 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Linguistic Diversity in Embodied AI Datasets
Jan 06, 2026Language plays a critical role in Vision-Language-Action (VLA) models, yet the linguistic characteristics of the datasets used to train and evaluate these systems remain poorly documented. In this work, we present a systematic dataset audit of several widely used VLA corpora, aiming to characterize what kinds of instructions these datasets actually contain and how much linguistic variety they provide. We quantify instruction language along complementary dimensions-including lexical variety, duplication and overlap, semantic similarity, and syntactic complexity. Our analysis shows that many datasets rely on highly repetitive, template-like commands with limited structural variation, yielding a narrow distribution of instruction forms. We position these findings as descriptive documentation of the language signal available in current VLA training and evaluation data, intended to support more detailed dataset reporting, more principled dataset selection, and targeted curation or augmentation strategies that broaden language coverage.
Temporal and Semantic Evaluation Metrics for Foundation Models in Post-Hoc Analysis of Robotic Sub-tasks
Mar 25, 2024Recent works in Task and Motion Planning (TAMP) show that training control policies on language-supervised robot trajectories with quality labeled data markedly improves agent task success rates. However, the scarcity of such data presents a significant hurdle to extending these methods to general use cases. To address this concern, we present an automated framework to decompose trajectory data into temporally bounded and natural language-based descriptive sub-tasks by leveraging recent prompting strategies for Foundation Models (FMs) including both Large Language Models (LLMs) and Vision Language Models (VLMs). Our framework provides both time-based and language-based descriptions for lower-level sub-tasks that comprise full trajectories. To rigorously evaluate the quality of our automatic labeling framework, we contribute an algorithm SIMILARITY to produce two novel metrics, temporal similarity and semantic similarity. The metrics measure the temporal alignment and semantic fidelity of language descriptions between two sub-task decompositions, namely an FM sub-task decomposition prediction and a ground-truth sub-task decomposition. We present scores for temporal similarity and semantic similarity above 90%, compared to 30% of a randomized baseline, for multiple robotic environments, demonstrating the effectiveness of our proposed framework. Our results enable building diverse, large-scale, language-supervised datasets for improved robotic TAMP.
Cost-effective Machine Learning Inference Offload for Edge Computing
Dec 07, 2020
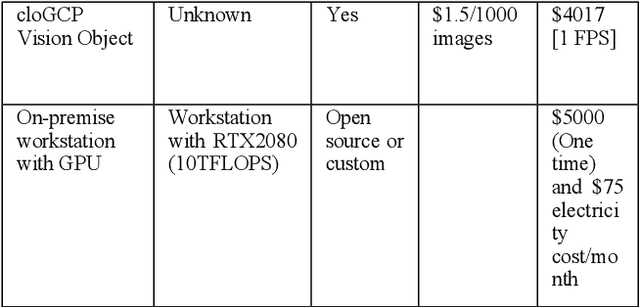
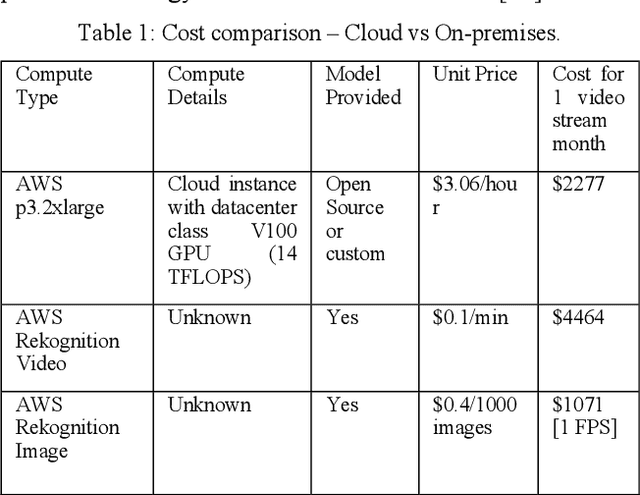
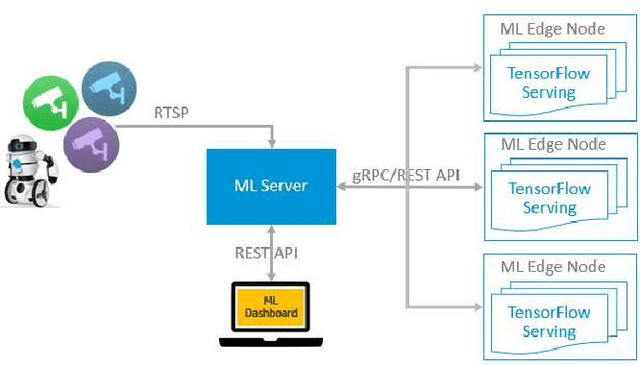
Computing at the edge is increasingly important since a massive amount of data is generated. This poses challenges in transporting all that data to the remote data centers and cloud, where they can be processed and analyzed. On the other hand, harnessing the edge data is essential for offering data-driven and machine learning-based applications, if the challenges, such as device capabilities, connectivity, and heterogeneity can be mitigated. Machine learning applications are very compute-intensive and require processing of large amount of data. However, edge devices are often resources-constrained, in terms of compute resources, power, storage, and network connectivity. Hence, limiting their potential to run efficiently and accurately state-of-the art deep neural network (DNN) models, which are becoming larger and more complex. This paper proposes a novel offloading mechanism by leveraging installed-base on-premises (edge) computational resources. The proposed mechanism allows the edge devices to offload heavy and compute-intensive workloads to edge nodes instead of using remote cloud. Our offloading mechanism has been prototyped and tested with state-of-the art person and object detection DNN models for mobile robots and video surveillance applications. The performance shows a significant gain compared to cloud-based offloading strategies in terms of accuracy and latency.