 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Exploration All You Need? Effective Exploration Characteristics for Transfer in Reinforcement Learning
Apr 02, 2024



In deep reinforcement learning (RL) research, there has been a concerted effort to design more efficient and productive exploration methods while solving sparse-reward problems. These exploration methods often share common principles (e.g., improving diversity) and implementation details (e.g., intrinsic reward). Prior work found that non-stationary Markov decision processes (MDPs) require exploration to efficiently adapt to changes in the environment with online transfer learning. However, the relationship between specific exploration characteristics and effective transfer learning in deep RL has not been characterized. In this work, we seek to understand the relationships between salient exploration characteristics and improved performance and efficiency in transfer learning. We test eleven popular exploration algorithms on a variety of transfer types -- or ``novelties'' -- to identify the characteristics that positively affect online transfer learning. Our analysis shows that some characteristics correlate with improved performance and efficiency across a wide range of transfer tasks, while others only improve transfer performance with respect to specific environment changes. From our analysis, make recommendations about which exploration algorithm characteristics are best suited to specific transfer situations.
Multi-query Vehicle Re-identification: Viewpoint-conditioned Network, Unified Dataset and New Metric
May 25, 2023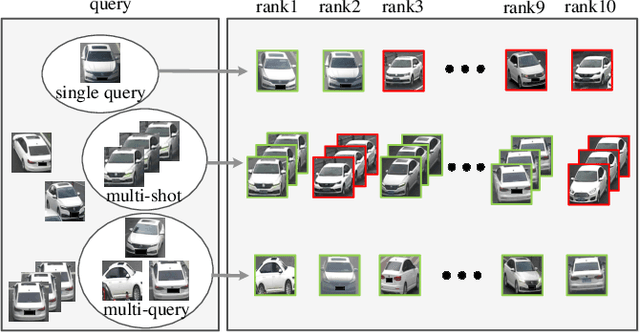
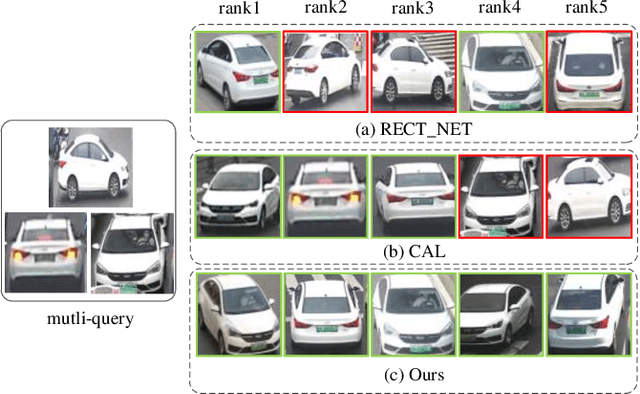
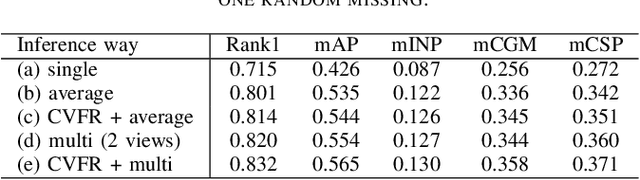
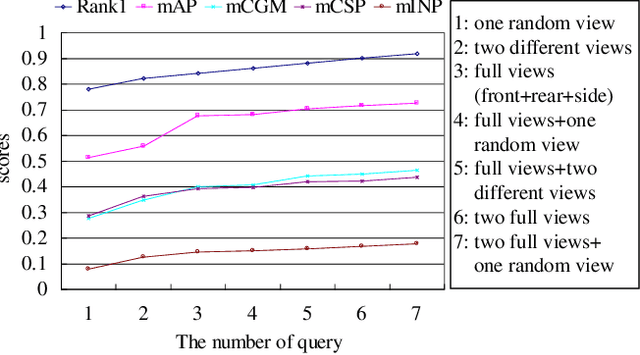
Existing vehicle re-identification methods mainly rely on the single query, which has limited information for vehicle representation and thus significantly hinders the performance of vehicle Re-ID in complicated surveillance networks. In this paper, we propose a more realistic and easily accessible task, called multi-query vehicle Re-ID, which leverages multiple queries to overcome viewpoint limitation of single one. Based on this task, we make three major contributions. First, we design a novel viewpoint-conditioned network (VCNet), which adaptively combines the complementary information from different vehicle viewpoints, for multi-query vehicle Re-ID. Moreover, to deal with the problem of missing vehicle viewpoints, we propose a cross-view feature recovery module which recovers the features of the missing viewpoints by learnt the correlation between the features of available and missing viewpoints. Second, we create a unified benchmark dataset, taken by 6142 cameras from a real-life transportation surveillance system, with comprehensive viewpoints and large number of crossed scenes of each vehicle for multi-query vehicle Re-ID evaluation. Finally, we design a new evaluation metric, called mean cross-scene precision (mCSP), which measures the ability of cross-scene recognition by suppressing the positive samples with similar viewpoints from same camera. Comprehensive experiments validate the superiority of the proposed method against other methods, as well as the effectiveness of the designed metric in the evaluation of multi-query vehicle Re-ID.
