 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Linguistic Diversity in Embodied AI Datasets
Jan 06, 2026Language plays a critical role in Vision-Language-Action (VLA) models, yet the linguistic characteristics of the datasets used to train and evaluate these systems remain poorly documented. In this work, we present a systematic dataset audit of several widely used VLA corpora, aiming to characterize what kinds of instructions these datasets actually contain and how much linguistic variety they provide. We quantify instruction language along complementary dimensions-including lexical variety, duplication and overlap, semantic similarity, and syntactic complexity. Our analysis shows that many datasets rely on highly repetitive, template-like commands with limited structural variation, yielding a narrow distribution of instruction forms. We position these findings as descriptive documentation of the language signal available in current VLA training and evaluation data, intended to support more detailed dataset reporting, more principled dataset selection, and targeted curation or augmentation strategies that broaden language coverage.
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024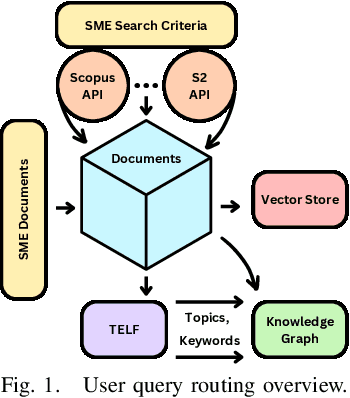
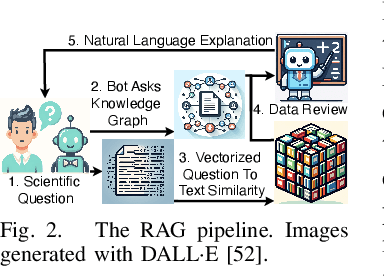
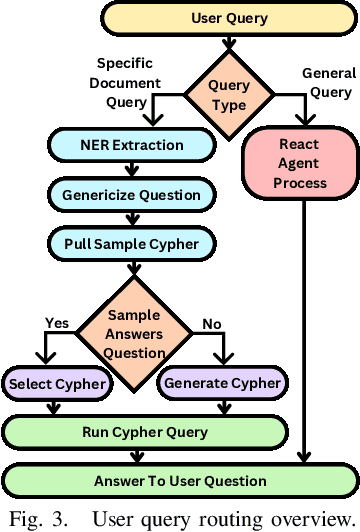
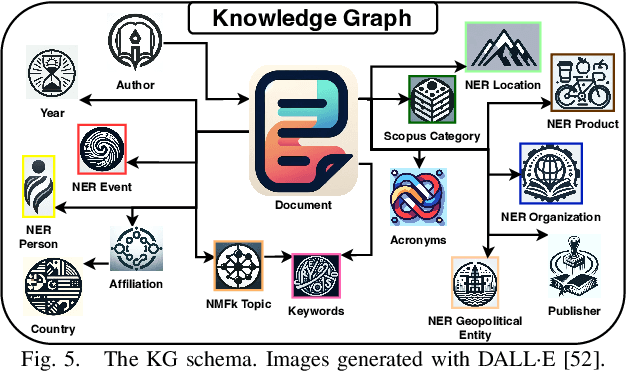
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
TopicTag: Automatic Annotation of NMF Topic Models Using Chain of Thought and Prompt Tuning with LLMs
Jul 29, 2024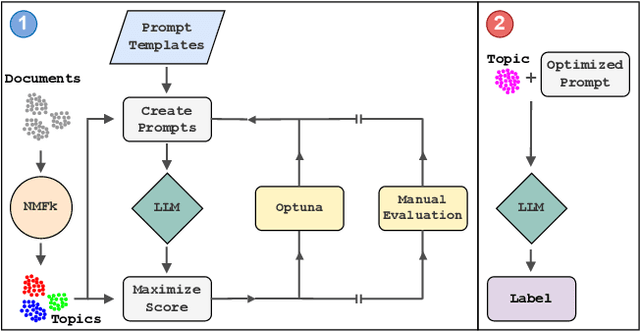
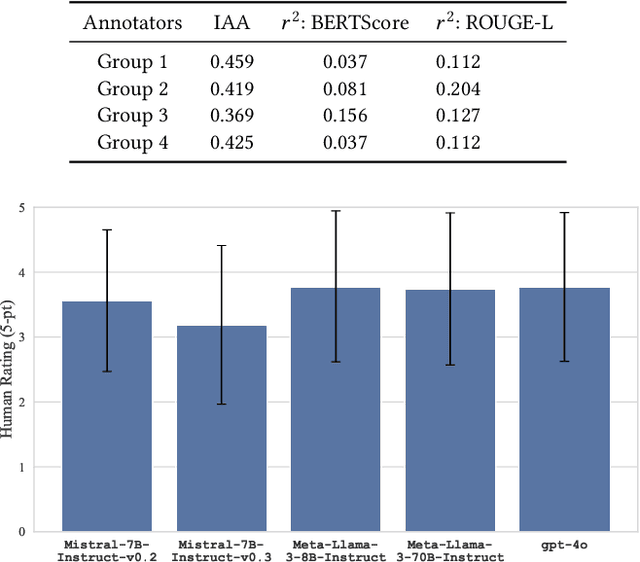
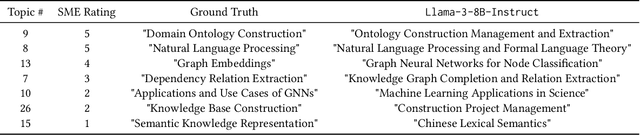
Topic modeling is a technique for organizing and extracting themes from large collections of unstructured text. Non-negative matrix factorization (NMF) is a common unsupervised approach that decomposes a term frequency-inverse document frequency (TF-IDF) matrix to uncover latent topics and segment the dataset accordingly. While useful for highlighting patterns and clustering documents, NMF does not provide explicit topic labels, necessitating subject matter experts (SMEs) to assign labels manually. We present a methodology for automating topic labeling in documents clustered via NMF with automatic model determination (NMFk). By leveraging the output of NMFk and employing prompt engineering, we utilize large language models (LLMs) to generate accurate topic labels. Our case study on over 34,000 scientific abstracts on Knowledge Graphs demonstrates the effectiveness of our method in enhancing knowledge management and document organization.
