 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneric Calibration: Pose Ambiguity/Linear Solution and Parametric-hybrid Pipeline
Aug 10, 2025Offline camera calibration techniques typically employ parametric or generic camera models. Selecting parametric models relies heavily on user experience, and an inappropriate camera model can significantly affect calibration accuracy. Meanwhile, generic calibration methods involve complex procedures and cannot provide traditional intrinsic parameters. This paper reveals a pose ambiguity in the pose solutions of generic calibration methods that irreversibly impacts subsequent pose estimation. A linear solver and a nonlinear optimization are proposed to address this ambiguity issue. Then a global optimization hybrid calibration method is introduced to integrate generic and parametric models together, which improves extrinsic parameter accuracy of generic calibration and mitigates overfitting and numerical instability in parametric calibration. Simulation and real-world experimental results demonstrate that the generic-parametric hybrid calibration method consistently excels across various lens types and noise contamination, hopefully serving as a reliable and accurate solution for camera calibration in complex scenarios.
WalnutData: A UAV Remote Sensing Dataset of Green Walnuts and Model Evaluation
Feb 27, 2025



The UAV technology is gradually maturing and can provide extremely powerful support for smart agriculture and precise monitoring. Currently, there is no dataset related to green walnuts in the field of agricultural computer vision. Thus, in order to promote the algorithm design in the field of agricultural computer vision, we used UAV to collect remote-sensing data from 8 walnut sample plots. Considering that green walnuts are subject to various lighting conditions and occlusion, we constructed a large-scale dataset with a higher-granularity of target features - WalnutData. This dataset contains a total of 30,240 images and 706,208 instances, and there are 4 target categories: being illuminated by frontal light and unoccluded (A1), being backlit and unoccluded (A2), being illuminated by frontal light and occluded (B1), and being backlit and occluded (B2). Subsequently, we evaluated many mainstream algorithms on WalnutData and used these evaluation results as the baseline standard. The dataset and all evaluation results can be obtained at https://github.com/1wuming/WalnutData.
Den-SOFT: Dense Space-Oriented Light Field DataseT for 6-DOF Immersive Experience
Mar 15, 2024



We have built a custom mobile multi-camera large-space dense light field capture system, which provides a series of high-quality and sufficiently dense light field images for various scenarios. Our aim is to contribute to the development of popular 3D scene reconstruction algorithms such as IBRnet, NeRF, and 3D Gaussian splitting. More importantly, the collected dataset, which is much denser than existing datasets, may also inspire space-oriented light field reconstruction, which is potentially different from object-centric 3D reconstruction, for immersive VR/AR experiences. We utilized a total of 40 GoPro 10 cameras, capturing images of 5k resolution. The number of photos captured for each scene is no less than 1000, and the average density (view number within a unit sphere) is 134.68. It is also worth noting that our system is capable of efficiently capturing large outdoor scenes. Addressing the current lack of large-space and dense light field datasets, we made efforts to include elements such as sky, reflections, lights and shadows that are of interest to researchers in the field of 3D reconstruction during the data capture process. Finally, we validated the effectiveness of our provided dataset on three popular algorithms and also integrated the reconstructed 3DGS results into the Unity engine, demonstrating the potential of utilizing our datasets to enhance the realism of virtual reality (VR) and create feasible interactive spaces. The dataset is available at our project website.
An Event-Oriented Diffusion-Refinement Method for Sparse Events Completion
Jan 06, 2024Event cameras or dynamic vision sensors (DVS) record asynchronous response to brightness changes instead of conventional intensity frames, and feature ultra-high sensitivity at low bandwidth. The new mechanism demonstrates great advantages in challenging scenarios with fast motion and large dynamic range. However, the recorded events might be highly sparse due to either limited hardware bandwidth or extreme photon starvation in harsh environments. To unlock the full potential of event cameras, we propose an inventive event sequence completion approach conforming to the unique characteristics of event data in both the processing stage and the output form. Specifically, we treat event streams as 3D event clouds in the spatiotemporal domain, develop a diffusion-based generative model to generate dense clouds in a coarse-to-fine manner, and recover exact timestamps to maintain the temporal resolution of raw data successfully. To validate the effectiveness of our method comprehensively, we perform extensive experiments on three widely used public datasets with different spatial resolutions, and additionally collect a novel event dataset covering diverse scenarios with highly dynamic motions and under harsh illumination. Besides generating high-quality dense events, our method can benefit downstream applications such as object classification and intensity frame reconstruction.
