 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFELearning: Enable Backdoor Detectability In Federated Learning With Secure Aggregation
Feb 04, 2021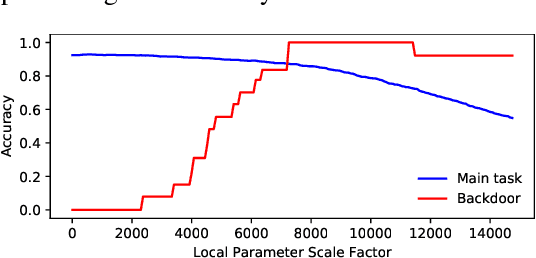

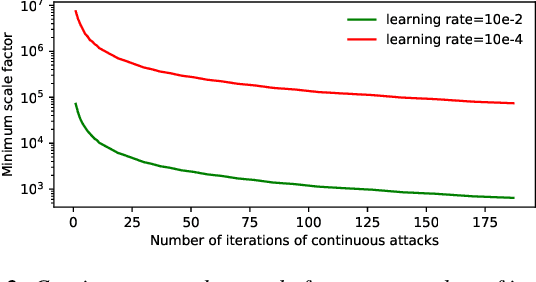

For model privacy, local model parameters in federated learning shall be obfuscated before sent to the remote aggregator. This technique is referred to as \emph{secure aggregation}. However, secure aggregation makes model poisoning attacks, e.g., to insert backdoors, more convenient given existing anomaly detection methods mostly require access to plaintext local models. This paper proposes SAFELearning which supports backdoor detection for secure aggregation. We achieve this through two new primitives - \emph{oblivious random grouping (ORG)} and \emph{partial parameter disclosure (PPD)}. ORG partitions participants into one-time random subgroups with group configurations oblivious to participants; PPD allows secure partial disclosure of aggregated subgroup models for anomaly detection without leaking individual model privacy. SAFELearning is able to significantly reduce backdoor model accuracy without jeopardizing the main task accuracy under common backdoor strategies. Extensive experiments show SAFELearning reduces backdoor accuracy from $100\%$ to $8.2\%$ for ResNet-18 over CIFAR-10 when $10\%$ participants are malicious.
Cost-effective Machine Learning Inference Offload for Edge Computing
Dec 07, 2020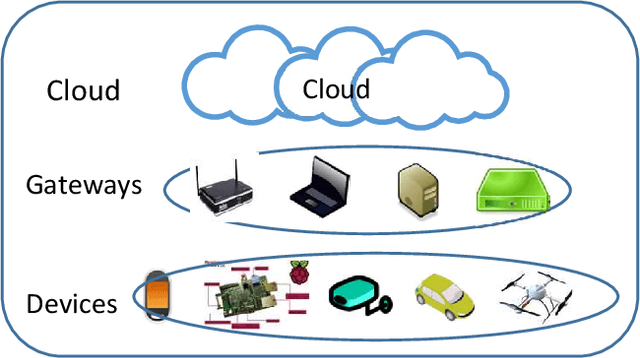
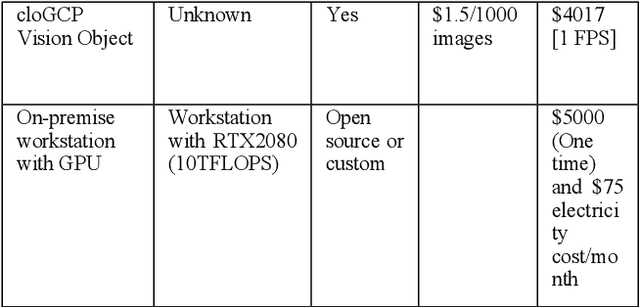
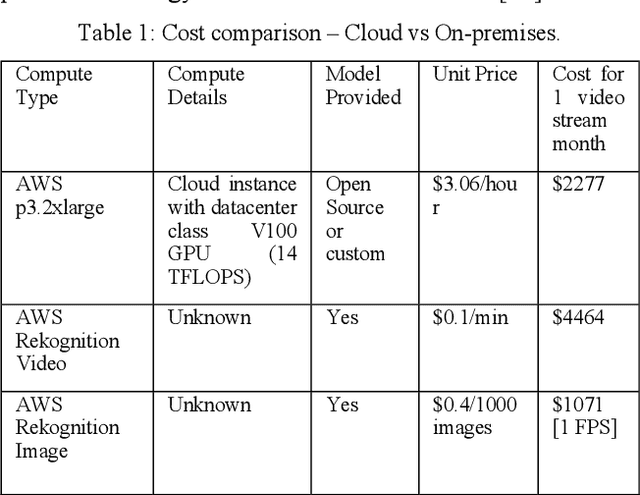
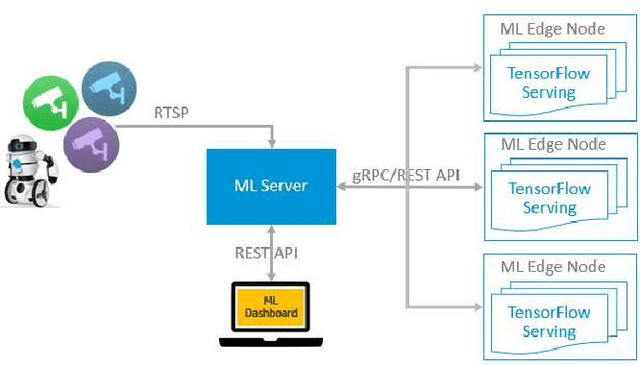
Computing at the edge is increasingly important since a massive amount of data is generated. This poses challenges in transporting all that data to the remote data centers and cloud, where they can be processed and analyzed. On the other hand, harnessing the edge data is essential for offering data-driven and machine learning-based applications, if the challenges, such as device capabilities, connectivity, and heterogeneity can be mitigated. Machine learning applications are very compute-intensive and require processing of large amount of data. However, edge devices are often resources-constrained, in terms of compute resources, power, storage, and network connectivity. Hence, limiting their potential to run efficiently and accurately state-of-the art deep neural network (DNN) models, which are becoming larger and more complex. This paper proposes a novel offloading mechanism by leveraging installed-base on-premises (edge) computational resources. The proposed mechanism allows the edge devices to offload heavy and compute-intensive workloads to edge nodes instead of using remote cloud. Our offloading mechanism has been prototyped and tested with state-of-the art person and object detection DNN models for mobile robots and video surveillance applications. The performance shows a significant gain compared to cloud-based offloading strategies in terms of accuracy and latency.
