowledge through comparisons and clarification queries. We evaluate ARIA on the realistic customer due diligence name screening task on TikTok Pay, alongside publicly available dynamic knowledge tasks. Results demonstrate significant improvements in adaptability and accuracy compared to baselines using standard offline fine-tuning and existing self-improving agents. ARIA is deployed within TikTok Pay serving over 150 million monthly active users, confirming its practicality and effectiveness for operational use in rapidly evolving environments.
WalnutData: A UAV Remote Sensing Dataset of Green Walnuts and Model Evaluation
Feb 27, 2025



The UAV technology is gradually maturing and can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Thus, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote-sensing data from 8 walnut sample plots. Considering that green walnuts are subject to various lighting conditions and occlusion, we constructed a large-scale dataset with a higher-granularity of target features - WalnutData. This dataset contains a total of 30,240 images and 706,208 instances, and there are 4 target categories: being illuminated by frontal light and unoccluded (A1), being backlit and unoccluded (A2), being illuminated by frontal light and occluded (B1), and being backlit and occluded (B2). Subsequently, we evaluated many mainstream algorithms on WalnutData and used these evaluation results as the baseline standard. The dataset and all evaluation results can be obtained at https://github.com/1wuming/WalnutData.
Dual-Flow: Transferable Multi-Target, Instance-Agnostic Attacks via In-the-wild Cascading Flow Optimization
Feb 05, 2025



Adversarial attacks are widely used to evaluate model robustness, and in black-box scenarios, the transferability of these attacks becomes crucial. Existing generator-based attacks have excellent generalization and transferability due to their instance-agnostic nature. However, when training generators for multi-target tasks, the success rate of transfer attacks is relatively low due to the limitations of the model's capacity. To address these challenges, we propose a novel Dual-Flow framework for multi-target instance-agnostic adversarial attacks, utilizing Cascading Distribution Shift Training to develop an adversarial velocity function. Extensive experiments demonstrate that Dual-Flow significantly improves transferability over previous multi-target generative attacks. For example, it increases the success rate from Inception-v3 to ResNet-152 by 34.58%. Furthermore, our attack method shows substantially stronger robustness against defense mechanisms, such as adversarially trained models.
Interactive Medical Image Segmentation: A Benchmark Dataset and Baseline
Nov 19, 2024Interactive Medical Image Segmentation (IMIS) has long been constrained by the limited availability of large-scale, diverse, and densely annotated datasets, which hinders model generalization and consistent evaluation across different models. In this paper, we introduce the IMed-361M benchmark dataset, a significant advancement in general IMIS research. First, we collect and standardize over 6.4 million medical images and their corresponding ground truth masks from multiple data sources. Then, leveraging the strong object recognition capabilities of a vision foundational model, we automatically generated dense interactive masks for each image and ensured their quality through rigorous quality control and granularity management. Unlike previous datasets, which are limited by specific modalities or sparse annotations, IMed-361M spans 14 modalities and 204 segmentation targets, totaling 361 million masks-an average of 56 masks per image. Finally, we developed an IMIS baseline network on this dataset that supports high-quality mask generation through interactive inputs, including clicks, bounding boxes, text prompts, and their combinations. We evaluate its performance on medical image segmentation tasks from multiple perspectives, demonstrating superior accuracy and scalability compared to existing interactive segmentation models. To facilitate research on foundational models in medical computer vision, we release the IMed-361M and model at https://github.com/uni-medical/IMIS-Bench.
Make Your Home Safe: Time-aware Unsupervised User Behavior Anomaly Detection in Smart Homes via Loss-guided Mask
Jun 18, 2024



