 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverging Towards Hallucination: Detection of Failures in Vision-Language Models via Multi-token Aggregation
May 16, 2025



Vision-language models (VLMs) now rival human performance on many multimodal tasks, yet they still hallucinate objects or generate unsafe text. Current hallucination detectors, e.g., single-token linear probing (SLP) and P(True), typically analyze only the logit of the first generated token or just its highest scoring component overlooking richer signals embedded within earlier token distributions. We demonstrate that analyzing the complete sequence of early logits potentially provides substantially more diagnostic information. We emphasize that hallucinations may only emerge after several tokens, as subtle inconsistencies accumulate over time. By analyzing the Kullback-Leibler (KL) divergence between logits corresponding to hallucinated and non-hallucinated tokens, we underscore the importance of incorporating later-token logits to more accurately capture the reliability dynamics of VLMs. In response, we introduce Multi-Token Reliability Estimation (MTRE), a lightweight, white-box method that aggregates logits from the first ten tokens using multi-token log-likelihood ratios and self-attention. Despite the challenges posed by large vocabulary sizes and long logit sequences, MTRE remains efficient and tractable. On MAD-Bench, MM-SafetyBench, MathVista, and four compositional-geometry benchmarks, MTRE improves AUROC by 9.4 +/- 1.3 points over SLP and by 12.1 +/- 1.7 points over P(True), setting a new state-of-the-art in hallucination detection for open-source VLMs.
Topological Signatures of Adversaries in Multimodal Alignments
Jan 29, 2025Multimodal Machine Learning systems, particularly those aligning text and image data like CLIP/BLIP models, have become increasingly prevalent, yet remain susceptible to adversarial attacks. While substantial research has addressed adversarial robustness in unimodal contexts, defense strategies for multimodal systems are underexplored. This work investigates the topological signatures that arise between image and text embeddings and shows how adversarial attacks disrupt their alignment, introducing distinctive signatures. We specifically leverage persistent homology and introduce two novel Topological-Contrastive losses based on Total Persistence and Multi-scale kernel methods to analyze the topological signatures introduced by adversarial perturbations. We observe a pattern of monotonic changes in the proposed topological losses emerging in a wide range of attacks on image-text alignments, as more adversarial samples are introduced in the data. By designing an algorithm to back-propagate these signatures to input samples, we are able to integrate these signatures into Maximum Mean Discrepancy tests, creating a novel class of tests that leverage topological signatures for better adversarial detection.
LoRID: Low-Rank Iterative Diffusion for Adversarial Purification
Sep 12, 2024



This work presents an information-theoretic examination of diffusion-based purification methods, the state-of-the-art adversarial defenses that utilize diffusion models to remove malicious perturbations in adversarial examples. By theoretically characterizing the inherent purification errors associated with the Markov-based diffusion purifications, we introduce LoRID, a novel Low-Rank Iterative Diffusion purification method designed to remove adversarial perturbation with low intrinsic purification errors. LoRID centers around a multi-stage purification process that leverages multiple rounds of diffusion-denoising loops at the early time-steps of the diffusion models, and the integration of Tucker decomposition, an extension of matrix factorization, to remove adversarial noise at high-noise regimes. Consequently, LoRID increases the effective diffusion time-steps and overcomes strong adversarial attacks, achieving superior robustness performance in CIFAR-10/100, CelebA-HQ, and ImageNet datasets under both white-box and black-box settings.
LaFA: Latent Feature Attacks on Non-negative Matrix Factorization
Aug 07, 2024