Disentangled Generation Network for Enlarged License Plate Recognition and A Unified Dataset
Jun 02, 2022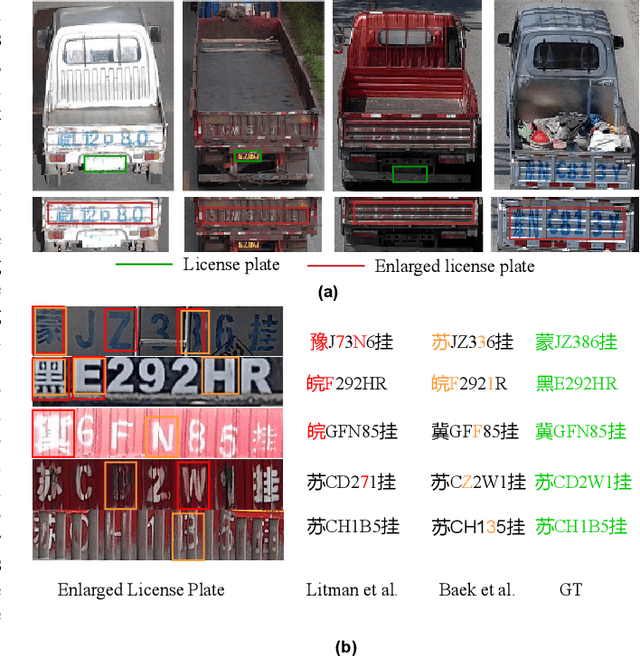
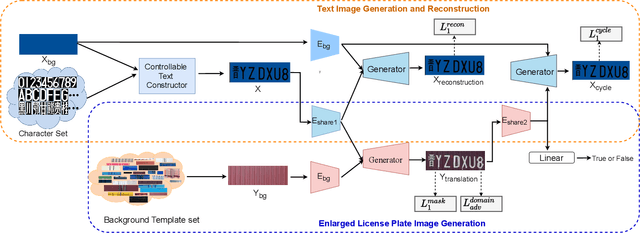


License plate recognition plays a critical role in many practical applications, but license plates of large vehicles are difficult to be recognized due to the factors of low resolution, contamination, low illumination, and occlusion, to name a few. To overcome the above factors, the transportation management department generally introduces the enlarged license plate behind the rear of a vehicle. However, enlarged license plates have high diversity as they are non-standard in position, size, and style. Furthermore, the background regions contain a variety of noisy information which greatly disturbs the recognition of license plate characters. Existing works have not studied this challenging problem. In this work, we first address the enlarged license plate recognition problem and contribute a dataset containing 9342 images, which cover most of the challenges of real scenes. However, the created data are still insufficient to train deep methods of enlarged license plate recognition, and building large-scale training data is very time-consuming and high labor cost. To handle this problem, we propose a novel task-level disentanglement generation framework based on the Disentangled Generation Network (DGNet), which disentangles the generation into the text generation and background generation in an end-to-end manner to effectively ensure diversity and integrity, for robust enlarged license plate recognition. Extensive experiments on the created dataset are conducted, and we demonstrate the effectiveness of the proposed approach in three representative text recognition frameworks.