Smart homes, powered by the Internet of Things, offer great convenience but also pose security concerns due to abnormal behaviors, such as improper operations of users and potential attacks from malicious attackers. Several behavior modeling methods have been proposed to identify abnormal behaviors and mitigate potential risks. However, their performance often falls short because they do not effectively learn less frequent behaviors, consider temporal context, or account for the impact of noise in human behaviors. In this paper, we propose SmartGuard, an autoencoder-based unsupervised user behavior anomaly detection framework. First, we design a Loss-guided Dynamic Mask Strategy (LDMS) to encourage the model to learn less frequent behaviors, which are often overlooked during learning. Second, we propose a Three-level Time-aware Position Embedding (TTPE) to incorporate temporal information into positional embedding to detect temporal context anomaly. Third, we propose a Noise-aware Weighted Reconstruction Loss (NWRL) that assigns different weights for routine behaviors and noise behaviors to mitigate the interference of noise behaviors during inference. Comprehensive experiments on three datasets with ten types of anomaly behaviors demonstrates that SmartGuard consistently outperforms state-of-the-art baselines and also offers highly interpretable results.
Multi-view Gait Recognition based on Siamese Vision Transformer
Oct 19, 2022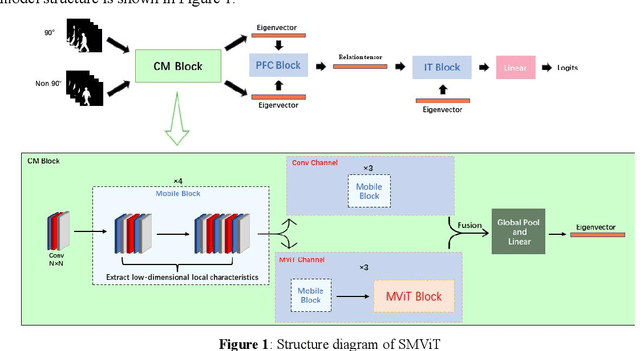
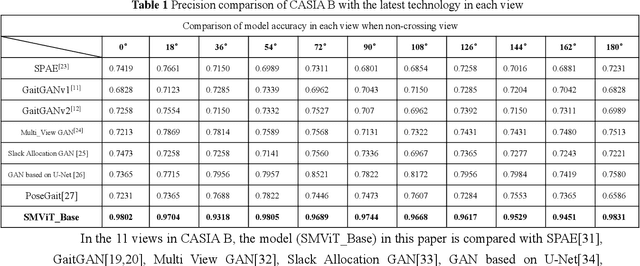
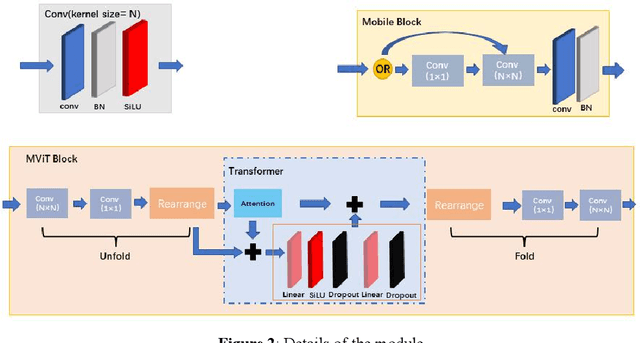

While the Vision Transformer has been used in gait recognition, its application in multi-view gait recognition is still limited. Different views significantly affect the extraction and identification accuracy of the characteristics of gait contour. To address this, this paper proposes a Siamese Mobile Vision Transformer (SMViT). This model not only focuses on the local characteristics of the human gait space but also considers the characteristics of long-distance attention associations, which can extract multi-dimensional step status characteristics. In addition, it describes how different perspectives affect gait characteristics and generate reliable perspective feature relationship factors. The average recognition rate of SMViT on the CASIA B data set reached 96.4%. The experimental results show that SMViT can attain state-of-the-art performance compared to advanced step recognition models such as GaitGAN, Multi_view GAN, Posegait and other gait recognition models.
KIT MOMA: A Mobile Machines Dataset
Jul 08, 2020
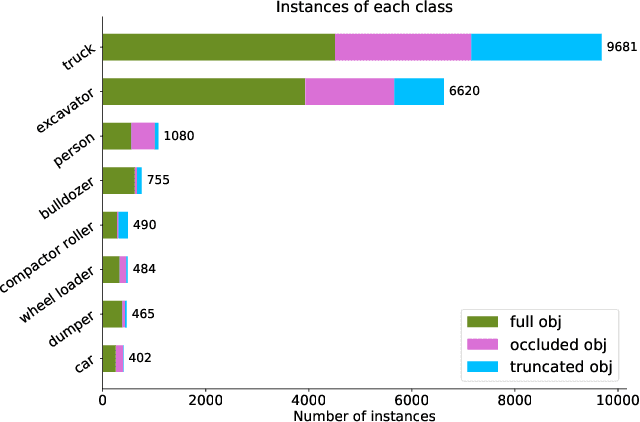


