 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-varying Mixing Matrix Design for Energy-efficient Decentralized Federated Learning
Dec 30, 2025We consider the design of mixing matrices to minimize the operation cost for decentralized federated learning (DFL) in wireless networks, with focus on minimizing the maximum per-node energy consumption. As a critical hyperparameter for DFL, the mixing matrix controls both the convergence rate and the needs of agent-to-agent communications, and has thus been studied extensively. However, existing designs mostly focused on minimizing the communication time, leaving open the minimization of per-node energy consumption that is critical for energy-constrained devices. This work addresses this gap through a theoretically-justified solution for mixing matrix design that aims at minimizing the maximum per-node energy consumption until convergence, while taking into account the broadcast nature of wireless communications. Based on a novel convergence theorem that allows arbitrarily time-varying mixing matrices, we propose a multi-phase design framework that activates time-varying communication topologies under optimized budgets to trade off the per-iteration energy consumption and the convergence rate while balancing the energy consumption across nodes. Our evaluations based on real data have validated the efficacy of the proposed solution in combining the low energy consumption of sparse mixing matrices and the fast convergence of dense mixing matrices.
One-Shot Learning for k-SAT
Feb 10, 2025Consider a $k$-SAT formula $\Phi$ where every variable appears at most $d$ times, and let $\sigma$ be a satisfying assignment of $\Phi$ sampled proportionally to $e^{\beta m(\sigma)}$ where $m(\sigma)$ is the number of variables set to true and $\beta$ is a real parameter. Given $\Phi$ and $\sigma$, can we learn the value of $\beta$ efficiently? This problem falls into a recent line of works about single-sample ("one-shot") learning of Markov random fields. The $k$-SAT setting we consider here was recently studied by Galanis, Kandiros, and Kalavasis (SODA'24) where they showed that single-sample learning is possible when roughly $d\leq 2^{k/6.45}$ and impossible when $d\geq (k+1) 2^{k-1}$. Crucially, for their impossibility results they used the existence of unsatisfiable instances which, aside from the gap in $d$, left open the question of whether the feasibility threshold for one-shot learning is dictated by the satisfiability threshold of $k$-SAT formulas of bounded degree. Our main contribution is to answer this question negatively. We show that one-shot learning for $k$-SAT is infeasible well below the satisfiability threshold; in fact, we obtain impossibility results for degrees $d$ as low as $k^2$ when $\beta$ is sufficiently large, and bootstrap this to small values of $\beta$ when $d$ scales exponentially with $k$, via a probabilistic construction. On the positive side, we simplify the analysis of the learning algorithm and obtain significantly stronger bounds on $d$ in terms of $\beta$. In particular, for the uniform case $\beta\rightarrow 0$ that has been studied extensively in the sampling literature, our analysis shows that learning is possible under the condition $d\lesssim 2^{k/2}$. This is nearly optimal (up to constant factors) in the sense that it is known that sampling a uniformly-distributed satisfying assignment is NP-hard for $d\gtrsim 2^{k/2}$.
Energy-efficient Decentralized Learning via Graph Sparsification
Jan 05, 2024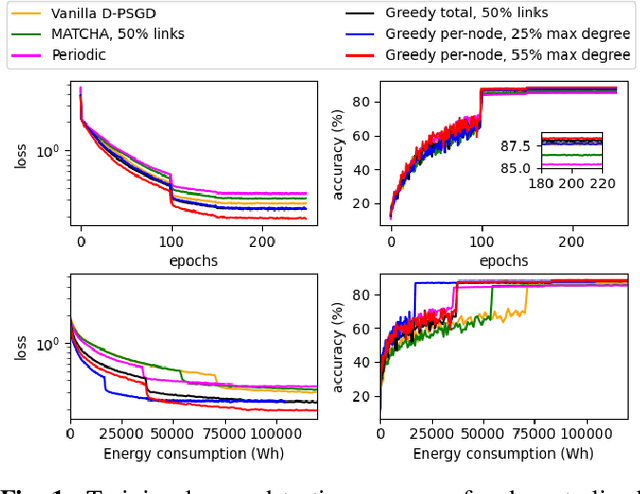
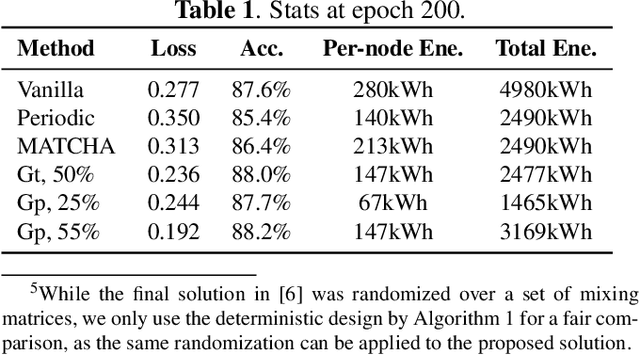
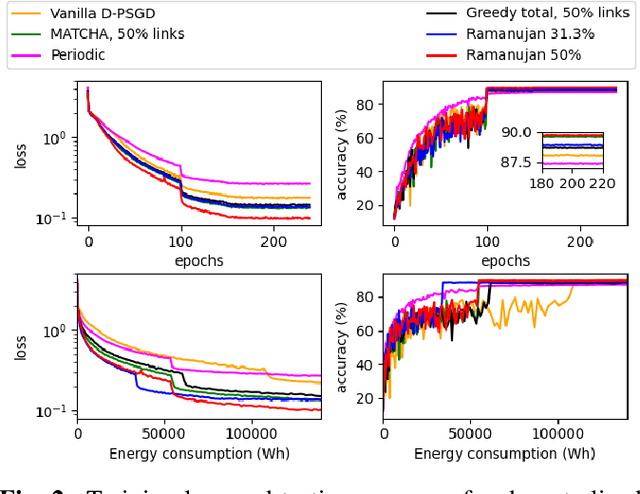
This work aims at improving the energy efficiency of decentralized learning by optimizing the mixing matrix, which controls the communication demands during the learning process. Through rigorous analysis based on a state-of-the-art decentralized learning algorithm, the problem is formulated as a bi-level optimization, with the lower level solved by graph sparsification. A solution with guaranteed performance is proposed for the special case of fully-connected base topology and a greedy heuristic is proposed for the general case. Simulations based on real topology and dataset show that the proposed solution can lower the energy consumption at the busiest node by 54%-76% while maintaining the quality of the trained model.