 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024


Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
LaFA: Latent Feature Attacks on Non-negative Matrix Factorization
Aug 07, 2024



As Machine Learning (ML) applications rapidly grow, concerns about adversarial attacks compromising their reliability have gained significant attention. One unsupervised ML method known for its resilience to such attacks is Non-negative Matrix Factorization (NMF), an algorithm that decomposes input data into lower-dimensional latent features. However, the introduction of powerful computational tools such as Pytorch enables the computation of gradients of the latent features with respect to the original data, raising concerns about NMF's reliability. Interestingly, naively deriving the adversarial loss for NMF as in the case of ML would result in the reconstruction loss, which can be shown theoretically to be an ineffective attacking objective. In this work, we introduce a novel class of attacks in NMF termed Latent Feature Attacks (LaFA), which aim to manipulate the latent features produced by the NMF process. Our method utilizes the Feature Error (FE) loss directly on the latent features. By employing FE loss, we generate perturbations in the original data that significantly affect the extracted latent features, revealing vulnerabilities akin to those found in other ML techniques. To handle large peak-memory overhead from gradient back-propagation in FE attacks, we develop a method based on implicit differentiation which enables their scaling to larger datasets. We validate NMF vulnerabilities and FE attacks effectiveness through extensive experiments on synthetic and real-world data.
TopicTag: Automatic Annotation of NMF Topic Models Using Chain of Thought and Prompt Tuning with LLMs
Jul 29, 2024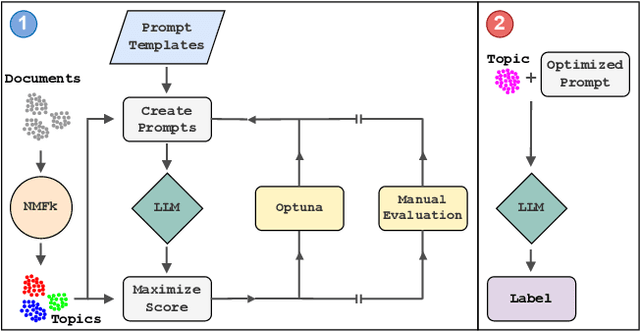
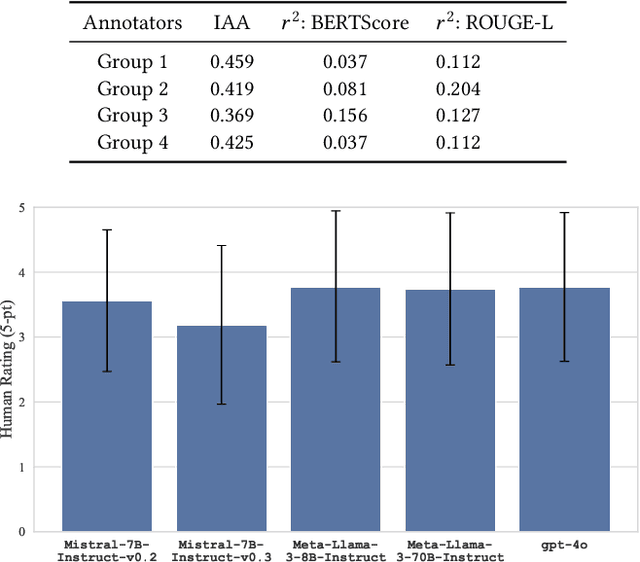
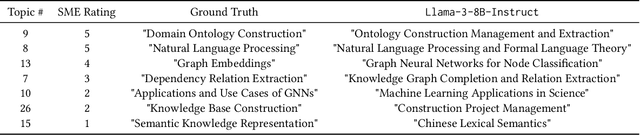
Topic modeling is a technique for organizing and extracting themes from large collections of unstructured text. Non-negative matrix factorization (NMF) is a common unsupervised approach that decomposes a term frequency-inverse document frequency (TF-IDF) matrix to uncover latent topics and segment the dataset accordingly. While useful for highlighting patterns and clustering documents, NMF does not provide explicit topic labels, necessitating subject matter experts (SMEs) to assign labels manually. We present a methodology for automating topic labeling in documents clustered via NMF with automatic model determination (NMFk). By leveraging the output of NMFk and employing prompt engineering, we utilize large language models (LLMs) to generate accurate topic labels. Our case study on over 34,000 scientific abstracts on Knowledge Graphs demonstrates the effectiveness of our method in enhancing knowledge management and document organization.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
MalwareDNA: Simultaneous Classification of Malware, Malware Families, and Novel Malware
Sep 04, 2023


