 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRA: Missing Modality Low-Rank Adaptation for Visual Recognition
Nov 09, 2025Pre-trained vision language models have shown remarkable performance on visual recognition tasks, but they typically assume the availability of complete multimodal inputs during both training and inference. In real-world scenarios, however, modalities may be missing due to privacy constraints, collection difficulties, or resource limitations. While previous approaches have addressed this challenge using prompt learning techniques, they fail to capture the cross-modal relationships necessary for effective multimodal visual recognition and suffer from inevitable computational overhead. In this paper, we introduce MoRA, a parameter-efficient fine-tuning method that explicitly models cross-modal interactions while maintaining modality-specific adaptations. MoRA introduces modality-common parameters between text and vision encoders, enabling bidirectional knowledge transfer. Additionally, combined with the modality-specific parameters, MoRA allows the backbone model to maintain inter-modality interaction and enable intra-modality flexibility. Extensive experiments on standard benchmarks demonstrate that MoRA achieves an average performance improvement in missing-modality scenarios by 5.24% and uses only 25.90% of the inference time compared to the SOTA method while requiring only 0.11% of trainable parameters compared to full fine-tuning.
Windsock is Dancing: Adaptive Multimodal Retrieval-Augmented Generation
Oct 26, 2025Multimodal Retrieval-Augmented Generation (MRAG) has emerged as a promising method to generate factual and up-to-date responses of Multimodal Large Language Models (MLLMs) by incorporating non-parametric knowledge from external knowledge bases. However, existing MRAG approaches suffer from static retrieval strategies, inflexible modality selection, and suboptimal utilization of retrieved information, leading to three critical challenges: determining when to retrieve, what modality to incorporate, and how to utilize retrieved information effectively. To address these challenges, we introduce Windsock, a query-dependent module making decisions on retrieval necessity and modality selection, effectively reducing computational overhead and improving response quality. Additionally, we propose Dynamic Noise-Resistance (DANCE) Instruction Tuning, an adaptive training strategy that enhances MLLMs' ability to utilize retrieved information while maintaining robustness against noise. Moreover, we adopt a self-assessment approach leveraging knowledge within MLLMs to convert question-answering datasets to MRAG training datasets. Extensive experiments demonstrate that our proposed method significantly improves the generation quality by 17.07% while reducing 8.95% retrieval times.
Sigma-Delta Neural Network Conversion on Loihi 2
May 09, 2025Neuromorphic computing aims to improve the efficiency of artificial neural networks by taking inspiration from biological neurons and leveraging temporal sparsity, spatial sparsity, and compute near/in memory. Although these approaches have shown efficiency gains, training these spiking neural networks (SNN) remains difficult. The original attempts at converting trained conventional analog neural networks (ANN) to SNNs used the rate of binary spikes to represent neuron activations. This required many simulation time steps per inference, which degraded efficiency. Intel's Loihi 2 is a neuromorphic platform that supports graded spikes which can be used to represent changes in neuron activation. In this work, we use Loihi 2's graded spikes to develop a method for converting ANN networks to spiking networks, which take advantage of temporal and spatial sparsity. We evaluated the performance of this network on Loihi 2 and compared it to NVIDIA's Jetson Xavier edge AI platform.
Disharmony: Forensics using Reverse Lighting Harmonization
Jan 17, 2025



Content generation and manipulation approaches based on deep learning methods have seen significant advancements, leading to an increased need for techniques to detect whether an image has been generated or edited. Another area of research focuses on the insertion and harmonization of objects within images. In this study, we explore the potential of using harmonization data in conjunction with a segmentation model to enhance the detection of edited image regions. These edits can be either manually crafted or generated using deep learning methods. Our findings demonstrate that this approach can effectively identify such edits. Existing forensic models often overlook the detection of harmonized objects in relation to the background, but our proposed Disharmony Network addresses this gap. By utilizing an aggregated dataset of harmonization techniques, our model outperforms existing forensic networks in identifying harmonized objects integrated into their backgrounds, and shows potential for detecting various forms of edits, including virtual try-on tasks.
KALAHash: Knowledge-Anchored Low-Resource Adaptation for Deep Hashing
Dec 27, 2024



Deep hashing has been widely used for large-scale approximate nearest neighbor search due to its storage and search efficiency. However, existing deep hashing methods predominantly rely on abundant training data, leaving the more challenging scenario of low-resource adaptation for deep hashing relatively underexplored. This setting involves adapting pre-trained models to downstream tasks with only an extremely small number of training samples available. Our preliminary benchmarks reveal that current methods suffer significant performance degradation due to the distribution shift caused by limited training samples. To address these challenges, we introduce Class-Calibration LoRA (CLoRA), a novel plug-and-play approach that dynamically constructs low-rank adaptation matrices by leveraging class-level textual knowledge embeddings. CLoRA effectively incorporates prior class knowledge as anchors, enabling parameter-efficient fine-tuning while maintaining the original data distribution. Furthermore, we propose Knowledge-Guided Discrete Optimization (KIDDO), a framework to utilize class knowledge to compensate for the scarcity of visual information and enhance the discriminability of hash codes. Extensive experiments demonstrate that our proposed method, Knowledge- Anchored Low-Resource Adaptation Hashing (KALAHash), significantly boosts retrieval performance and achieves a 4x data efficiency in low-resource scenarios.
