 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Linguistic Diversity in Embodied AI Datasets
Jan 06, 2026Language plays a critical role in Vision-Language-Action (VLA) models, yet the linguistic characteristics of the datasets used to train and evaluate these systems remain poorly documented. In this work, we present a systematic dataset audit of several widely used VLA corpora, aiming to characterize what kinds of instructions these datasets actually contain and how much linguistic variety they provide. We quantify instruction language along complementary dimensions-including lexical variety, duplication and overlap, semantic similarity, and syntactic complexity. Our analysis shows that many datasets rely on highly repetitive, template-like commands with limited structural variation, yielding a narrow distribution of instruction forms. We position these findings as descriptive documentation of the language signal available in current VLA training and evaluation data, intended to support more detailed dataset reporting, more principled dataset selection, and targeted curation or augmentation strategies that broaden language coverage.
Matrix Factorization for Inferring Associations and Missing Links
Mar 06, 2025Missing link prediction is a method for network analysis, with applications in recommender systems, biology, social sciences, cybersecurity, information retrieval, and Artificial Intelligence (AI) reasoning in Knowledge Graphs. Missing link prediction identifies unseen but potentially existing connections in a network by analyzing the observed patterns and relationships. In proliferation detection, this supports efforts to identify and characterize attempts by state and non-state actors to acquire nuclear weapons or associated technology - a notoriously challenging but vital mission for global security. Dimensionality reduction techniques like Non-Negative Matrix Factorization (NMF) and Logistic Matrix Factorization (LMF) are effective but require selection of the matrix rank parameter, that is, of the number of hidden features, k, to avoid over/under-fitting. We introduce novel Weighted (WNMFk), Boolean (BNMFk), and Recommender (RNMFk) matrix factorization methods, along with ensemble variants incorporating logistic factorization, for link prediction. Our methods integrate automatic model determination for rank estimation by evaluating stability and accuracy using a modified bootstrap methodology and uncertainty quantification (UQ), assessing prediction reliability under random perturbations. We incorporate Otsu threshold selection and k-means clustering for Boolean matrix factorization, comparing them to coordinate descent-based Boolean thresholding. Our experiments highlight the impact of rank k selection, evaluate model performance under varying test-set sizes, and demonstrate the benefits of UQ for reliable predictions using abstention. We validate our methods on three synthetic datasets (Boolean and uniformly distributed) and benchmark them against LMF and symmetric LMF (symLMF) on five real-world protein-protein interaction networks, showcasing an improved prediction performance.
HEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
TopicTag: Automatic Annotation of NMF Topic Models Using Chain of Thought and Prompt Tuning with LLMs
Jul 29, 2024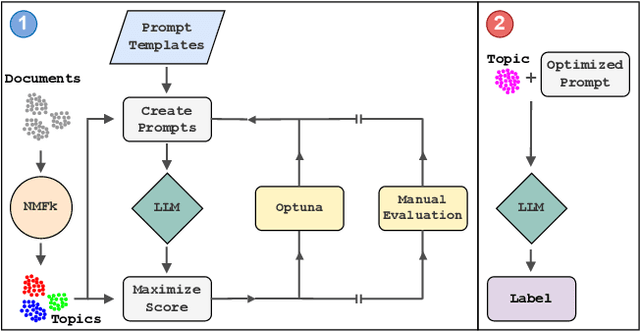
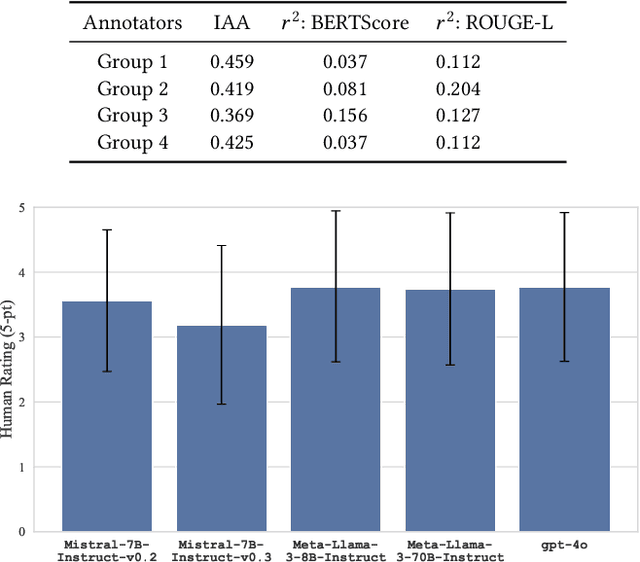
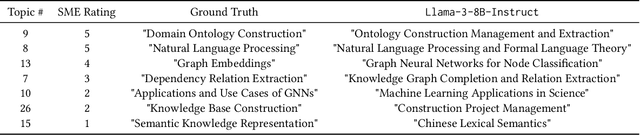
