 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
Fisher-Informed Parameterwise Aggregation for Federated Learning with Heterogeneous Data
Jan 20, 2026Federated learning aggregates model updates from distributed clients, but standard first order methods such as FedAvg apply the same scalar weight to all parameters from each client. Under non-IID data, these uniformly weighted updates can be strongly misaligned across clients, causing client drift and degrading the global model. Here we propose Fisher-Informed Parameterwise Aggregation (FIPA), a second-order aggregation method that replaces client-level scalar weights with parameter-specific Fisher Information Matrix (FIM) weights, enabling true parameter-level scaling that captures how each client's data uniquely influences different parameters. With low-rank approximation, FIPA remains communication- and computation-efficient. Across nonlinear function regression, PDE learning, and image classification, FIPA consistently improves over averaging-based aggregation, and can be effectively combined with state-of-the-art client-side optimization algorithms to further improve image classification accuracy. These results highlight the benefits of FIPA for federated learning under heterogeneous data distributions.
Time-varying Mixing Matrix Design for Energy-efficient Decentralized Federated Learning
Dec 30, 2025We consider the design of mixing matrices to minimize the operation cost for decentralized federated learning (DFL) in wireless networks, with focus on minimizing the maximum per-node energy consumption. As a critical hyperparameter for DFL, the mixing matrix controls both the convergence rate and the needs of agent-to-agent communications, and has thus been studied extensively. However, existing designs mostly focused on minimizing the communication time, leaving open the minimization of per-node energy consumption that is critical for energy-constrained devices. This work addresses this gap through a theoretically-justified solution for mixing matrix design that aims at minimizing the maximum per-node energy consumption until convergence, while taking into account the broadcast nature of wireless communications. Based on a novel convergence theorem that allows arbitrarily time-varying mixing matrices, we propose a multi-phase design framework that activates time-varying communication topologies under optimized budgets to trade off the per-iteration energy consumption and the convergence rate while balancing the energy consumption across nodes. Our evaluations based on real data have validated the efficacy of the proposed solution in combining the low energy consumption of sparse mixing matrices and the fast convergence of dense mixing matrices.
Optimizing Resource Allocation for Geographically-Distributed Inference by Large Language Models
Dec 26, 2025Large language models have demonstrated extraordinary performance in many AI tasks but are expensive to use, even after training, due to their requirement of high-end GPUs. Recently, a distributed system called PETALS was developed to lower the barrier for deploying LLMs by splitting the model blocks across multiple servers with low-end GPUs distributed over the Internet, which was much faster than swapping the model parameters between the GPU memory and other cheaper but slower local storage media. However, the performance of such a distributed system critically depends on the resource allocation, and how to do so optimally remains unknown. In this work, we present the first systematic study of the resource allocation problem in distributed LLM inference, with focus on two important decisions: block placement and request routing. Our main results include: experimentally validated performance models that can predict the inference performance under given block placement and request routing decisions, a formulation of the offline optimization of block placement and request routing as a mixed integer linear programming problem together with the NP-hardness proof and a polynomial-complexity algorithm with guaranteed performance, and an adaptation of the offline algorithm for the online setting with the same performance guarantee under bounded load. Through both experiments and experimentally-validated simulations, we have verified that the proposed solution can substantially reduce the inference time compared to the state-of-the-art solution in diverse settings with geographically-distributed servers. As a byproduct, we have also developed a light-weighted CPU-only simulator capable of predicting the performance of distributed LLM inference on GPU servers, which can evaluate large deployments and facilitate future research for researchers with limited GPU access.
Communication Optimization for Decentralized Learning atop Bandwidth-limited Edge Networks
Apr 16, 2025Decentralized federated learning (DFL) is a promising machine learning paradigm for bringing artificial intelligence (AI) capabilities to the network edge. Running DFL on top of edge networks, however, faces severe performance challenges due to the extensive parameter exchanges between agents. Most existing solutions for these challenges were based on simplistic communication models, which cannot capture the case of learning over a multi-hop bandwidth-limited network. In this work, we address this problem by jointly designing the communication scheme for the overlay network formed by the agents and the mixing matrix that controls the communication demands between the agents. By carefully analyzing the properties of our problem, we cast each design problem into a tractable optimization and develop an efficient algorithm with guaranteed performance. Our evaluations based on real topology and data show that the proposed algorithm can reduce the total training time by over $80\%$ compared to the baseline without sacrificing accuracy, while significantly improving the computational efficiency over the state of the art.