PIFS-Rec: Process-In-Fabric-Switch for Large-Scale Recommendation System Inferences
Sep 25, 2024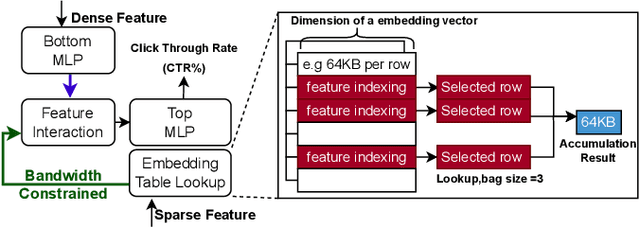
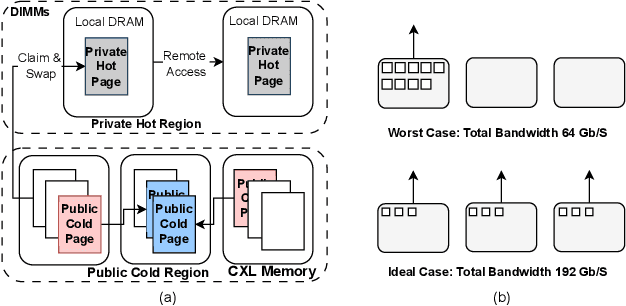
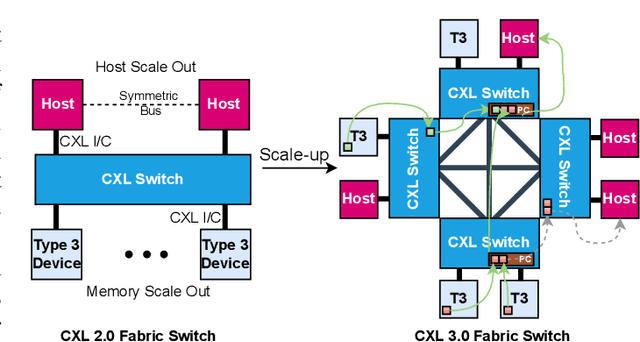

Deep Learning Recommendation Models (DLRMs) have become increasingly popular and prevalent in today's datacenters, consuming most of the AI inference cycles. The performance of DLRMs is heavily influenced by available bandwidth due to their large vector sizes in embedding tables and concurrent accesses. To achieve substantial improvements over existing solutions, novel approaches towards DLRM optimization are needed, especially, in the context of emerging interconnect technologies like CXL. This study delves into exploring CXL-enabled systems, implementing a process-in-fabric-switch (PIFS) solution to accelerate DLRMs while optimizing their memory and bandwidth scalability. We present an in-depth characterization of industry-scale DLRM workloads running on CXL-ready systems, identifying the predominant bottlenecks in existing CXL systems. We, therefore, propose PIFS-Rec, a PIFS-based scheme that implements near-data processing through downstream ports of the fabric switch. PIFS-Rec achieves a latency that is 3.89x lower than Pond, an industry-standard CXL-based system, and also outperforms BEACON, a state-of-the-art scheme, by 2.03x.
Can Prompt Modifiers Control Bias? A Comparative Analysis of Text-to-Image Generative Models
Jun 09, 2024



It has been shown that many generative models inherit and amplify societal biases. To date, there is no uniform/systematic agreed standard to control/adjust for these biases. This study examines the presence and manipulation of societal biases in leading text-to-image models: Stable Diffusion, DALL-E 3, and Adobe Firefly. Through a comprehensive analysis combining base prompts with modifiers and their sequencing, we uncover the nuanced ways these AI technologies encode biases across gender, race, geography, and region/culture. Our findings reveal the challenges and potential of prompt engineering in controlling biases, highlighting the critical need for ethical AI development promoting diversity and inclusivity. This work advances AI ethics by not only revealing the nuanced dynamics of bias in text-to-image generation models but also by offering a novel framework for future research in controlling bias. Our contributions-panning comparative analyses, the strategic use of prompt modifiers, the exploration of prompt sequencing effects, and the introduction of a bias sensitivity taxonomy-lay the groundwork for the development of common metrics and standard analyses for evaluating whether and how future AI models exhibit and respond to requests to adjust for inherent biases.
