 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-Expert: Towards Expert-Level Geological Reasoning via Parameter-Efficient Fine-Tuning
May 24, 2026While general-purpose Large Language Models (LLMs) applied to Geology often hallucinate when reasoning about subsurface structures and deep-time evolution, current AI in Earth sciences predominantly targets surface remote sensing and GIS. To bridge this gap, we introduce Geo-Expert, a family of parameter-efficient geological LLMs fine-tuned on a custom-curated, high-quality instruction dataset processed using our custom instruction synthesis pipeline. We investigate the impact of model scaling and architecture by fine-tuning three base models: Qwen3-8B, Qwen3-32B, and Gemma-3-27B, with Low-Rank Adaptation (LoRA) method. Our extensive evaluation on a novel domain-specific benchmark, Geo-Eval, reveals that a domain-aligned 8B model can outperform open-weight 70B generalists and proprietary GPT-4o on specialized geological reasoning, while a 32B variant approaches frontier reasoning models. The optimized 8B model further offers a competitive cost-performance ratio for deployment. This work provides a reproducible recipe for democratizing scientific LLMs and establishes a baseline for geological artificial intelligence.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
LightFormer: A lightweight and efficient decoder for remote sensing image segmentation
Apr 15, 2025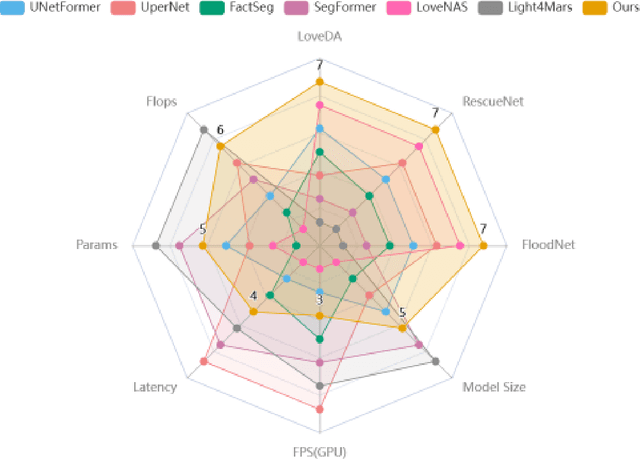

