 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolarSAM: Building-scale Photovoltaic Potential Assessment Based on Segment Anything Model (SAM) and Remote Sensing for Emerging City
Jun 29, 2024Driven by advancements in photovoltaic (PV) technology, solar energy has emerged as a promising renewable energy source, due to its ease of integration onto building rooftops, facades, and windows. For the emerging cities, the lack of detailed street-level data presents a challenge for effectively assessing the potential of building-integrated photovoltaic (BIPV). To address this, this study introduces SolarSAM, a novel BIPV evaluation method that leverages remote sensing imagery and deep learning techniques, and an emerging city in northern China is utilized to validate the model performance. During the process, SolarSAM segmented various building rooftops using text prompt guided semantic segmentation. Separate PV models were then developed for Rooftop PV, Facade-integrated PV, and PV windows systems, using this segmented data and local climate information. The potential for BIPV installation, solar power generation, and city-wide power self-sufficiency were assessed, revealing that the annual BIPV power generation potential surpassed the city's total electricity consumption by a factor of 2.5. Economic and environmental analysis were also conducted, including levelized cost of electricity and carbon reduction calculations, comparing different BIPV systems across various building categories. These findings demonstrated the model's performance and reveled the potential of BIPV power generation in the future.
F5C-finder: An Explainable and Ensemble Biological Language Model for Predicting 5-Formylcytidine Modifications on mRNA
Apr 20, 2024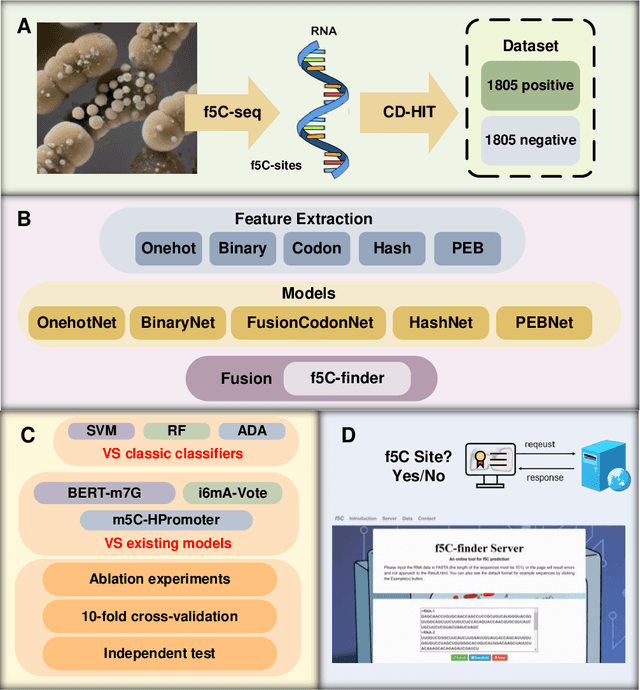
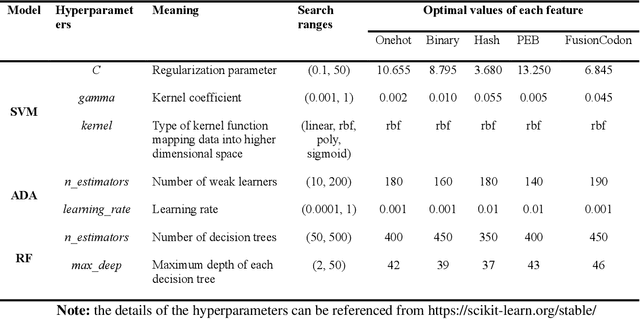

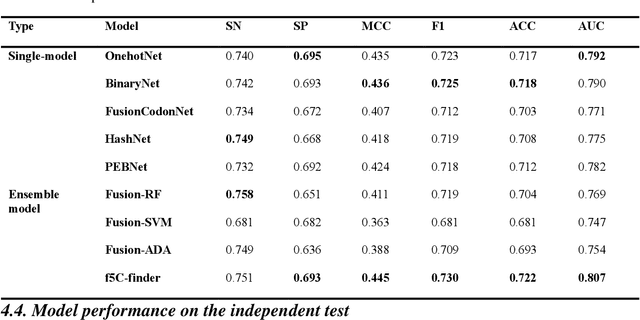
As a prevalent and dynamically regulated epigenetic modification, 5-formylcytidine (f5C) is crucial in various biological processes. However, traditional experimental methods for f5C detection are often laborious and time-consuming, limiting their ability to map f5C sites across the transcriptome comprehensively. While computational approaches offer a cost-effective and high-throughput alternative, no recognition model for f5C has been developed to date. Drawing inspiration from language models in natural language processing, this study presents f5C-finder, an ensemble neural network-based model utilizing multi-head attention for the identification of f5C. Five distinct feature extraction methods were employed to construct five individual artificial neural networks, and these networks were subsequently integrated through ensemble learning to create f5C-finder. 10-fold cross-validation and independent tests demonstrate that f5C-finder achieves state-of-the-art (SOTA) performance with AUC of 0.807 and 0.827, respectively. The result highlights the effectiveness of biological language model in capturing both the order (sequential) and functional meaning (semantics) within genomes. Furthermore, the built-in interpretability allows us to understand what the model is learning, creating a bridge between identifying key sequential elements and a deeper exploration of their biological functions.