Mobile machines typically working in a closed site, have a high potential to utilize autonomous driving technology. However, vigorously thriving development and innovation are happening mostly in the area of passenger cars. In contrast, although there are also many research pieces about autonomous driving or working in mobile machines, a consensus about the SOTA solution is still not achieved. We believe that the most urgent problem that should be solved is the absence of a public and challenging visual dataset, which makes the results from different researches comparable. To address the problem, we publish the KIT MOMA dataset, including eight classes of commonly used mobile machines, which can be used as a benchmark to evaluate the SOTA algorithms to detect mobile construction machines. The view of the gathered images is outside of the mobile machines since we believe fixed cameras on the ground are more suitable if all the interesting machines are working in a closed site. Most of the images in KIT MOMA are in a real scene, whereas some of the images are from the official website of top construction machine companies. Also, we have evaluated the performance of YOLO v3 on our dataset, indicating that the SOTA computer vision algorithms already show an excellent performance for detecting the mobile machines in a specific working site. Together with the dataset, we also upload the trained weights, which can be directly used by engineers from the construction machine industry. The dataset, trained weights, and updates can be found on our Github. Moreover, the demo can be found on our Youtube.
MixPoet: Diverse Poetry Generation via Learning Controllable Mixed Latent Space
Mar 13, 2020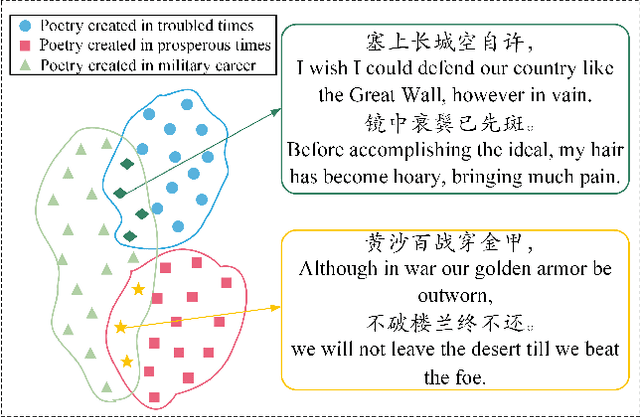
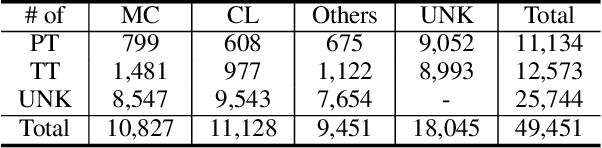
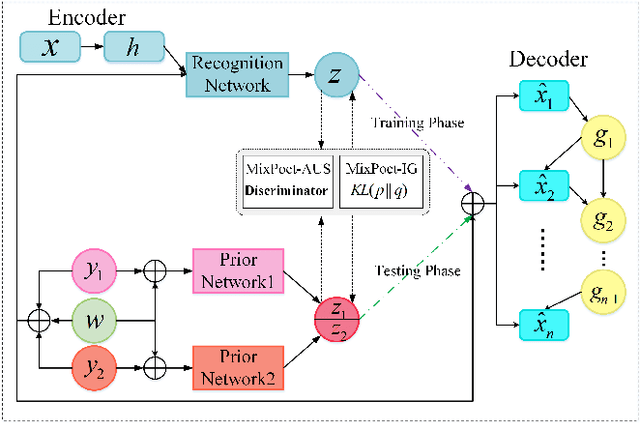
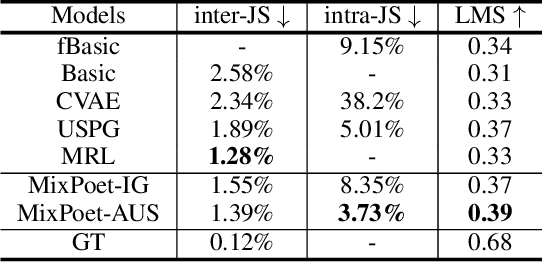
As an essential step towards computer creativity, automatic poetry generation has gained increasing attention these years. Though recent neural models make prominent progress in some criteria of poetry quality, generated poems still suffer from the problem of poor diversity. Related literature researches show that different factors, such as life experience, historical background, etc., would influence composition styles of poets, which considerably contributes to the high diversity of human-authored poetry. Inspired by this, we propose MixPoet, a novel model that absorbs multiple factors to create various styles and promote diversity. Based on a semi-supervised variational autoencoder, our model disentangles the latent space into some subspaces, with each conditioned on one influence factor by adversarial training. In this way, the model learns a controllable latent variable to capture and mix generalized factor-related properties. Different factor mixtures lead to diverse styles and hence further differentiate generated poems from each other. Experiment results on Chinese poetry demonstrate that MixPoet improves both diversity and quality against three state-of-the-art models.