Qwen2.5-Omni Technical Report
Mar 26, 2025



In this report, we present Qwen2.5-Omni, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. To enable the streaming of multimodal information inputs, both audio and visual encoders utilize a block-wise processing approach. To synchronize the timestamps of video inputs with audio, we organize the audio and video sequentially in an interleaved manner and propose a novel position embedding approach, named TMRoPE(Time-aligned Multimodal RoPE). To concurrently generate text and speech while avoiding interference between the two modalities, we propose \textbf{Thinker-Talker} architecture. In this framework, Thinker functions as a large language model tasked with text generation, while Talker is a dual-track autoregressive model that directly utilizes the hidden representations from the Thinker to produce audio tokens as output. Both the Thinker and Talker models are designed to be trained and inferred in an end-to-end manner. For decoding audio tokens in a streaming manner, we introduce a sliding-window DiT that restricts the receptive field, aiming to reduce the initial package delay. Qwen2.5-Omni is comparable with the similarly sized Qwen2.5-VL and outperforms Qwen2-Audio. Furthermore, Qwen2.5-Omni achieves state-of-the-art performance on multimodal benchmarks like Omni-Bench. Notably, Qwen2.5-Omni's performance in end-to-end speech instruction following is comparable to its capabilities with text inputs, as evidenced by benchmarks such as MMLU and GSM8K. As for speech generation, Qwen2.5-Omni's streaming Talker outperforms most existing streaming and non-streaming alternatives in robustness and naturalness.
AI-assisted Knowledge Discovery in Biomedical Literature to Support Decision-making in Precision Oncology
Dec 12, 2024
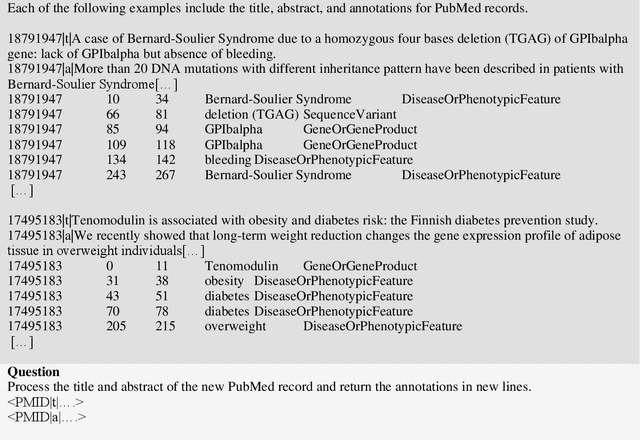
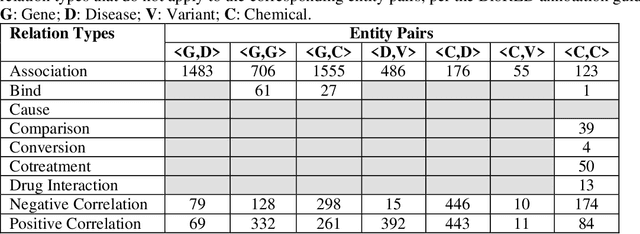
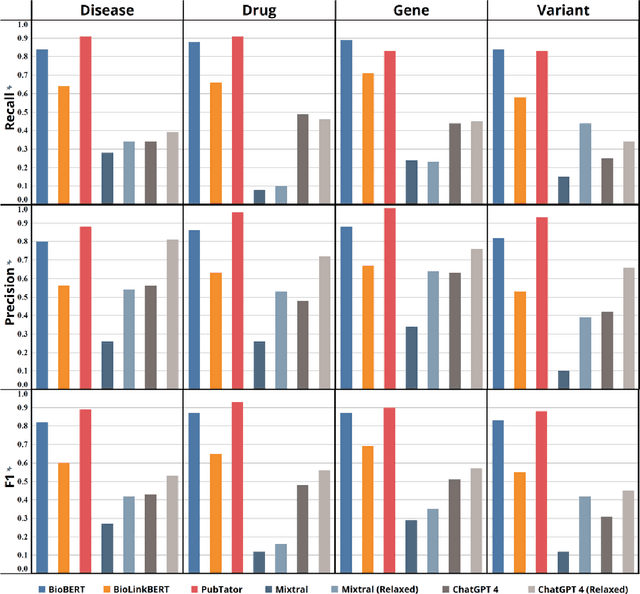