Topic modeling is a technique for organizing and extracting themes from large collections of unstructured text. Non-negative matrix factorization (NMF) is a common unsupervised approach that decomposes a term frequency-inverse document frequency (TF-IDF) matrix to uncover latent topics and segment the dataset accordingly. While useful for highlighting patterns and clustering documents, NMF does not provide explicit topic labels, necessitating subject matter experts (SMEs) to assign labels manually. We present a methodology for automating topic labeling in documents clustered via NMF with automatic model determination (NMFk). By leveraging the output of NMFk and employing prompt engineering, we utilize large language models (LLMs) to generate accurate topic labels. Our case study on over 34,000 scientific abstracts on Knowledge Graphs demonstrates the effectiveness of our method in enhancing knowledge management and document organization.
Binary Bleed: Fast Distributed and Parallel Method for Automatic Model Selection
Jul 26, 2024

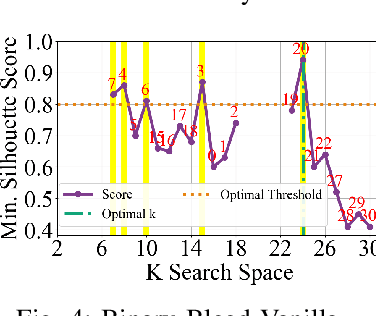
In several Machine Learning (ML) clustering and dimensionality reduction approaches, such as non-negative matrix factorization (NMF), RESCAL, and K-Means clustering, users must select a hyper-parameter k to define the number of clusters or components that yield an ideal separation of samples or clean clusters. This selection, while difficult, is crucial to avoid overfitting or underfitting the data. Several ML applications use scoring methods (e.g., Silhouette and Davies Boulding scores) to evaluate the cluster pattern stability for a specific k. The score is calculated for different trials over a range of k, and the ideal k is heuristically selected as the value before the model starts overfitting, indicated by a drop or increase in the score resembling an elbow curve plot. While the grid-search method can be used to accurately find a good k value, visiting a range of k can become time-consuming and computationally resource-intensive. In this paper, we introduce the Binary Bleed method based on binary search, which significantly reduces the k search space for these grid-search ML algorithms by truncating the target k values from the search space using a heuristic with thresholding over the scores. Binary Bleed is designed to work with single-node serial, single-node multi-processing, and distributed computing resources. In our experiments, we demonstrate the reduced search space gain over a naive sequential search of the ideal k and the accuracy of the Binary Bleed in identifying the correct k for NMFk, K-Means pyDNMFk, and pyDRESCALk with Silhouette and Davies Boulding scores. We make our implementation of Binary Bleed for the NMF algorithm available on GitHub.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
Interactive Distillation of Large Single-Topic Corpora of Scientific Papers
Sep 19, 2023



Highly specific datasets of scientific literature are important for both research and education. However, it is difficult to build such datasets at scale. A common approach is to build these datasets reductively by applying topic modeling on an established corpus and selecting specific topics. A more robust but time-consuming approach is to build the dataset constructively in which a subject matter expert (SME) handpicks documents. This method does not scale and is prone to error as the dataset grows. Here we showcase a new tool, based on machine learning, for constructively generating targeted datasets of scientific literature. Given a small initial "core" corpus of papers, we build a citation network of documents. At each step of the citation network, we generate text embeddings and visualize the embeddings through dimensionality reduction. Papers are kept in the dataset if they are "similar" to the core or are otherwise pruned through human-in-the-loop selection. Additional insight into the papers is gained through sub-topic modeling using SeNMFk. We demonstrate our new tool for literature review by applying it to two different fields in machine learning.