ImmersiveNeRF: Hybrid Radiance Fields for Unbounded Immersive Light Field Reconstruction
Sep 04, 2023This paper proposes a hybrid radiance field representation for unbounded immersive light field reconstruction which supports high-quality rendering and aggressive view extrapolation. The key idea is to first formally separate the foreground and the background and then adaptively balance learning of them during the training process. To fulfill this goal, we represent the foreground and background as two separate radiance fields with two different spatial mapping strategies. We further propose an adaptive sampling strategy and a segmentation regularizer for more clear segmentation and robust convergence. Finally, we contribute a novel immersive light field dataset, named THUImmersive, with the potential to achieve much larger space 6DoF immersive rendering effects compared with existing datasets, by capturing multiple neighboring viewpoints for the same scene, to stimulate the research and AR/VR applications in the immersive light field domain. Extensive experiments demonstrate the strong performance of our method for unbounded immersive light field reconstruction.
Super-NeRF: View-consistent Detail Generation for NeRF super-resolution
Apr 26, 2023



The neural radiance field (NeRF) achieved remarkable success in modeling 3D scenes and synthesizing high-fidelity novel views. However, existing NeRF-based methods focus more on the make full use of the image resolution to generate novel views, but less considering the generation of details under the limited input resolution. In analogy to the extensive usage of image super-resolution, NeRF super-resolution is an effective way to generate the high-resolution implicit representation of 3D scenes and holds great potential applications. Up to now, such an important topic is still under-explored. In this paper, we propose a NeRF super-resolution method, named Super-NeRF, to generate high-resolution NeRF from only low-resolution inputs. Given multi-view low-resolution images, Super-NeRF constructs a consistency-controlling super-resolution module to generate view-consistent high-resolution details for NeRF. Specifically, an optimizable latent code is introduced for each low-resolution input image to control the 2D super-resolution images to converge to the view-consistent output. The latent codes of each low-resolution image are optimized synergistically with the target Super-NeRF representation to fully utilize the view consistency constraint inherent in NeRF construction. We verify the effectiveness of Super-NeRF on synthetic, real-world, and AI-generated NeRF datasets. Super-NeRF achieves state-of-the-art NeRF super-resolution performance on high-resolution detail generation and cross-view consistency.
State-aware Anti-drift Robust Correlation Tracking
Jun 28, 2018

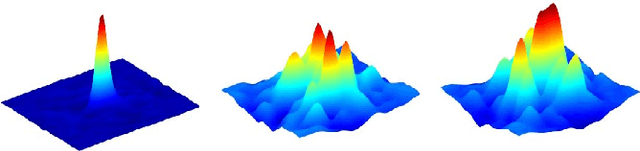
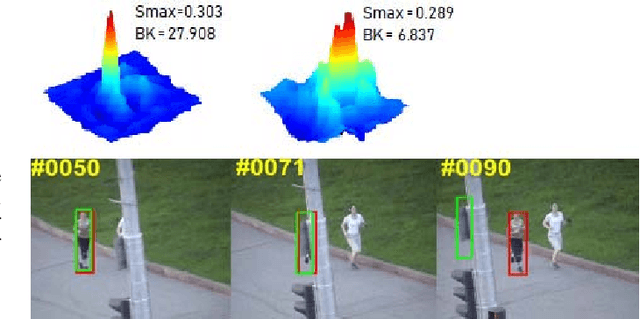
Correlation filter (CF) based trackers have aroused increasing attentions in visual tracking field due to the superior performance on several datasets while maintaining high running speed. For each frame, an ideal filter is trained in order to discriminate the target from its surrounding background. Considering that the target always undergoes external and internal interference during tracking procedure, the trained filter should take consideration of not only the external distractions but also the target appearance variation synchronously. To this end, we present a State-aware Anti-drift Tracker (SAT) in this paper, which jointly model the discrimination and reliability information in filter learning. Specifically, global context patches are incorporated into filter training stage to better distinguish the target from backgrounds. Meanwhile, a color-based reliable mask is learned to encourage the filter to focus on more reliable regions suitable for tracking. We show that the proposed optimization problem could be efficiently solved using Alternative Direction Method of Multipliers and fully carried out in Fourier domain. Extensive experiments are conducted on OTB-100 datasets to compare the SAT tracker (both hand-crafted feature and CNN feature) with other relevant state-of-the-art methods. Both quantitative and qualitative evaluations further demonstrate the effectiveness and robustness of the proposed work.
