 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Jul 28, 2024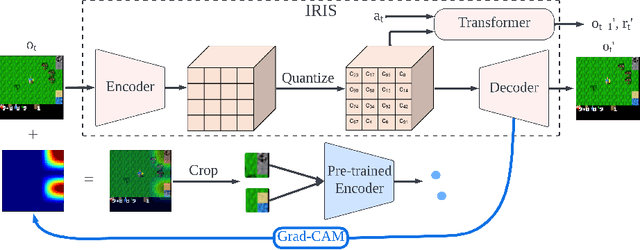
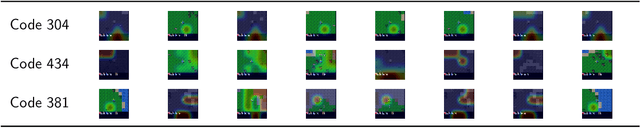
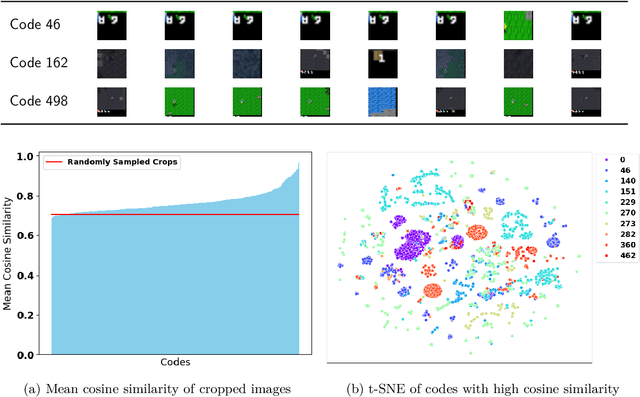
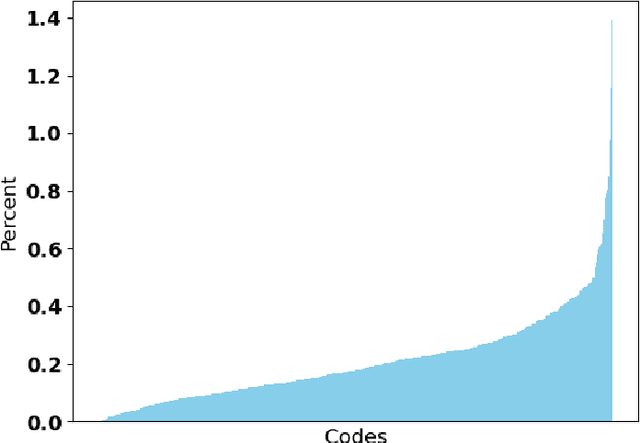
Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.
External Model Motivated Agents: Reinforcement Learning for Enhanced Environment Sampling
Jun 28, 2024



Unlike reinforcement learning (RL) agents, humans remain capable multitaskers in changing environments. In spite of only experiencing the world through their own observations and interactions, people know how to balance focusing on tasks with learning about how changes may affect their understanding of the world. This is possible by choosing to solve tasks in ways that are interesting and generally informative beyond just the current task. Motivated by this, we propose an agent influence framework for RL agents to improve the adaptation efficiency of external models in changing environments without any changes to the agent's rewards. Our formulation is composed of two self-contained modules: interest fields and behavior shaping via interest fields. We implement an uncertainty-based interest field algorithm as well as a skill-sampling-based behavior-shaping algorithm to use in testing this framework. Our results show that our method outperforms the baselines in terms of external model adaptation on metrics that measure both efficiency and performance.
Is Exploration All You Need? Effective Exploration Characteristics for Transfer in Reinforcement Learning
Apr 02, 2024



In deep reinforcement learning (RL) research, there has been a concerted effort to design more efficient and productive exploration methods while solving sparse-reward problems. These exploration methods often share common principles (e.g., improving diversity) and implementation details (e.g., intrinsic reward). Prior work found that non-stationary Markov decision processes (MDPs) require exploration to efficiently adapt to changes in the environment with online transfer learning. However, the relationship between specific exploration characteristics and effective transfer learning in deep RL has not been characterized. In this work, we seek to understand the relationships between salient exploration characteristics and improved performance and efficiency in transfer learning. We test eleven popular exploration algorithms on a variety of transfer types -- or ``novelties'' -- to identify the characteristics that positively affect online transfer learning. Our analysis shows that some characteristics correlate with improved performance and efficiency across a wide range of transfer tasks, while others only improve transfer performance with respect to specific environment changes. From our analysis, make recommendations about which exploration algorithm characteristics are best suited to specific transfer situations.