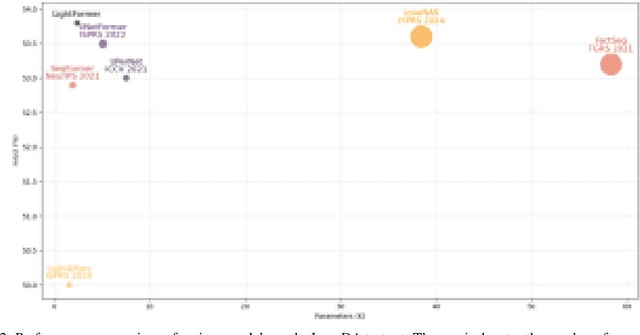

Deep learning techniques have achieved remarkable success in the semantic segmentation of remote sensing images and in land-use change detection. Nevertheless, their real-time deployment on edge platforms remains constrained by decoder complexity. Herein, we introduce LightFormer, a lightweight decoder for time-critical tasks that involve unstructured targets, such as disaster assessment, unmanned aerial vehicle search-and-rescue, and cultural heritage monitoring. LightFormer employs a feature-fusion and refinement module built on channel processing and a learnable gating mechanism to aggregate multi-scale, multi-range information efficiently, which drastically curtails model complexity. Furthermore, we propose a spatial information selection module (SISM) that integrates long-range attention with a detail preservation branch to capture spatial dependencies across multiple scales, thereby substantially improving the recognition of unstructured targets in complex scenes. On the ISPRS Vaihingen benchmark, LightFormer attains 99.9% of GLFFNet's mIoU (83.9% vs. 84.0%) while requiring only 14.7% of its FLOPs and 15.9% of its parameters, thus achieving an excellent accuracy-efficiency trade-off. Consistent results on LoveDA, ISPRS Potsdam, RescueNet, and FloodNet further demonstrate its robustness and superior perception of unstructured objects. These findings highlight LightFormer as a practical solution for remote sensing applications where both computational economy and high-precision segmentation are imperative.
Any Information Is Just Worth One Single Screenshot: Unifying Search With Visualized Information Retrieval
Feb 17, 2025With the popularity of multimodal techniques, it receives growing interests to acquire useful information in visual forms. In this work, we formally define an emerging IR paradigm called \textit{Visualized Information Retrieval}, or \textbf{Vis-IR}, where multimodal information, such as texts, images, tables and charts, is jointly represented by a unified visual format called \textbf{Screenshots}, for various retrieval applications. We further make three key contributions for Vis-IR. First, we create \textbf{VIRA} (Vis-IR Aggregation), a large-scale dataset comprising a vast collection of screenshots from diverse sources, carefully curated into captioned and question-answer formats. Second, we develop \textbf{UniSE} (Universal Screenshot Embeddings), a family of retrieval models that enable screenshots to query or be queried across arbitrary data modalities. Finally, we construct \textbf{MVRB} (Massive Visualized IR Benchmark), a comprehensive benchmark covering a variety of task forms and application scenarios. Through extensive evaluations on MVRB, we highlight the deficiency from existing multimodal retrievers and the substantial improvements made by UniSE. Our work will be shared with the community, laying a solid foundation for this emerging field.
MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
Dec 19, 2024Despite the rapidly growing demand for multimodal retrieval, progress in this field remains severely constrained by a lack of training data. In this paper, we introduce MegaPairs, a novel data synthesis method that leverages vision language models (VLMs) and open-domain images, together with a massive synthetic dataset generated from this method. Our empirical analysis shows that MegaPairs generates high-quality data, enabling the multimodal retriever to significantly outperform the baseline model trained on 70$\times$ more data from existing datasets. Moreover, since MegaPairs solely relies on general image corpora and open-source VLMs, it can be easily scaled up, enabling continuous improvements in retrieval performance. In this stage, we produced more than 26 million training instances and trained several models of varying sizes using this data. These new models achieve state-of-the-art zero-shot performance across 4 popular composed image retrieval (CIR) benchmarks and the highest overall performance on the 36 datasets provided by MMEB. They also demonstrate notable performance improvements with additional downstream fine-tuning. Our produced dataset, well-trained models, and data synthesis pipeline will be made publicly available to facilitate the future development of this field.
Deep Tree-based Retrieval for Efficient Recommendation: Theory and Method
Aug 21, 2024



With the development of deep learning techniques, deep recommendation models also achieve remarkable improvements in terms of recommendation accuracy. However, due to the large number of candidate items in practice and the high cost of preference computation, these methods also suffer from low efficiency of recommendation. The recently proposed tree-based deep recommendation models alleviate the problem by directly learning tree structure and representations under the guidance of recommendation objectives. However, such models have shortcomings. The max-heap assumption in the hierarchical tree, in which the preference for a parent node should be the maximum between the preferences for its children, is difficult to satisfy in their binary classification objectives. To this end, we propose Tree-based Deep Retrieval (TDR for short) for efficient recommendation. In TDR, all the trees generated during the training process are retained to form the forest. When learning the node representation of each tree, we have to satisfy the max-heap assumption as much as possible and mimic beam search behavior over the tree in the training stage. This is achieved by TDR to regard the training task as multi-classification over tree nodes at the same level. However, the number of tree nodes grows exponentially with levels, making us train the preference model with the guidance of the sampled-softmax technique. The experiments are conducted on real-world datasets, validating the effectiveness of the proposed preference model learning method and tree learning method.
F5C-finder: An Explainable and Ensemble Biological Language Model for Predicting 5-Formylcytidine Modifications on mRNA
Apr 20, 2024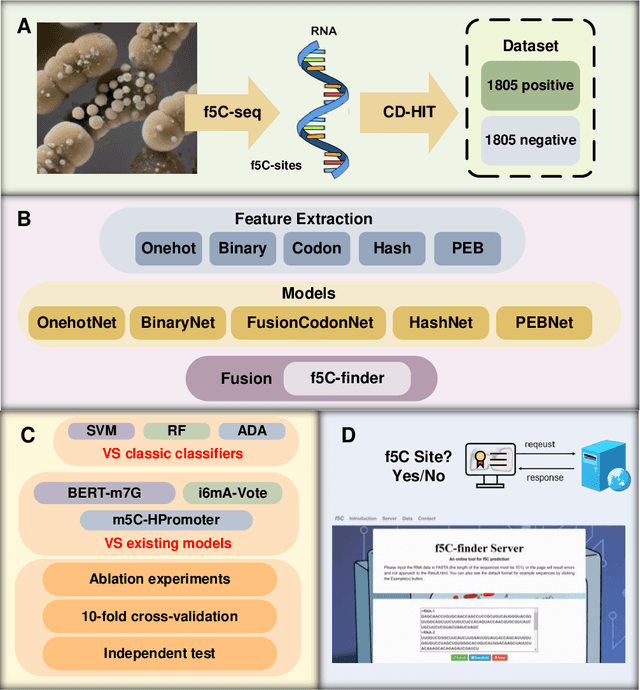
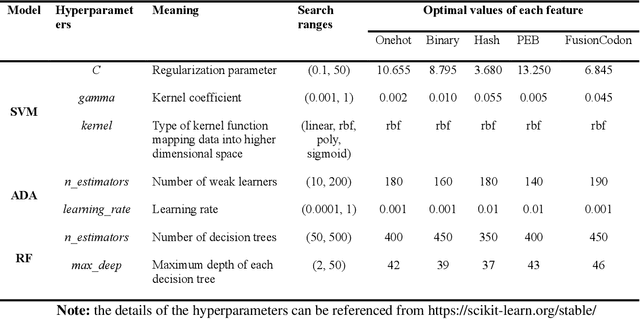