Reimagining Sense Amplifiers: Harnessing Phase Transition Materials for Current and Voltage Sensing
Aug 30, 2023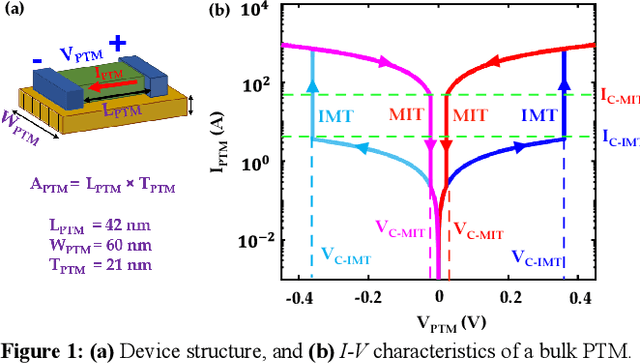
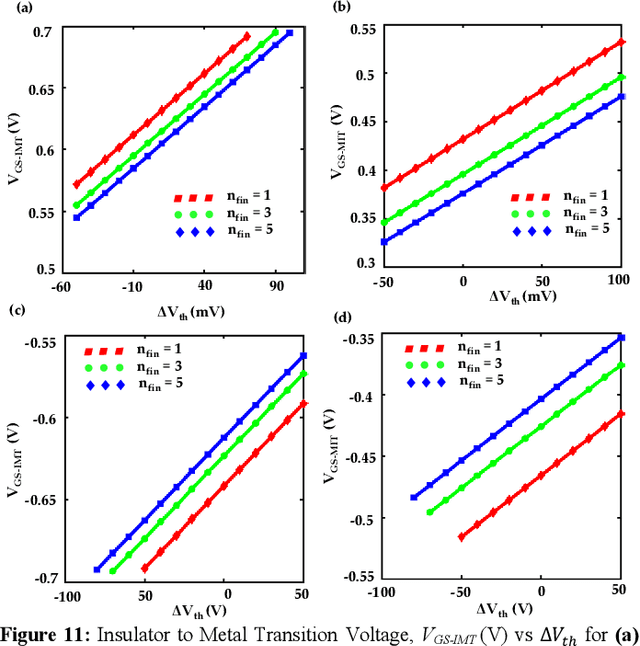
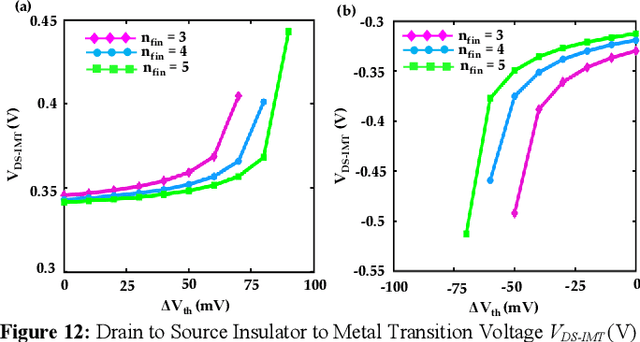
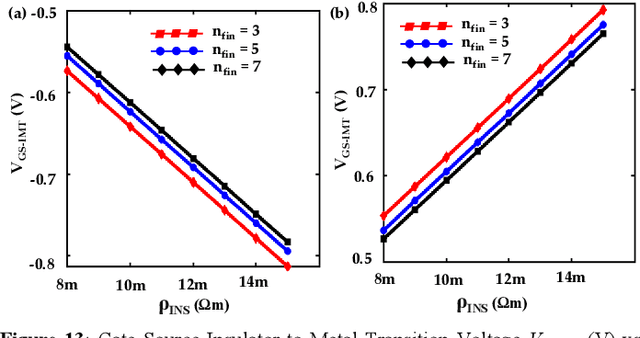
Energy-efficient sense amplifier (SA) circuits are essential for reliable detection of stored memory states in emerging memory systems. In this work, we present four novel sense amplifier (SA) topologies based on phase transition material (PTM) tailored for non-volatile memory applications. We utilize the abrupt switching and volatile hysteretic characteristics of PTMs which enables efficient and fast sensing operation in our proposed SA topologies. We provide comprehensive details of their functionality and assess how process variations impact their performance metrics. Our proposed sense amplifier topologies manifest notable performance enhancement. We achieve a ~67% reduction in sensing delay and a ~80% decrease in sensing power for current sensing. For voltage sensing, we achieve a ~75% reduction in sensing delay and a ~33% decrease in sensing power. Moreover, the proposed SA topologies exhibit improved variation robustness compared to conventional SAs. We also scrutinize the dependence of transistor mirroring window and PTM transition voltages on several device parameters to determine the optimum operating conditions and stance of tunability for each of the proposed SA topologies.