A Simple Way to Incorporate Novelty Detection in World Models
Oct 12, 2023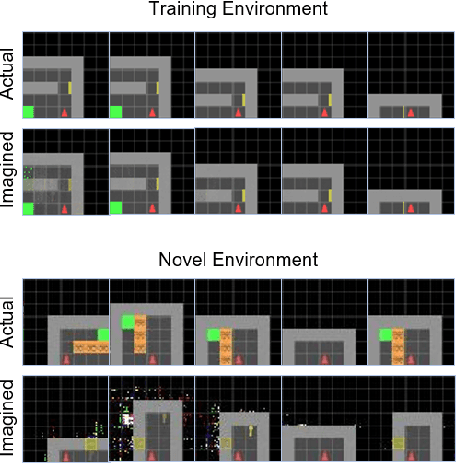

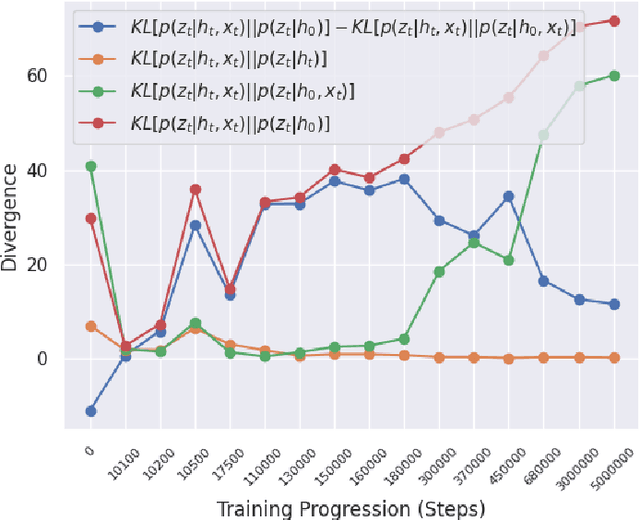
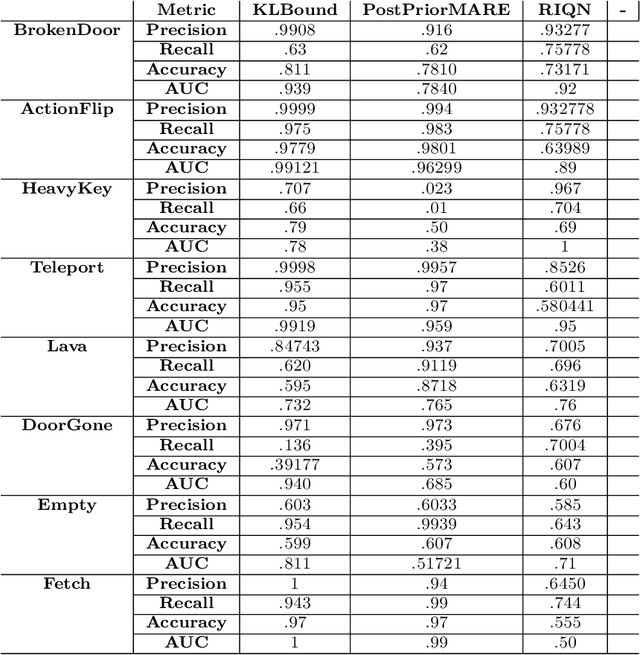
Reinforcement learning (RL) using world models has found significant recent successes. However, when a sudden change to world mechanics or properties occurs then agent performance and reliability can dramatically decline. We refer to the sudden change in visual properties or state transitions as {\em novelties}. Implementing novelty detection within generated world model frameworks is a crucial task for protecting the agent when deployed. In this paper, we propose straightforward bounding approaches to incorporate novelty detection into world model RL agents, by utilizing the misalignment of the world model's hallucinated states and the true observed states as an anomaly score. We first provide an ontology of novelty detection relevant to sequential decision making, then we provide effective approaches to detecting novelties in a distribution of transitions learned by an agent in a world model. Finally, we show the advantage of our work in a novel environment compared to traditional machine learning novelty detection methods as well as currently accepted RL focused novelty detection algorithms.
Neuro-Symbolic World Models for Adapting to Open World Novelty
Jan 16, 2023



Open-world novelty--a sudden change in the mechanics or properties of an environment--is a common occurrence in the real world. Novelty adaptation is an agent's ability to improve its policy performance post-novelty. Most reinforcement learning (RL) methods assume that the world is a closed, fixed process. Consequentially, RL policies adapt inefficiently to novelties. To address this, we introduce WorldCloner, an end-to-end trainable neuro-symbolic world model for rapid novelty adaptation. WorldCloner learns an efficient symbolic representation of the pre-novelty environment transitions, and uses this transition model to detect novelty and efficiently adapt to novelty in a single-shot fashion. Additionally, WorldCloner augments the policy learning process using imagination-based adaptation, where the world model simulates transitions of the post-novelty environment to help the policy adapt. By blending ''imagined'' transitions with interactions in the post-novelty environment, performance can be recovered with fewer total environment interactions. Using environments designed for studying novelty in sequential decision-making problems, we show that the symbolic world model helps its neural policy adapt more efficiently than model-based and model-based neural-only reinforcement learning methods.