The Collection of a Human Robot Collaboration Dataset for Cooperative Assembly in Glovebox Environments
Jul 19, 2024
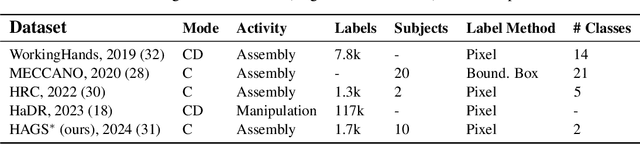

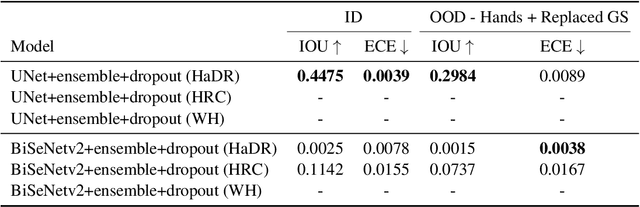
Industry 4.0 introduced AI as a transformative solution for modernizing manufacturing processes. Its successor, Industry 5.0, envisions humans as collaborators and experts guiding these AI-driven manufacturing solutions. Developing these techniques necessitates algorithms capable of safe, real-time identification of human positions in a scene, particularly their hands, during collaborative assembly. Although substantial efforts have curated datasets for hand segmentation, most focus on residential or commercial domains. Existing datasets targeting industrial settings predominantly rely on synthetic data, which we demonstrate does not effectively transfer to real-world operations. Moreover, these datasets lack uncertainty estimations critical for safe collaboration. Addressing these gaps, we present HAGS: Hand and Glove Segmentation Dataset. This dataset provides 1200 challenging examples to build applications toward hand and glove segmentation in industrial human-robot collaboration scenarios as well as assess out-of-distribution images, constructed via green screen augmentations, to determine ML-classifier robustness. We study state-of-the-art, real-time segmentation models to evaluate existing methods. Our dataset and baselines are publicly available: https://dataverse.tdl.org/dataset.xhtml?persistentId=doi:10.18738/T8/85R7KQ and https://github.com/UTNuclearRoboticsPublic/assembly_glovebox_dataset.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
Temporal and Semantic Evaluation Metrics for Foundation Models in Post-Hoc Analysis of Robotic Sub-tasks
Mar 25, 2024Recent works in Task and Motion Planning (TAMP) show that training control policies on language-supervised robot trajectories with quality labeled data markedly improves agent task success rates. However, the scarcity of such data presents a significant hurdle to extending these methods to general use cases. To address this concern, we present an automated framework to decompose trajectory data into temporally bounded and natural language-based descriptive sub-tasks by leveraging recent prompting strategies for Foundation Models (FMs) including both Large Language Models (LLMs) and Vision Language Models (VLMs). Our framework provides both time-based and language-based descriptions for lower-level sub-tasks that comprise full trajectories. To rigorously evaluate the quality of our automatic labeling framework, we contribute an algorithm SIMILARITY to produce two novel metrics, temporal similarity and semantic