The delivery of appropriate targeted therapies to cancer patients requires the complete analysis of the molecular profiling of tumors and the patient's clinical characteristics in the context of existing knowledge and recent findings described in biomedical literature and several other sources. We evaluated the potential contributions of specific natural language processing solutions to support knowledge discovery from biomedical literature. Two models from the Bidirectional Encoder Representations from Transformers (BERT) family, two Large Language Models, and PubTator 3.0 were tested for their ability to support the named entity recognition (NER) and the relation extraction (RE) tasks. PubTator 3.0 and the BioBERT model performed best in the NER task (best F1-score equal to 0.93 and 0.89, respectively), while BioBERT outperformed all other solutions in the RE task (best F1-score 0.79) and a specific use case it was applied to by recognizing nearly all entity mentions and most of the relations.
Overlay-based Decentralized Federated Learning in Bandwidth-limited Networks
Aug 08, 2024



The emerging machine learning paradigm of decentralized federated learning (DFL) has the promise of greatly boosting the deployment of artificial intelligence (AI) by directly learning across distributed agents without centralized coordination. Despite significant efforts on improving the communication efficiency of DFL, most existing solutions were based on the simplistic assumption that neighboring agents are physically adjacent in the underlying communication network, which fails to correctly capture the communication cost when learning over a general bandwidth-limited network, as encountered in many edge networks. In this work, we address this gap by leveraging recent advances in network tomography to jointly design the communication demands and the communication schedule for overlay-based