Exploiting Activation based Gradient Output Sparsity to Accelerate Backpropagation in CNNs
Sep 16, 2021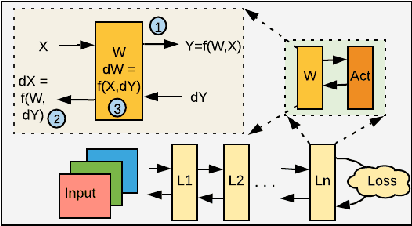
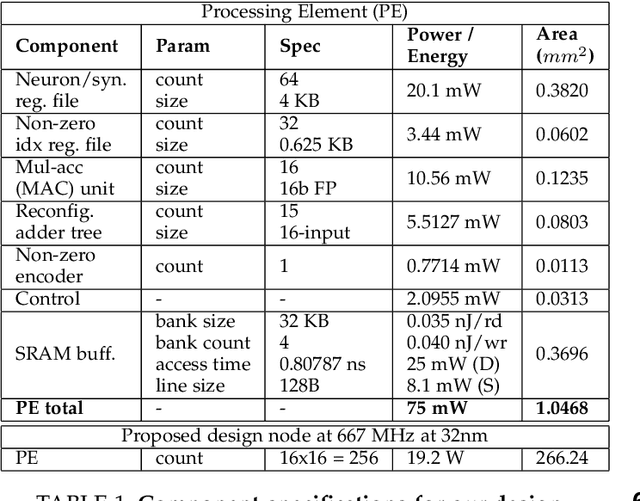
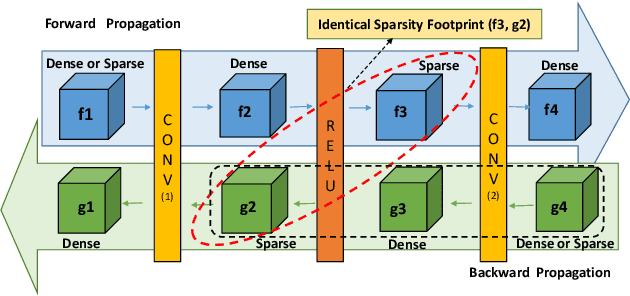
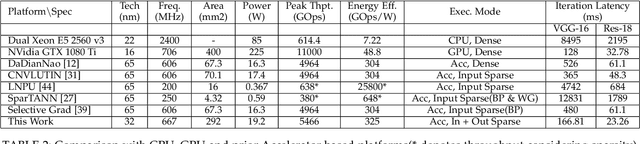
Machine/deep-learning (ML/DL) based techniques are emerging as a driving force behind many cutting-edge technologies, achieving high accuracy on computer vision workloads such as image classification and object detection. However, training these models involving large parameters is both time-consuming and energy-hogging. In this regard, several prior works have advocated for sparsity to speed up the of DL training and more so, the inference phase. This work begins with the observation that during training, sparsity in the forward and backward passes are correlated. In that context, we investigate two types of sparsity (input and output type) inherent in gradient descent-based optimization algorithms and propose a hardware micro-architecture to leverage the same. Our experimental results use five state-of-the-art CNN models on the Imagenet dataset, and show back propagation speedups in the range of 1.69$\times$ to 5.43$\times$, compared to the dense baseline execution. By exploiting sparsity in both the forward and backward passes, speedup improvements range from 1.68$\times$ to 3.30$\times$ over the sparsity-agnostic baseline execution. Our work also achieves significant reduction in training iteration time over several previously proposed dense as well as sparse accelerator based platforms, in addition to achieving order of magnitude energy efficiency improvements over GPU based execution.
Transformer-based Machine Learning for Fast SAT Solvers and Logic Synthesis
Jul 15, 2021



CNF-based SAT and MaxSAT solvers are central to logic synthesis and verification systems. The increasing popularity of these constraint problems in electronic design automation encourages studies on different SAT problems and their properties for further computational efficiency. There has been both theoretical and practical success of modern Conflict-driven clause learning SAT solvers, which allows solving very large industrial instances in a relatively short amount of time. Recently, machine learning approaches provide a new dimension to solving this challenging problem. Neural symbolic models could serve as generic solvers that can be specialized for specific domains based on data without any changes to the structure of the model. In this work, we propose a one-shot model derived from the Transformer architecture to solve the MaxSAT problem, which is the optimization version of SAT where the goal is to satisfy the maximum number of clauses. Our model has a scale-free structure which could process varying size of instances. We use meta-path and self-attention mechanism to capture interactions among homogeneous nodes. We adopt cross-attention mechanisms on the bipartite graph to capture interactions among heterogeneous nodes. We further apply an iterative algorithm to our model to satisfy additional clauses, enabling a solution approaching that of an exact-SAT problem. The attention mechanisms leverage the parallelism for speedup. Our evaluation indicates improved speedup compared to heuristic approaches and improved completion rate compared to machine learning approaches.