 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Distributional Shifts in Text: The Advantage of Language Model-Based Embeddings
Dec 04, 2023



An essential part of monitoring machine learning models in production is measuring input and output data drift. In this paper, we present a system for measuring distributional shifts in natural language data and highlight and investigate the potential advantage of using large language models (LLMs) for this problem. Recent advancements in LLMs and their successful adoption in different domains indicate their effectiveness in capturing semantic relationships for solving various natural language processing problems. The power of LLMs comes largely from the encodings (embeddings) generated in the hidden layers of the corresponding neural network. First we propose a clustering-based algorithm for measuring distributional shifts in text data by exploiting such embeddings. Then we study the effectiveness of our approach when applied to text embeddings generated by both LLMs and classical embedding algorithms. Our experiments show that general-purpose LLM-based embeddings provide a high sensitivity to data drift compared to other embedding methods. We propose drift sensitivity as an important evaluation metric to consider when comparing language models. Finally, we present insights and lessons learned from deploying our framework as part of the Fiddler ML Monitoring platform over a period of 18 months.
Cost-effective Machine Learning Inference Offload for Edge Computing
Dec 07, 2020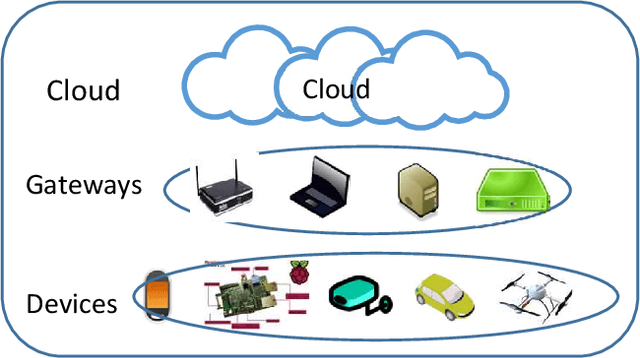
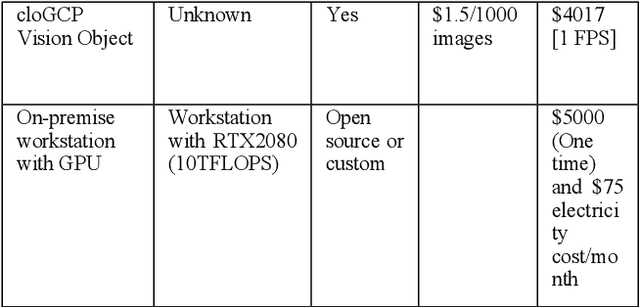
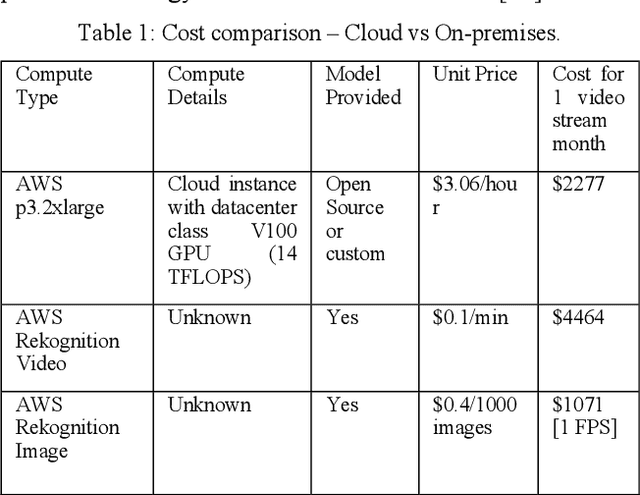
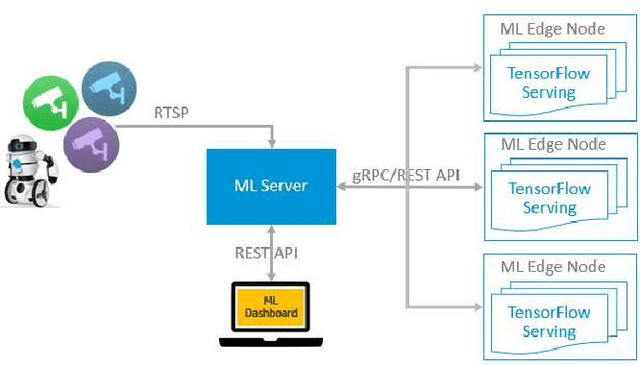
Computing at the edge is increasingly important since a massive amount of data is generated. This poses challenges in transporting all that data to the remote data centers and cloud, where they can be processed and analyzed. On the other hand, harnessing the edge data is essential for offering data-driven and machine learning-based applications, if the challenges, such as device capabilities, connectivity, and heterogeneity can be mitigated. Machine learning applications are very compute-intensive and require processing of large amount of data. However, edge devices are often resources-constrained, in terms of compute resources, power, storage, and network connectivity. Hence, limiting their potential to run efficiently and accurately state-of-the art deep neural network (DNN) models, which are becoming larger and more complex. This paper proposes a novel offloading mechanism by leveraging installed-base on-premises (edge) computational resources. The proposed mechanism allows the edge devices to offload heavy and compute-intensive workloads to edge nodes instead of using remote cloud. Our offloading mechanism has been prototyped and tested with state-of-the art person and object detection DNN models for mobile robots and video surveillance applications. The performance shows a significant gain compared to cloud-based offloading strategies in terms of accuracy and latency.