Disentangled Generation Network for Enlarged License Plate Recognition and A Unified Dataset
Jun 02, 2022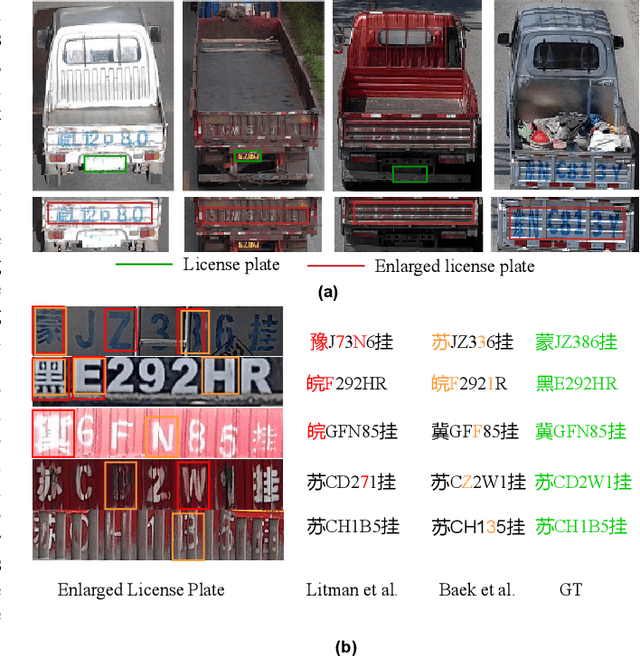
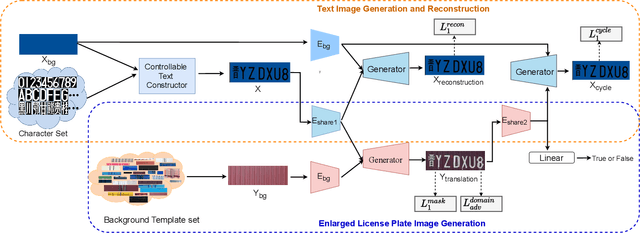


License plate recognition plays a critical role in many practical applications, but license plates of large vehicles are difficult to be recognized due to the factors of low resolution, contamination, low illumination, and occlusion, to name a few. To overcome the above factors, the transportation management department generally introduces the enlarged license plate behind the rear of a vehicle. However, enlarged license plates have high diversity as they are non-standard in position, size, and style. Furthermore, the background regions contain a variety of noisy information which greatly disturbs the recognition of license plate characters. Existing works have not studied this challenging problem. In this work, we first address the enlarged license plate recognition problem and contribute a dataset containing 9342 images, which cover most of the challenges of real scenes. However, the created data are still insufficient to train deep methods of enlarged license plate recognition, and building large-scale training data is very time-consuming and high labor cost. To handle this problem, we propose a novel task-level disentanglement generation framework based on the Disentangled Generation Network (DGNet), which disentangles the generation into the text generation and background generation in an end-to-end manner to effectively ensure diversity and integrity, for robust enlarged license plate recognition. Extensive experiments on the created dataset are conducted, and we demonstrate the effectiveness of the proposed approach in three representative text recognition frameworks.