As Machine Learning (ML) applications rapidly grow, concerns about adversarial attacks compromising their reliability have gained significant attention. One unsupervised ML method known for its resilience to such attacks is Non-negative Matrix Factorization (NMF), an algorithm that decomposes input data into lower-dimensional latent features. However, the introduction of powerful computational tools such as Pytorch enables the computation of gradients of the latent features with respect to the original data, raising concerns about NMF's reliability. Interestingly, naively deriving the adversarial loss for NMF as in the case of ML would result in the reconstruction loss, which can be shown theoretically to be an ineffective attacking objective. In this work, we introduce a novel class of attacks in NMF termed Latent Feature Attacks (LaFA), which aim to manipulate the latent features produced by the NMF process. Our method utilizes the Feature Error (FE) loss directly on the latent features. By employing FE loss, we generate perturbations in the original data that significantly affect the extracted latent features, revealing vulnerabilities akin to those found in other ML techniques. To handle large peak-memory overhead from gradient back-propagation in FE attacks, we develop a method based on implicit differentiation which enables their scaling to larger datasets. We validate NMF vulnerabilities and FE attacks effectiveness through extensive experiments on synthetic and real-world data.
Towards Faster Matrix Diagonalization with Graph Isomorphism Networks and the AlphaZero Framework
Jun 30, 2024In this paper, we introduce innovative approaches for accelerating the Jacobi method for matrix diagonalization, specifically through the formulation of large matrix diagonalization as a Semi-Markov Decision Process and small matrix diagonalization as a Markov Decision Process. Furthermore, we examine the potential of utilizing scalable architecture between different-sized matrices. During a short training period, our method discovered a significant reduction in the number of steps required for diagonalization and exhibited efficient inference capabilities. Importantly, this approach demonstrated possible scalability to large-sized matrices, indicating its potential for wide-ranging applicability. Upon training completion, we obtain action-state probabilities and transition graphs, which depict transitions between different states. These outputs not only provide insights into the diagonalization process but also pave the way for cost savings pertinent to large-scale matrices. The advancements made in this research enhance the efficacy and scalability of matrix diagonalization, pushing for new possibilities for deployment in practical applications in scientific and engineering domains.
Accelerating Matrix Diagonalization through Decision Transformers with Epsilon-Greedy Optimization
Jun 23, 2024This paper introduces a novel framework for matrix diagonalization, recasting it as a sequential decision-making problem and applying the power of Decision Transformers (DTs). Our approach determines optimal pivot selection during diagonalization with the Jacobi algorithm, leading to significant speedups compared to the traditional max-element Jacobi method. To bolster robustness, we integrate an epsilon-greedy strategy, enabling success in scenarios where deterministic approaches fail. This work demonstrates the effectiveness of DTs in complex computational tasks and highlights the potential of reimagining mathematical operations through a machine learning lens. Furthermore, we establish the generalizability of our method by using transfer learning to diagonalize matrices of smaller sizes than those trained.
Is Exploration All You Need? Effective Exploration Characteristics for Transfer in Reinforcement Learning
Apr 02, 2024



In deep reinforcement learning (RL) research, there has been a concerted effort to design more efficient and productive exploration methods while solving sparse-reward problems. These exploration methods often share common principles (e.g., improving diversity) and implementation details (e.g., intrinsic reward). Prior work found that non-stationary Markov decision processes (MDPs) require exploration to efficiently adapt to changes in the environment with online transfer learning. However, the relationship between specific exploration characteristics and effective transfer learning in deep RL has not been characterized. In this work, we seek to understand the relationships between salient exploration characteristics and improved performance and efficiency in transfer learning. We test eleven popular exploration algorithms on a variety of transfer types -- or ``novelties'' -- to identify the characteristics that positively affect online transfer learning. Our analysis shows that some characteristics correlate with improved performance and efficiency across a wide range of transfer tasks, while others only improve transfer performance with respect to specific environment changes. From our analysis, make recommendations about which exploration algorithm characteristics are best suited to specific transfer situations.
A Simple Way to Incorporate Novelty Detection in World Models
Oct 12, 2023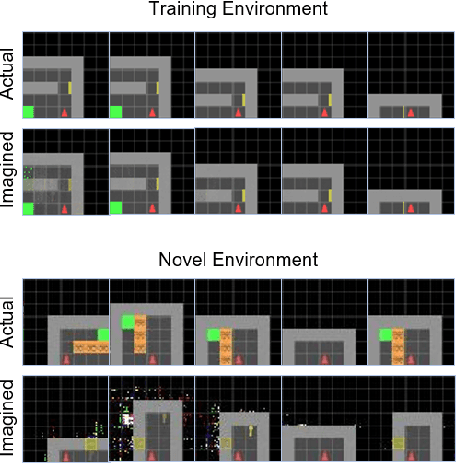

