 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightFormer: A lightweight and efficient decoder for remote sensing image segmentation
Apr 15, 2025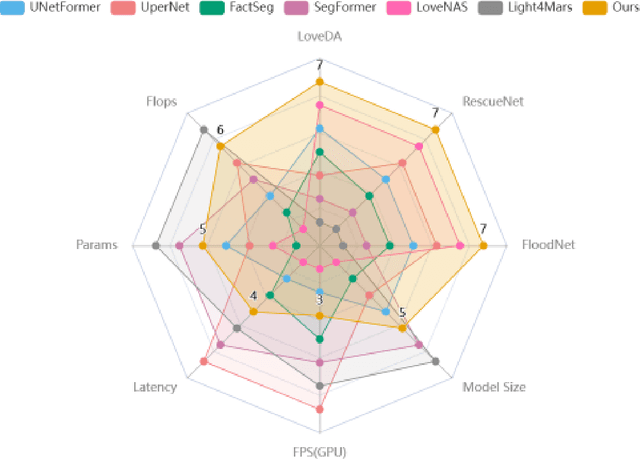

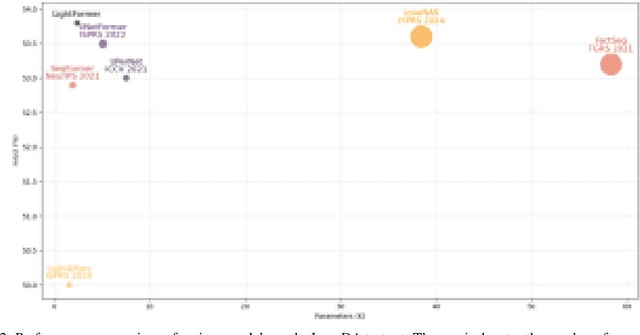

Deep learning techniques have achieved remarkable success in the semantic segmentation of remote sensing images and in land-use change detection. Nevertheless, their real-time deployment on edge platforms remains constrained by decoder complexity. Herein, we introduce LightFormer, a lightweight decoder for time-critical tasks that involve unstructured targets, such as disaster assessment, unmanned aerial vehicle search-and-rescue, and cultural heritage monitoring. LightFormer employs a feature-fusion and refinement module built on channel processing and a learnable gating mechanism to aggregate multi-scale, multi-range information efficiently, which drastically curtails model complexity. Furthermore, we propose a spatial information selection module (SISM) that integrates long-range attention with a detail preservation branch to capture spatial dependencies across multiple scales, thereby substantially improving the recognition of unstructured targets in complex scenes. On the ISPRS Vaihingen benchmark, LightFormer attains 99.9% of GLFFNet's mIoU (83.9% vs. 84.0%) while requiring only 14.7% of its FLOPs and 15.9% of its parameters, thus achieving an excellent accuracy-efficiency trade-off. Consistent results on LoveDA, ISPRS Potsdam, RescueNet, and FloodNet further demonstrate its robustness and superior perception of unstructured objects. These findings highlight LightFormer as a practical solution for remote sensing applications where both computational economy and high-precision segmentation are imperative.
WalnutData: A UAV Remote Sensing Dataset of Green Walnuts and Model Evaluation
Feb 27, 2025



The UAV technology is gradually maturing and can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Thus, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote-sensing data from 8 walnut sample plots. Considering that green walnuts are subject to various lighting conditions and occlusion, we constructed a large-scale dataset with a higher-granularity of target features - WalnutData. This dataset contains a total of 30,240 images and 706,208 instances, and there are 4 target categories: being illuminated by frontal light and unoccluded (A1), being backlit and unoccluded (A2), being illuminated by frontal light and occluded (B1), and being backlit and occluded (B2). Subsequently, we evaluated many mainstream algorithms on WalnutData and used these evaluation results as the baseline standard. The dataset and all evaluation results can be obtained at https://github.com/1wuming/WalnutData.
Multi-view Gait Recognition based on Siamese Vision Transformer
Oct 19, 2022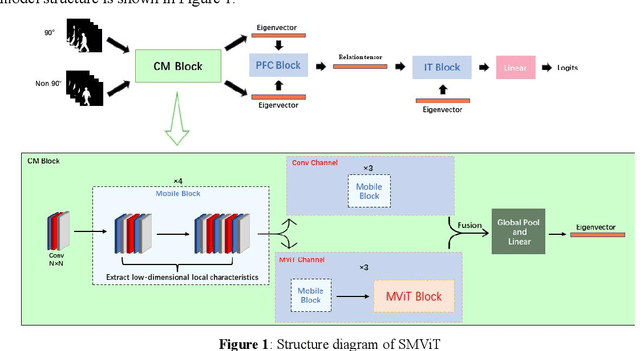
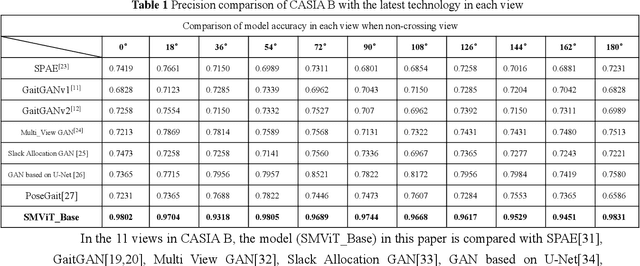
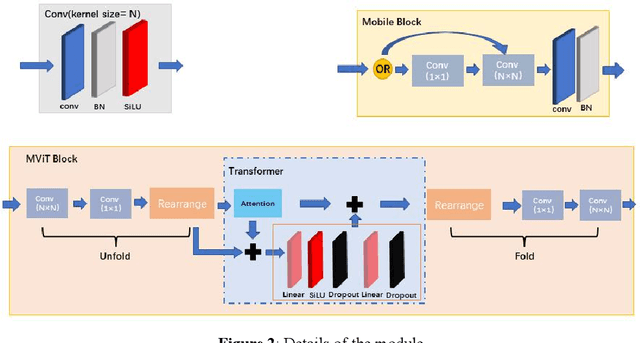

While the Vision Transformer has been used in gait recognition, its application in multi-view gait recognition is still limited. Different views significantly affect the extraction and identification accuracy of the characteristics of gait contour. To address this, this paper proposes a Siamese Mobile Vision Transformer (SMViT). This model not only focuses on the local characteristics of the human gait space but also considers the characteristics of long-distance attention associations, which can extract multi-dimensional step status characteristics. In addition, it describes how different perspectives affect gait characteristics and generate reliable perspective feature relationship factors. The average recognition rate of SMViT on the CASIA B data set reached 96.4%. The experimental results show that SMViT can attain state-of-the-art performance compared to advanced step recognition models such as GaitGAN, Multi_view GAN, Posegait and other gait recognition models.