 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Distributional Shifts in Text: The Advantage of Language Model-Based Embeddings
Dec 04, 2023



An essential part of monitoring machine learning models in production is measuring input and output data drift. In this paper, we present a system for measuring distributional shifts in natural language data and highlight and investigate the potential advantage of using large language models (LLMs) for this problem. Recent advancements in LLMs and their successful adoption in different domains indicate their effectiveness in capturing semantic relationships for solving various natural language processing problems. The power of LLMs comes largely from the encodings (embeddings) generated in the hidden layers of the corresponding neural network. First we propose a clustering-based algorithm for measuring distributional shifts in text data by exploiting such embeddings. Then we study the effectiveness of our approach when applied to text embeddings generated by both LLMs and classical embedding algorithms. Our experiments show that general-purpose LLM-based embeddings provide a high sensitivity to data drift compared to other embedding methods. We propose drift sensitivity as an important evaluation metric to consider when comparing language models. Finally, we present insights and lessons learned from deploying our framework as part of the Fiddler ML Monitoring platform over a period of 18 months.
Fair Inputs and Fair Outputs: The Incompatibility of Fairness in Privacy and Accuracy
May 24, 2020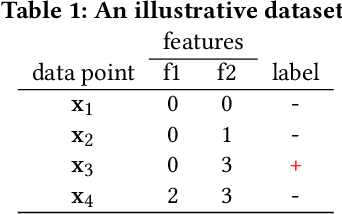
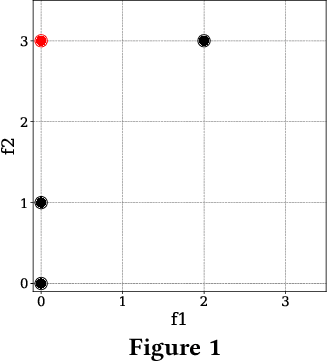

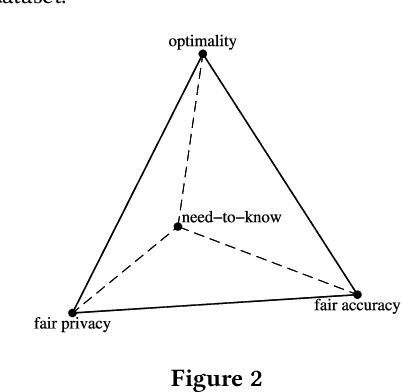
Fairness concerns about algorithmic decision-making systems have been mainly focused on the outputs (e.g., the accuracy of a classifier across individuals or groups). However, one may additionally be concerned with fairness in the inputs. In this paper, we propose and formulate two properties regarding the inputs of (features used by) a classifier. In particular, we claim that fair privacy (whether individuals are all asked to reveal the same information) and need-to-know (whether users are only asked for the minimal information required for the task at hand) are desirable properties of a decision system. We explore the interaction between these properties and fairness in the outputs (fair prediction accuracy). We show that for an optimal classifier these three properties are in general incompatible, and we explain what common properties of data make them incompatible. Finally we provide an algorithm to verify if the trade-off between the three properties exists in a given dataset, and use the algorithm to show that this trade-off is common in real data.
Fighting Fire with Fire: Using Antidote Data to Improve Polarization and Fairness of Recommender Systems
Jan 14, 2019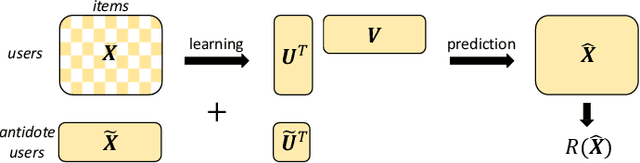
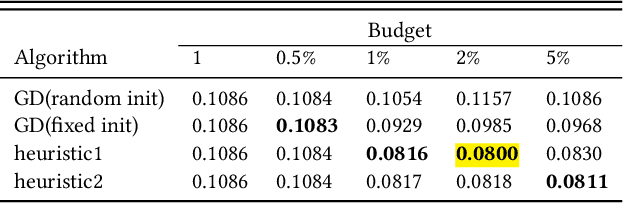
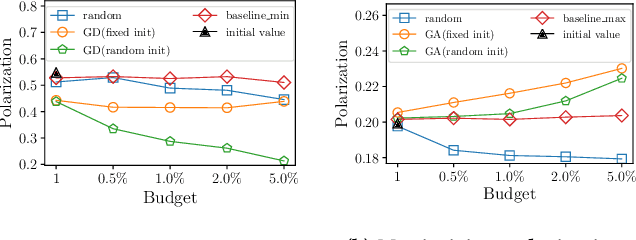
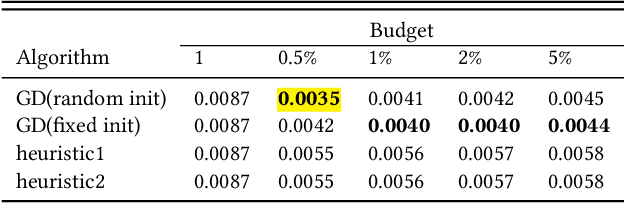
The increasing role of recommender systems in many aspects of society makes it essential to consider how such systems may impact social good. Various modifications to recommendation algorithms have been proposed to improve their performance for specific socially relevant measures. However, previous proposals are often not easily adapted to different measures, and they generally require the ability to modify either existing system inputs, the system's algorithm, or the system's outputs. As an alternative, in this paper we introduce the idea of improving the social desirability of recommender system outputs by adding more data to the input, an approach we view as as providing `antidote' data to the system. We formalize the antidote data problem, and develop optimization-based solutions. We take as our model system the matrix factorization approach to recommendation, and we propose a set of measures to capture the polarization or fairness of recommendations. We then show how to generate antidote data for each measure, pointing out a number of computational efficiencies, and discuss the impact on overall system accuracy. Our experiments show that a modest budget for antidote data can lead to significant improvements in the polarization or fairness of recommendations.