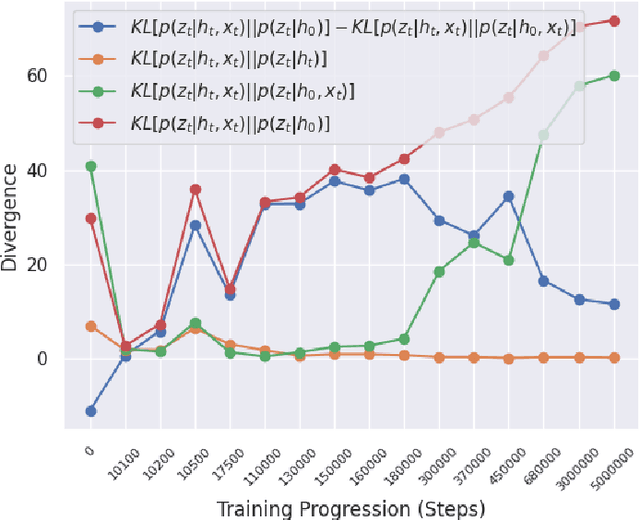
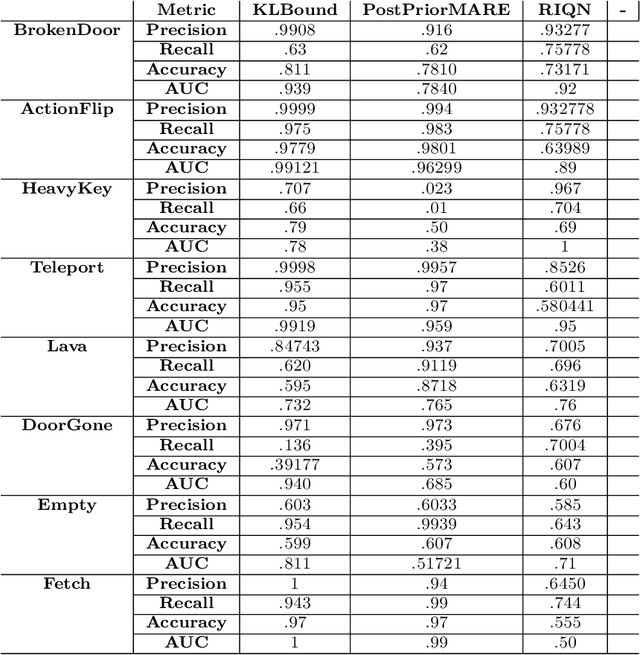
Reinforcement learning (RL) using world models has found significant recent successes. However, when a sudden change to world mechanics or properties occurs then agent performance and reliability can dramatically decline. We refer to the sudden change in visual properties or state transitions as {\em novelties}. Implementing novelty detection within generated world model frameworks is a crucial task for protecting the agent when deployed. In this paper, we propose straightforward bounding approaches to incorporate novelty detection into world model RL agents, by utilizing the misalignment of the world model's hallucinated states and the true observed states as an anomaly score. We first provide an ontology of novelty detection relevant to sequential decision making, then we provide effective approaches to detecting novelties in a distribution of transitions learned by an agent in a world model. Finally, we show the advantage of our work in a novel environment compared to traditional machine learning novelty detection methods as well as currently accepted RL focused novelty detection algorithms.