 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF5C-finder: An Explainable and Ensemble Biological Language Model for Predicting 5-Formylcytidine Modifications on mRNA
Paper and Code
Apr 20, 2024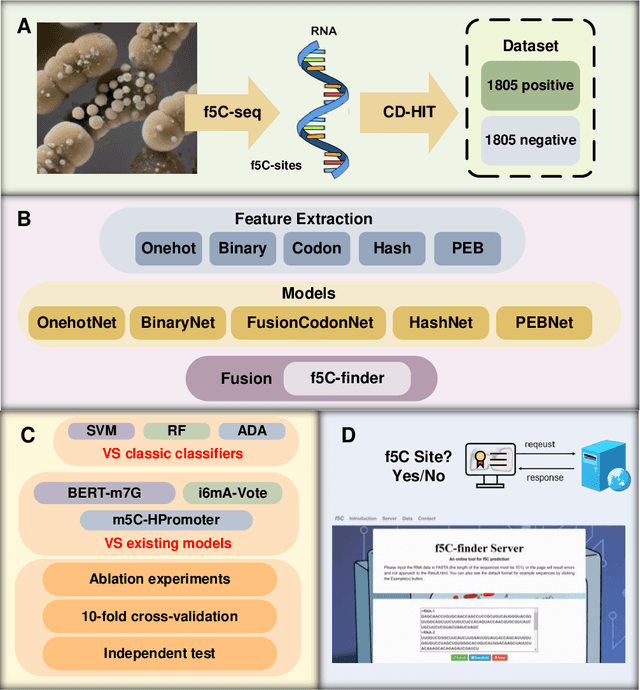
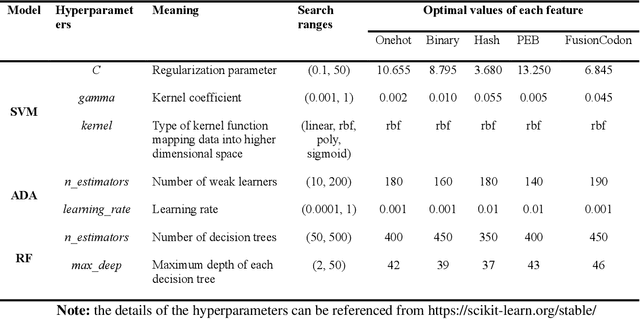

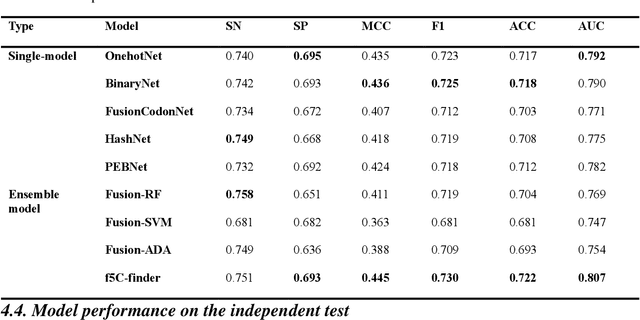
As a prevalent and dynamically regulated epigenetic modification, 5-formylcytidine (f5C) is crucial in various biological processes. However, traditional experimental methods for f5C detection are often laborious and time-consuming, limiting their ability to map f5C sites across the transcriptome comprehensively. While computational approaches offer a cost-effective and high-throughput alternative, no recognition model for f5C has been developed to date. Drawing inspiration from language models in natural language processing, this study presents f5C-finder, an ensemble neural network-based model utilizing multi-head attention for the identification of f5C. Five distinct feature extraction methods were employed to construct five individual artificial neural networks, and these networks were subsequently integrated through ensemble learning to create f5C-finder. 10-fold cross-validation and independent tests demonstrate that f5C-finder achieves state-of-the-art (SOTA) performance with AUC of 0.807 and 0.827, respectively. The result highlights the effectiveness of biological language model in capturing both the order (sequential) and functional meaning (semantics) within genomes. Furthermore, the built-in interpretability allows us to understand what the model is learning, creating a bridge between identifying key sequential elements and a deeper exploration of their biological functions.