similarity. The metrics measure the temporal alignment and semantic fidelity of language descriptions between two sub-task decompositions, namely an FM sub-task decomposition prediction and a ground-truth sub-task decomposition. We present scores for temporal similarity and semantic similarity above 90%, compared to 30% of a randomized baseline, for multiple robotic environments, demonstrating the effectiveness of our proposed framework. Our results enable building diverse, large-scale, language-supervised datasets for improved robotic TAMP.
Multimodal Grounding for Embodied AI via Augmented Reality Headsets for Natural Language Driven Task Planning
Apr 26, 2023Recent advances in generative modeling have spurred a resurgence in the field of Embodied Artificial Intelligence (EAI). EAI systems typically deploy large language models to physical systems capable of interacting with their environment. In our exploration of EAI for industrial domains, we successfully demonstrate the feasibility of co-located, human-robot teaming. Specifically, we construct an experiment where an Augmented Reality (AR) headset mediates information exchange between an EAI agent and human operator for a variety of inspection tasks. To our knowledge the use of an AR headset for multimodal grounding and the application of EAI to industrial tasks are novel contributions within Embodied AI research. In addition, we highlight potential pitfalls in EAI's construction by providing quantitative and qualitative analysis on prompt robustness.
Laplacian Segmentation Networks: Improved Epistemic Uncertainty from Spatial Aleatoric Uncertainty
Mar 23, 2023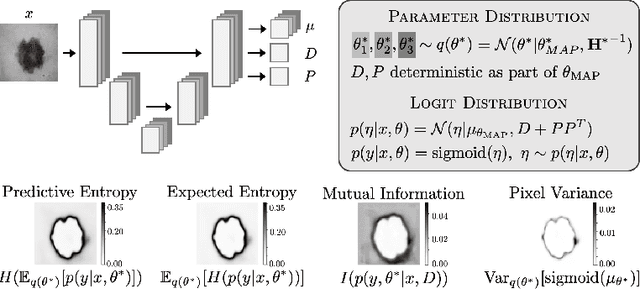


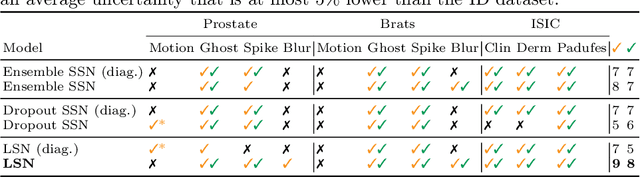
Out of distribution (OOD) medical images are frequently encountered, e.g. because of site- or scanner differences, or image corruption. OOD images come with a risk of incorrect image segmentation, potentially negatively affecting downstream diagnoses or treatment. To ensure robustness to such incorrect segmentations, we propose Laplacian Segmentation Networks (LSN) that jointly model epistemic (model) and aleatoric (data) uncertainty in image segmentation. We capture data uncertainty with a spatially correlated logit distribution. For model uncertainty, we propose the first Laplace approximation of the weight posterior that scales to large neural networks with skip connections that have high-dimensional outputs. Empirically, we demonstrate that modelling spatial pixel correlation allows the Laplacian Segmentation Network to successfully assign high epistemic uncertainty to out-of-distribution objects appearing within images.