The Role of Exploration for Task Transfer in Reinforcement Learning
Oct 11, 2022
The exploration--exploitation trade-off in reinforcement learning (RL) is a well-known and much-studied problem that balances greedy action selection with novel experience, and the study of exploration methods is usually only considered in the context of learning the optimal policy for a single learning task. However, in the context of online task transfer, where there is a change to the task during online operation, we hypothesize that exploration strategies that anticipate the need to adapt to future tasks can have a pronounced impact on the efficiency of transfer. As such, we re-examine the exploration--exploitation trade-off in the context of transfer learning. In this work, we review reinforcement learning exploration methods, define a taxonomy with which to organize them, analyze these methods' differences in the context of task transfer, and suggest avenues for future investigation.
NovGrid: A Flexible Grid World for Evaluating Agent Response to Novelty
Mar 23, 2022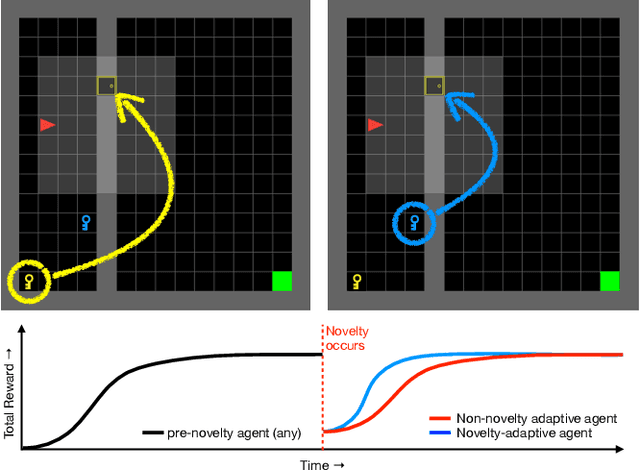
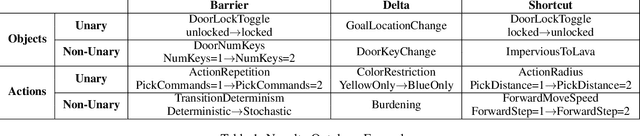
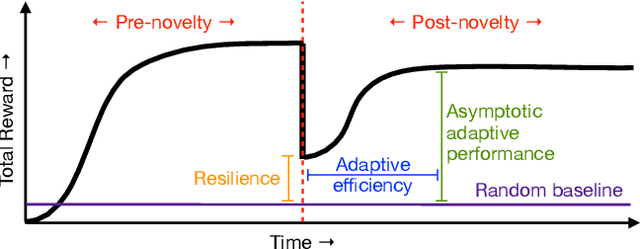
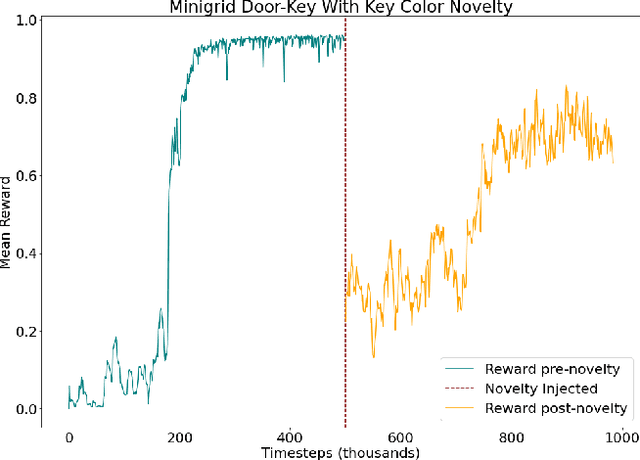
A robust body of reinforcement learning techniques have been developed to solve complex sequential decision making problems. However, these methods assume that train and evaluation tasks come from similarly or identically distributed environments. This assumption does not hold in real life where small novel changes to the environment can make a previously learned policy fail or introduce simpler solutions that might never be found. To that end we explore the concept of {\em novelty}, defined in this work as the sudden change to the mechanics or properties of environment. We provide an ontology of for novelties most relevant to sequential decision making, which distinguishes between novelties that affect objects versus actions, unary properties versus non-unary relations, and the distribution of solutions to a task. We introduce NovGrid, a novelty generation framework built on MiniGrid, acting as a toolkit for rapidly developing and evaluating novelty-adaptation-enabled reinforcement learning techniques. Along with the core NovGrid we provide exemplar novelties aligned with our ontology and instantiate them as novelty templates that can be applied to many MiniGrid-compliant environments. Finally, we present a set of metrics built into our framework for the evaluation of novelty-adaptation-enabled machine-learning techniques, and show characteristics of a baseline RL model using these metrics.