 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightFormer: A lightweight and efficient decoder for remote sensing image segmentation
Paper and Code
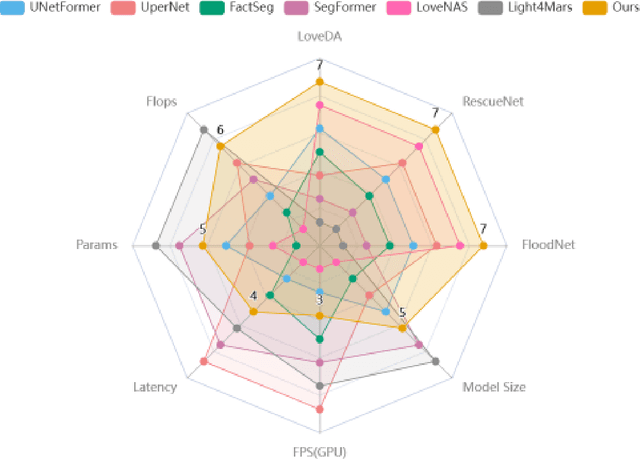

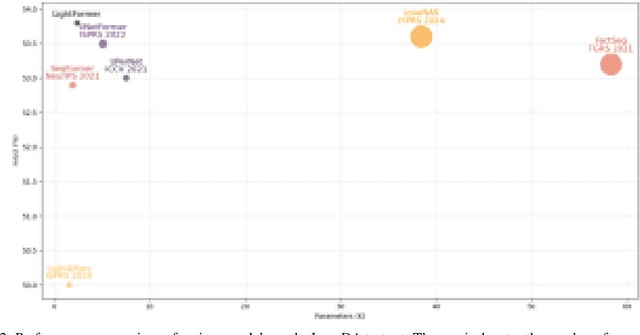

Deep learning techniques have achieved remarkable success in the semantic segmentation of remote sensing images and in land-use change detection. Nevertheless, their real-time deployment on edge platforms remains constrained by decoder complexity. Herein, we introduce LightFormer, a lightweight decoder for time-critical tasks that involve unstructured targets, such as disaster assessment, unmanned aerial vehicle search-and-rescue, and cultural heritage monitoring. LightFormer employs a feature-fusion and refinement module built on channel processing and a learnable gating mechanism to aggregate multi-scale, multi-range information efficiently, which drastically curtails model complexity. Furthermore, we propose a spatial information selection module (SISM) that integrates long-range attention with a detail preservation branch to capture spatial dependencies across multiple scales, thereby substantially improving the recognition of unstructured targets in complex scenes. On the ISPRS Vaihingen benchmark, LightFormer attains 99.9% of GLFFNet's mIoU (83.9% vs. 84.0%) while requiring only 14.7% of its FLOPs and 15.9% of its parameters, thus achieving an excellent accuracy-efficiency trade-off. Consistent results on LoveDA, ISPRS Potsdam, RescueNet, and FloodNet further demonstrate its robustness and superior perception of unstructured objects. These findings highlight LightFormer as a practical solution for remote sensing applications where both computational economy and high-precision segmentation are imperative.