 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIFS-Rec: Process-In-Fabric-Switch for Large-Scale Recommendation System Inferences
Paper and Code
Sep 25, 2024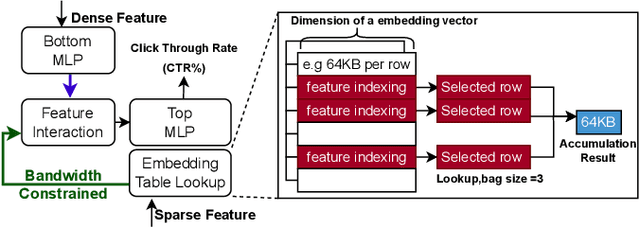
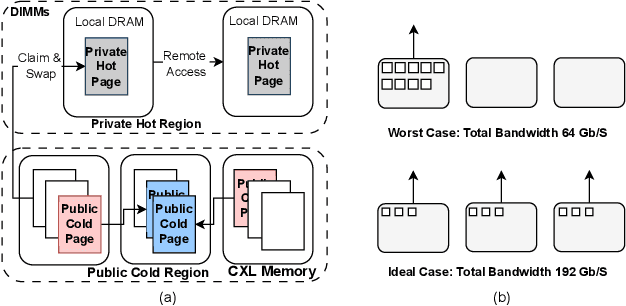
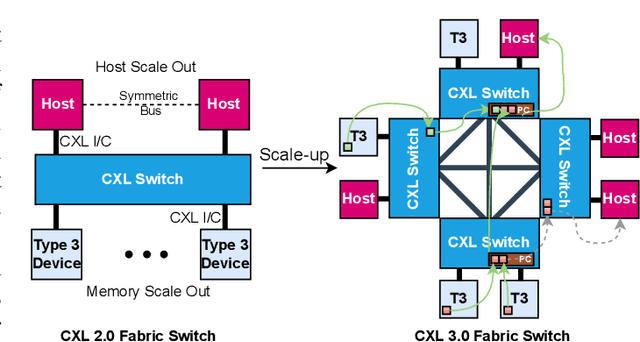

Deep Learning Recommendation Models (DLRMs) have become increasingly popular and prevalent in today's datacenters, consuming most of the AI inference cycles. The performance of DLRMs is heavily influenced by available bandwidth due to their large vector sizes in embedding tables and concurrent accesses. To achieve substantial improvements over existing solutions, novel approaches towards DLRM optimization are needed, especially, in the context of emerging interconnect technologies like CXL. This study delves into exploring CXL-enabled systems, implementing a process-in-fabric-switch (PIFS) solution to accelerate DLRMs while optimizing their memory and bandwidth scalability. We present an in-depth characterization of industry-scale DLRM workloads running on CXL-ready systems, identifying the predominant bottlenecks in existing CXL systems. We, therefore, propose PIFS-Rec, a PIFS-based scheme that implements near-data processing through downstream ports of the fabric switch. PIFS-Rec achieves a latency that is 3.89x lower than Pond, an industry-standard CXL-based system, and also outperforms BEACON, a state-of-the-art scheme, by 2.03x.