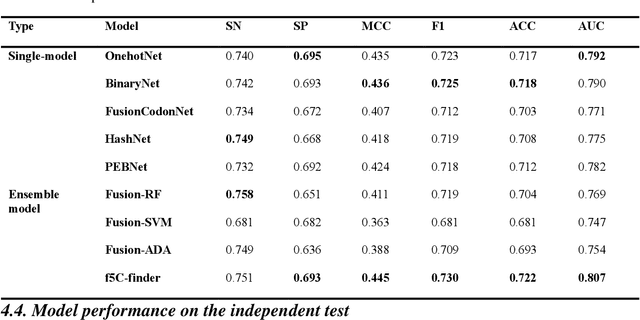
As a prevalent and dynamically regulated epigenetic modification, 5-formylcytidine (f5C) is crucial in various biological processes. However, traditional experimental methods for f5C detection are often laborious and time-consuming, limiting their ability to map f5C sites across the transcriptome comprehensively. While computational approaches offer a cost-effective and high-throughput alternative, no recognition model for f5C has been developed to date. Drawing inspiration from language models in natural language processing, this study presents f5C-finder, an ensemble neural network-based model utilizing multi-head attention for the identification of f5C. Five distinct feature extraction methods were employed to construct five individual artificial neural networks, and these networks were subsequently integrated through ensemble learning to create f5C-finder. 10-fold cross-validation and independent tests demonstrate that f5C-finder achieves state-of-the-art (SOTA) performance with AUC of 0.807 and 0.827, respectively. The result highlights the effectiveness of biological language model in capturing both the order (sequential) and functional meaning (semantics) within genomes. Furthermore, the built-in interpretability allows us to understand what the model is learning, creating a bridge between identifying key sequential elements and a deeper exploration of their biological functions.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
Comparative Analysis of Transfer Learning in Deep Learning Text-to-Speech Models on a Few-Shot, Low-Resource, Customized Dataset
Oct 08, 2023



Text-to-Speech (TTS) synthesis using deep learning relies on voice quality. Modern TTS models are advanced, but they need large amount of data. Given the growing computational complexity of these models and the scarcity of large, high-quality datasets, this research focuses on transfer learning, especially on few-shot, low-resource, and customized datasets. In this research, "low-resource" specifically refers to situations where there are limited amounts of training data, such as a small number of audio recordings and corresponding transcriptions for a particular language or dialect. This thesis, is rooted in the pressing need to find TTS models that require less training time, fewer data samples, yet yield high-quality voice output. The research evaluates TTS state-of-the-art model transfer learning capabilities through a thorough technical analysis. It then conducts a hands-on experimental analysis to compare models' performance in a constrained dataset. This study investigates the efficacy of modern TTS systems with transfer learning on specialized datasets and a model that balances training efficiency and synthesis quality. Initial hypotheses suggest that transfer learning could significantly improve TTS models' performance on compact datasets, and an optimal model may exist for such unique conditions. This thesis predicts a rise in transfer learning in TTS as data scarcity increases. In the future, custom TTS applications will favour models optimized for specific datasets over generic, data-intensive ones.
V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection
Aug 08, 2023



We introduce a highly performant 3D object detector for point clouds using the DETR framework. The prior attempts all end up with suboptimal results because they fail to learn accurate inductive biases from the limited scale of training data. In particular, the queries often attend to points that are far away from the target objects, violating the locality principle in object detection. To address the limitation, we introduce a novel 3D Vertex Relative Position Encoding (3DV-RPE) method which computes position encoding for each point based on its relative position to the 3D boxes predicted by the queries in each decoder layer, thus providing clear information to guide the model to focus on points near the objects, in accordance with the principle of locality. In addition, we systematically improve the pipeline from various aspects such as data normalization based on our understanding of the task. We show exceptional results on the challenging ScanNetV2 benchmark, achieving significant improvements over the previous 3DETR in $\rm{AP}_{25}$/$\rm{AP}_{50}$ from 65.0\%/47.0\% to 77.8\%/66.0\%, respectively. In addition, our method sets a new record on ScanNetV2 and SUN RGB-D datasets.Code will be released at http://github.com/yichaoshen-MS/V-DETR.