Adaptive Federated Learning in Resource Constrained Edge Computing Systems
Aug 02, 2018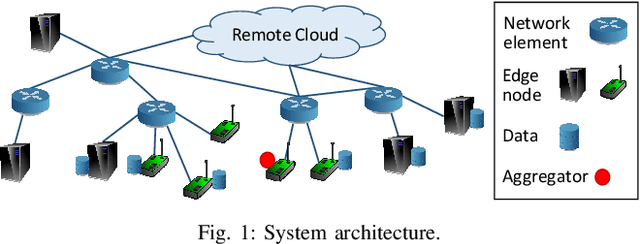
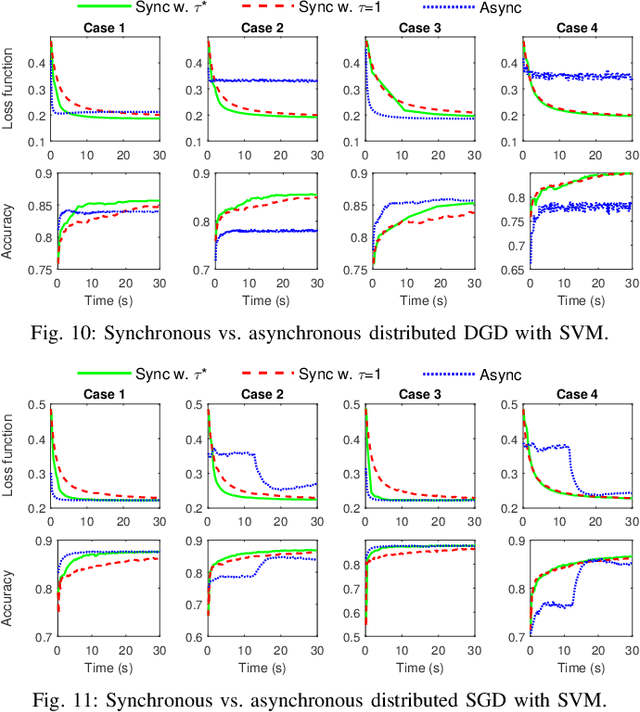
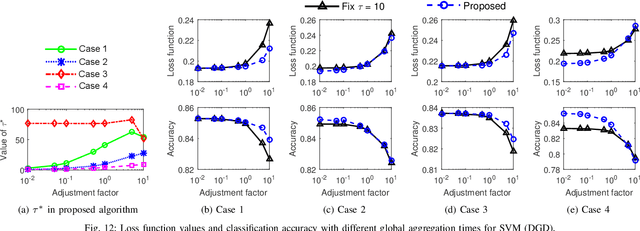
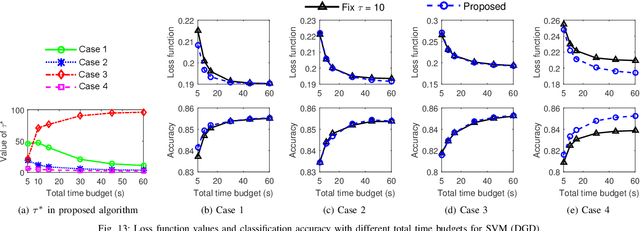
Emerging technologies and applications including Internet of Things (IoT), social networking, and crowd-sourcing generate large amounts of data at the network edge. Machine learning models are often built from the collected data, to enable the detection, classification, and prediction of future events. Due to bandwidth, storage, and privacy concerns, it is often impractical to send all the data to a centralized location. In this paper, we consider the problem of learning model parameters from data distributed across multiple edge nodes, without sending raw data to a centralized place. Our focus is on a generic class of machine learning models that are trained using gradient-descent based approaches. We analyze the convergence bound of distributed gradient descent from a theoretical point of view, based on which we propose a control algorithm that determines the best trade-off between local update and global parameter aggregation to minimize the loss function under a given resource budget. The performance of the proposed algorithm is evaluated via extensive experiments with real datasets, both on a networked prototype system and in a larger-scale simulated environment. The experimentation results show that our proposed approach performs near to the optimum with various machine learning models and different data distributions.