Malware is one of the most dangerous and costly cyber threats to national security and a crucial factor in modern cyber-space. However, the adoption of machine learning (ML) based solutions against malware threats has been relatively slow. Shortcomings in the existing ML approaches are likely contributing to this problem. The majority of current ML approaches ignore real-world challenges such as the detection of novel malware. In addition, proposed ML approaches are often designed either for malware/benign-ware classification or malware family classification. Here we introduce and showcase preliminary capabilities of a new method that can perform precise identification of novel malware families, while also unifying the capability for malware/benign-ware classification and malware family classification into a single framework.
Robust Adversarial Defense by Tensor Factorization
Sep 03, 2023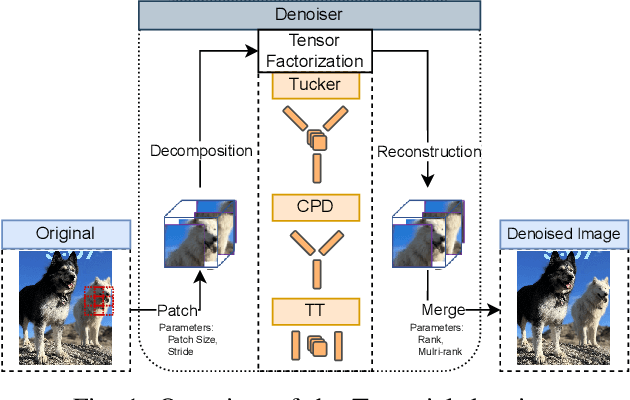
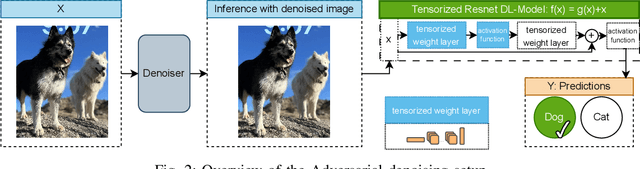
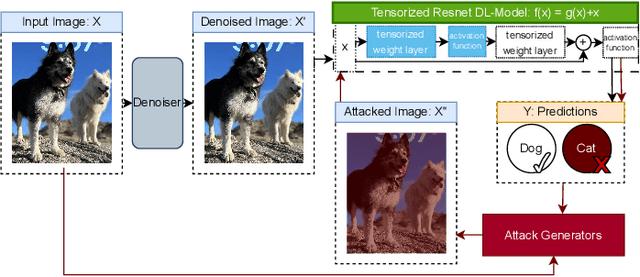
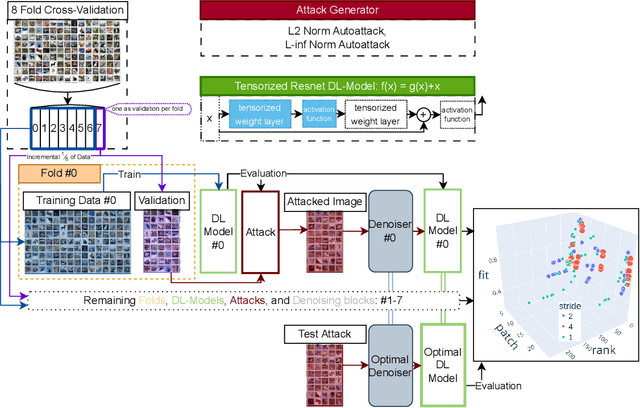
As machine learning techniques become increasingly prevalent in data analysis, the threat of adversarial attacks has surged, necessitating robust defense mechanisms. Among these defenses, methods exploiting low-rank approximations for input data preprocessing and neural network (NN) parameter factorization have shown potential. Our work advances this field further by integrating the tensorization of input data with low-rank decomposition and tensorization of NN parameters to enhance adversarial defense. The proposed approach demonstrates significant defense capabilities, maintaining robust accuracy even when subjected to the strongest known auto-attacks. Evaluations against leading-edge robust performance benchmarks reveal that our results not only hold their ground against the best defensive methods available but also exceed all current defense strategies that rely on tensor factorizations. This study underscores the potential of integrating tensorization and low-rank decomposition as a robust defense against adversarial attacks in machine learning.
Process Modeling, Hidden Markov Models, and Non-negative Tensor Factorization with Model Selection
Oct 03, 2022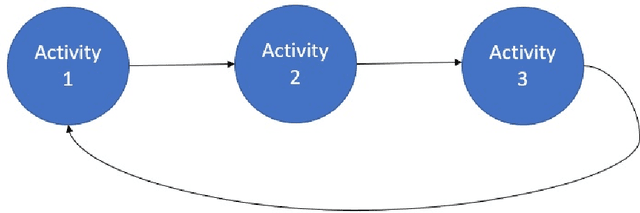
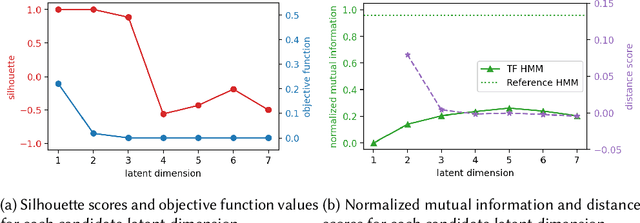
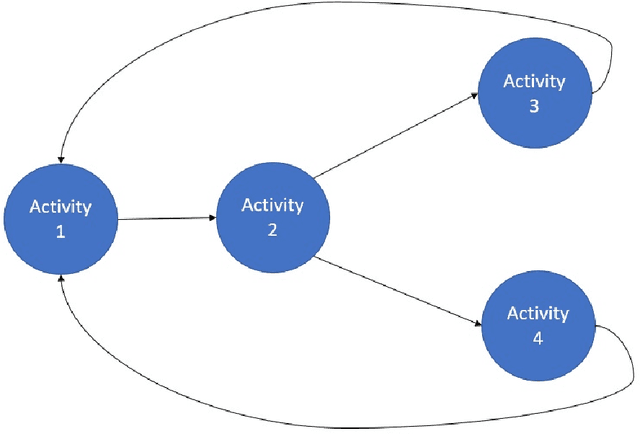
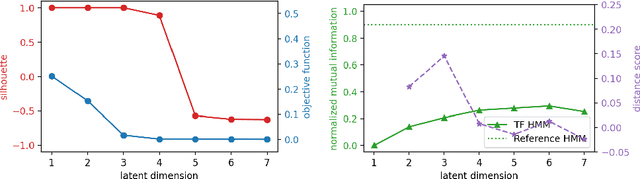
Monitoring of industrial processes is a critical capability in industry and in government to ensure reliability of production cycles, quick emergency response, and national security. Process monitoring allows users to gauge the involvement of an organization in an industrial process or predict the degradation or aging of machine parts in processes taking place at a remote location. Similar to many data science applications, we usually only have access to limited raw data, such as satellite imagery, short video clips, some event logs, and signatures captured by a small set of sensors. To combat data scarcity, we leverage the knowledge of subject matter experts (SMEs) who are familiar with the process. Various process mining techniques have been developed for this type of analysis; typically such approaches combine theoretical process models built based on domain expert insights with ad-hoc integration of available pieces of raw data. Here, we introduce a novel mathematically sound method that integrates theoretical process models (as proposed by SMEs) with interrelated minimal Hidden Markov Models (HMM), built via non-negative tensor factorization and discrete model simulations. Our method consolidates: (a) Theoretical process models development, (b) Discrete model simulations (c) HMM, (d) Joint Non-negative Matrix Factorization (NMF) and Non-negative Tensor Factorization (NTF), and (e) Custom model selection. To demonstrate our methodology and its abilities, we apply it on simple synthetic and real world process models.
SeNMFk-SPLIT: Large Corpora Topic Modeling by Semantic Non-negative Matrix Factorization with Automatic Model Selection
Aug 21, 2022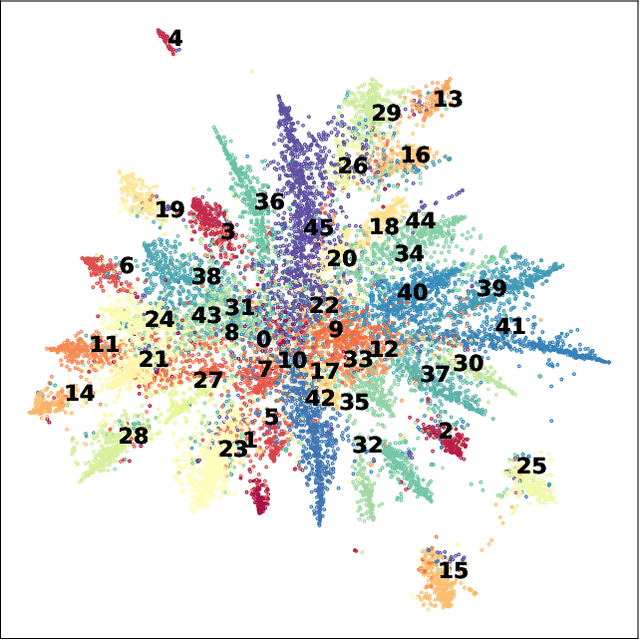