DFL in bandwidth-limited networks without requiring explicit cooperation from the underlying network. By carefully analyzing the structure of our problem, we decompose it into a series of optimization problems that can each be solved efficiently, to collectively minimize the total training time. Extensive data-driven simulations show that our solution can significantly accelerate DFL in comparison with state-of-the-art designs.
Active Learning for WBAN-based Health Monitoring
Aug 05, 2024
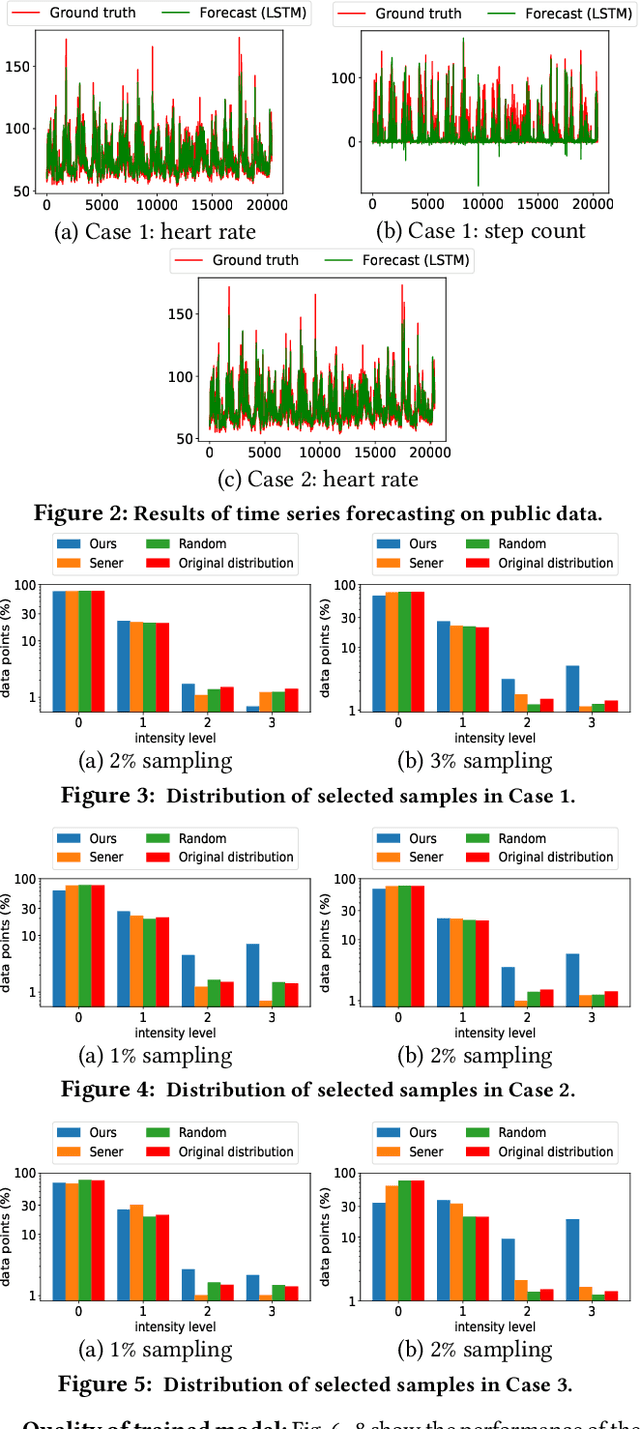
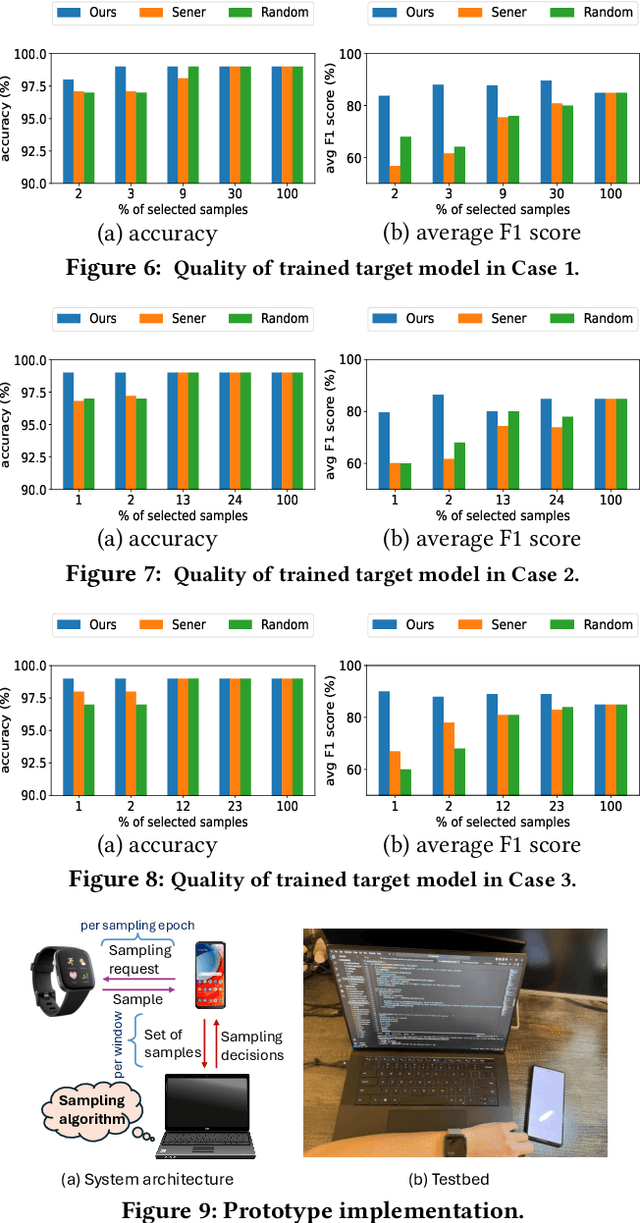

We consider a novel active learning problem motivated by the need of learning machine learning models for health monitoring in wireless body area network (WBAN). Due to the limited resources at body sensors, collecting each unlabeled sample in WBAN incurs a nontrivial cost. Moreover, training health monitoring models typically requires labels indicating the patient's health state that need to be generated by healthcare professionals, which cannot be obtained at the same pace as data collection. These challenges make our problem fundamentally different from classical active learning, where unlabeled samples are free and labels can be queried in real time. To handle these challenges, we propose a two-phased active learning method, consisting of an online phase where a coreset construction algorithm is proposed to select a subset of unlabeled samples based on their noisy predictions, and an offline phase where the selected samples are labeled to train the target model. The samples selected by our algorithm are proved to yield a guaranteed error in approximating the full dataset in evaluating the loss function. Our evaluation based on real health monitoring data and our own experimentation demonstrates that our solution can drastically save the data curation cost without sacrificing the quality of the target model.