Correlation Tracking via Robust Region Proposals
Jun 14, 2018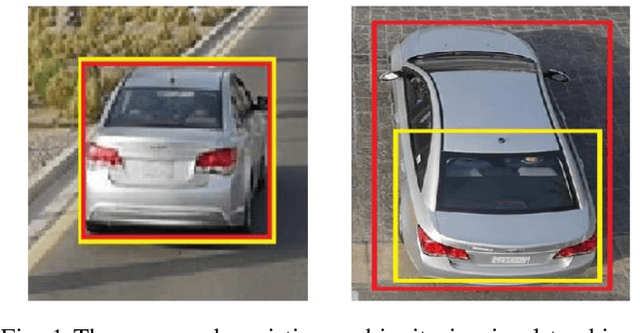
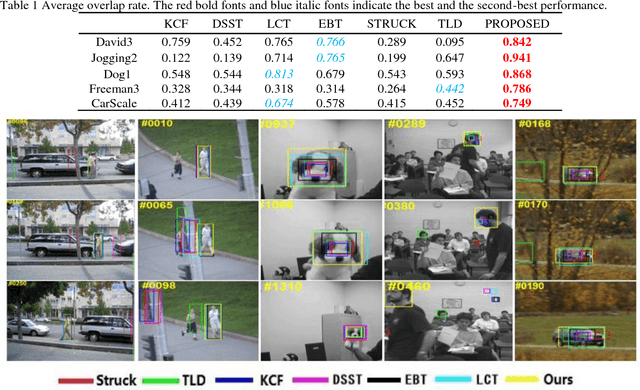
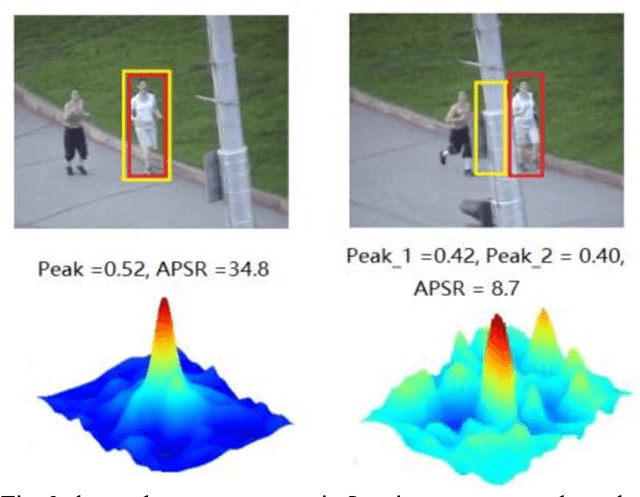
Recently, correlation filter-based trackers have received extensive attention due to their simplicity and superior speed. However, such trackers perform poorly when the target undergoes occlusion, viewpoint change or other challenging attributes due to pre-defined sampling strategy. To tackle these issues, in this paper, we propose an adaptive region proposal scheme to facilitate visual tracking. To be more specific, a novel tracking monitoring indicator is advocated to forecast tracking failure. Afterwards, we incorporate detection and scale proposals respectively, to recover from model drift as well as handle aspect ratio variation. We test the proposed algorithm on several challenging sequences, which have demonstrated that the proposed tracker performs favourably against state-of-the-art trackers.
Adaptive Feature Representation for Visual Tracking
May 12, 2017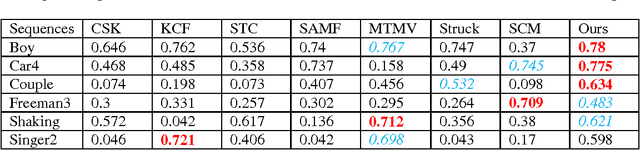
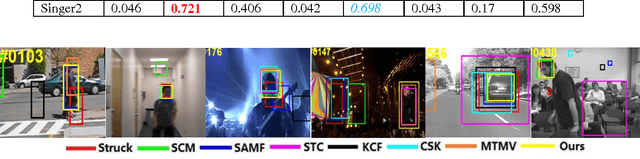
Robust feature representation plays significant role in visual tracking. However, it remains a challenging issue, since many factors may affect the experimental performance. The existing method which combine different features by setting them equally with the fixed weight could hardly solve the issues, due to the different statistical properties of different features across various of scenarios and attributes. In this paper, by exploiting the internal relationship among these features, we develop a robust method to construct a more stable feature representation. More specifically, we utilize a co-training paradigm to formulate the intrinsic complementary information of multi-feature template into the efficient correlation filter framework. We test our approach on challenging se- quences with illumination variation, scale variation, deformation etc. Experimental results demonstrate that the proposed method outperforms state-of-the-art methods favorably.