 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interpretability of Codebooks in Model-Based Reinforcement Learning is Limited
Paper and Code
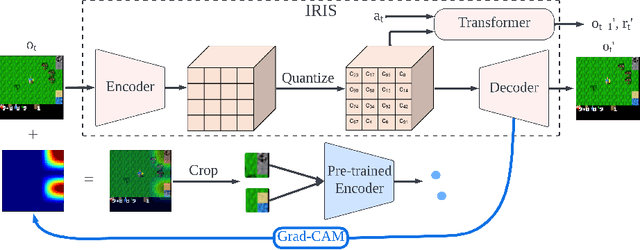
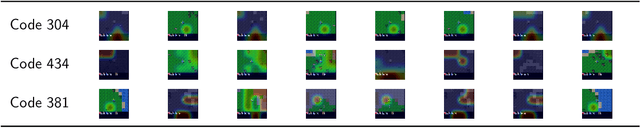
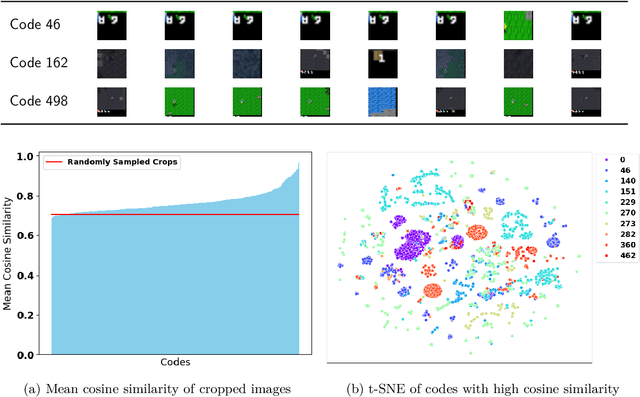
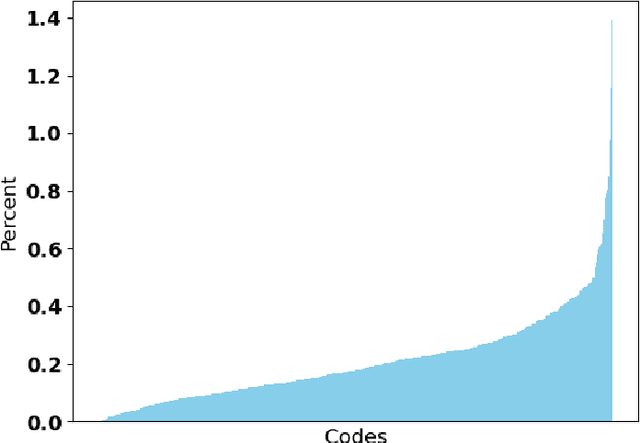
Interpretability of deep reinforcement learning systems could assist operators with understanding how they interact with their environment. Vector quantization methods -- also called codebook methods -- discretize a neural network's latent space that is often suggested to yield emergent interpretability. We investigate whether vector quantization in fact provides interpretability in model-based reinforcement learning. Our experiments, conducted in the reinforcement learning environment Crafter, show that the codes of vector quantization models are inconsistent, have no guarantee of uniqueness, and have a limited impact on concept disentanglement, all of which are necessary traits for interpretability. We share insights on why vector quantization may be fundamentally insufficient for model interpretability.