 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Exploration All You Need? Effective Exploration Characteristics for Transfer in Reinforcement Learning
Apr 02, 2024



In deep reinforcement learning (RL) research, there has been a concerted effort to design more efficient and productive exploration methods while solving sparse-reward problems. These exploration methods often share common principles (e.g., improving diversity) and implementation details (e.g., intrinsic reward). Prior work found that non-stationary Markov decision processes (MDPs) require exploration to efficiently adapt to changes in the environment with online transfer learning. However, the relationship between specific exploration characteristics and effective transfer learning in deep RL has not been characterized. In this work, we seek to understand the relationships between salient exploration characteristics and improved performance and efficiency in transfer learning. We test eleven popular exploration algorithms on a variety of transfer types -- or ``novelties'' -- to identify the characteristics that positively affect online transfer learning. Our analysis shows that some characteristics correlate with improved performance and efficiency across a wide range of transfer tasks, while others only improve transfer performance with respect to specific environment changes. From our analysis, make recommendations about which exploration algorithm characteristics are best suited to specific transfer situations.
Detecting and Adapting to Novelty in Games
Jun 04, 2021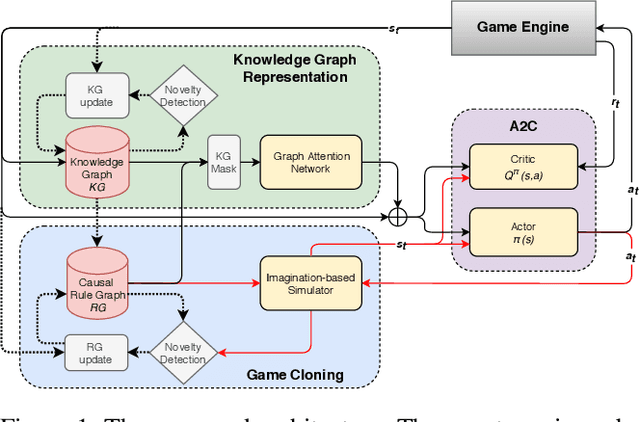
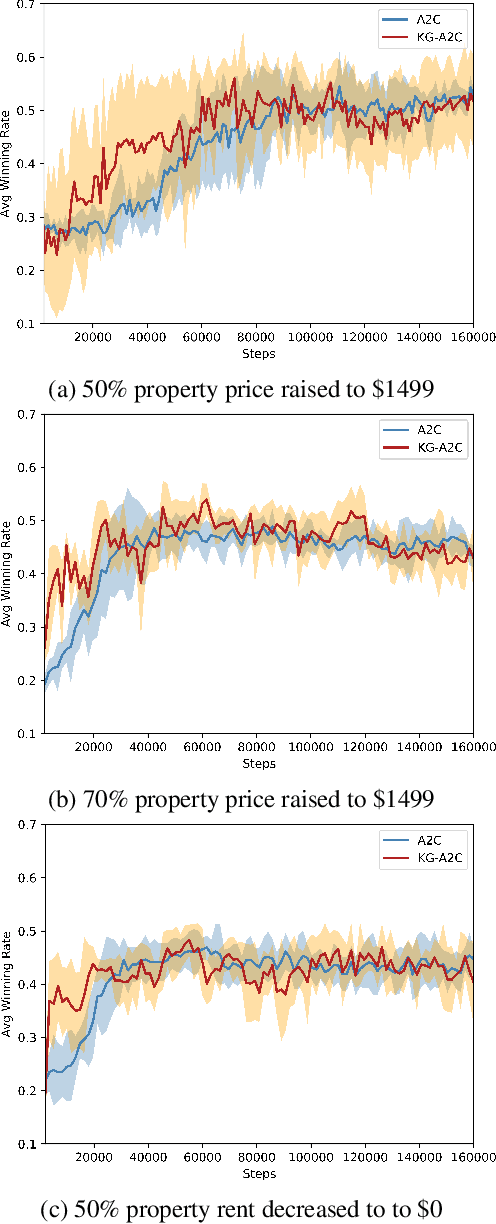
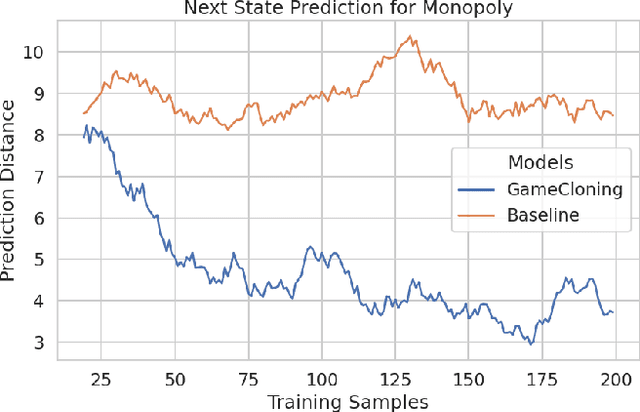
Open-world novelty occurs when the rules of an environment can change abruptly, such as when a game player encounters "house rules". To address open-world novelty, game playing agents must be able to detect when novelty is injected, and to quickly adapt to the new rules. We propose a model-based reinforcement learning approach where game state and rules are represented as knowledge graphs. The knowledge graph representation of the state and rules allows novelty to be detected as changes in the knowledge graph, assists with the training of deep reinforcement learners, and enables imagination-based re-training where the agent uses the knowledge graph to perform look-ahead.