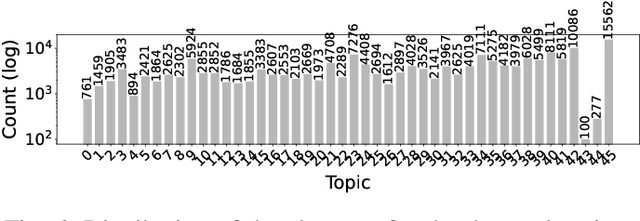

As the amount of text data continues to grow, topic modeling is serving an important role in understanding the content hidden by the overwhelming quantity of documents. One popular topic modeling approach is non-negative matrix factorization (NMF), an unsupervised machine learning (ML) method. Recently, Semantic NMF with automatic model selection (SeNMFk) has been proposed as a modification to NMF. In addition to heuristically estimating the number of topics, SeNMFk also incorporates the semantic structure of the text. This is performed by jointly factorizing the term frequency-inverse document frequency (TF-IDF) matrix with the co-occurrence/word-context matrix, the values of which represent the number of times two words co-occur in a predetermined window of the text. In this paper, we introduce a novel distributed method, SeNMFk-SPLIT, for semantic topic extraction suitable for large corpora. Contrary to SeNMFk, our method enables the joint factorization of large documents by decomposing the word-context and term-document matrices separately. We demonstrate the capability of SeNMFk-SPLIT by applying it to the entire artificial intelligence (AI) and ML scientific literature uploaded on arXiv.