Robust Adversarial Defense by Tensor Factorization
Sep 03, 2023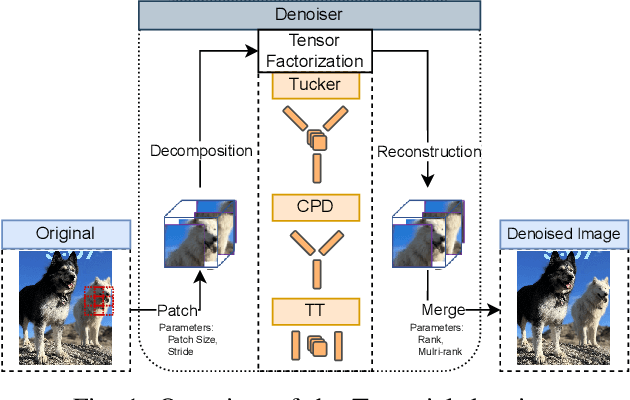
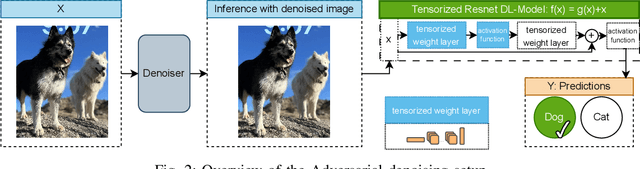
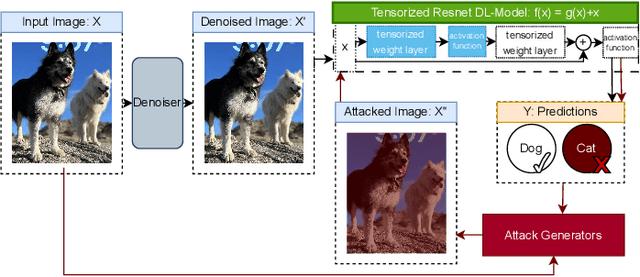
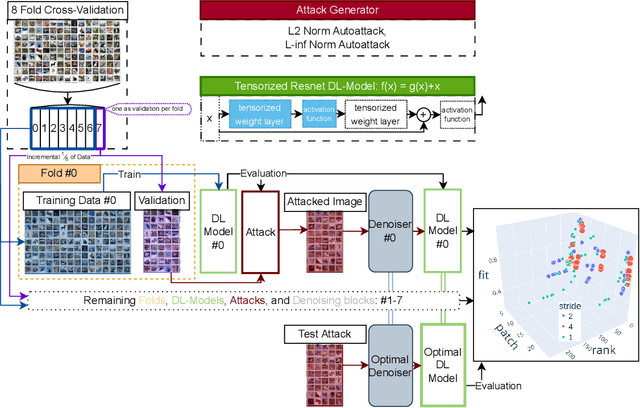
As machine learning techniques become increasingly prevalent in data analysis, the threat of adversarial attacks has surged, necessitating robust defense mechanisms. Among these defenses, methods exploiting low-rank approximations for input data preprocessing and neural network (NN) parameter factorization have shown potential. Our work advances this field further by integrating the tensorization of input data with low-rank decomposition and tensorization of NN parameters to enhance adversarial defense. The proposed approach demonstrates significant defense capabilities, maintaining robust accuracy even when subjected to the strongest known auto-attacks. Evaluations against leading-edge robust performance benchmarks reveal that our results not only hold their ground against the best defensive methods available but also exceed all current defense strategies that rely on tensor factorizations. This study underscores the potential of integrating tensorization and low-rank decomposition as a robust defense against adversarial attacks in machine learning.