Energy-efficient Decentralized Learning via Graph Sparsification
Jan 05, 2024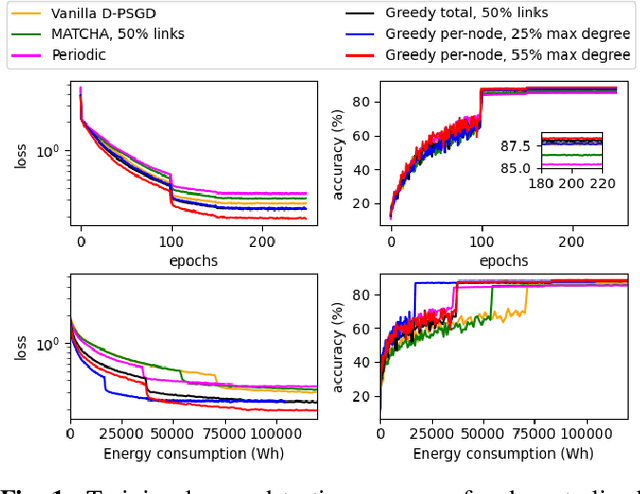
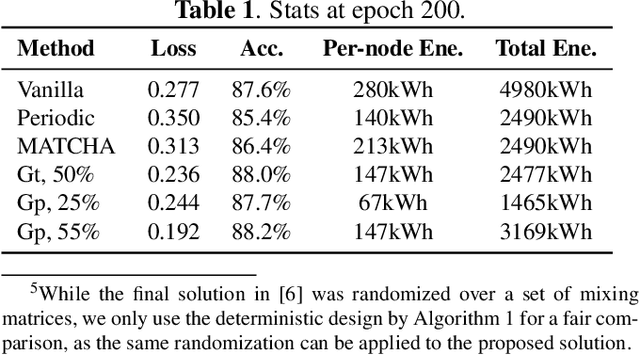
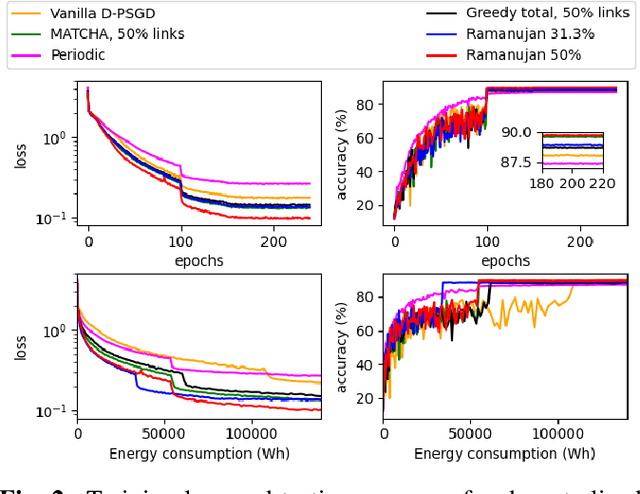
This work aims at improving the energy efficiency of decentralized learning by optimizing the mixing matrix, which controls the communication demands during the learning process. Through rigorous analysis based on a state-of-the-art decentralized learning algorithm, the problem is formulated as a bi-level optimization, with the lower level solved by graph sparsification. A solution with guaranteed performance is proposed for the special case of fully-connected base topology and a greedy heuristic is proposed for the general case. Simulations based on real topology and dataset show that the proposed solution can lower the energy consumption at the busiest node by 54%-76% while maintaining the quality of the trained model.