 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymVLM: Asymmetric Token Pruning for Efficient Vision-Language Model Inference
May 28, 2026Vision-Language Models (VLMs) process thousands of visual tokens per image alongside comparatively few text tokens, yet existing compression methods treat both modalities uniformly. We observe that the two modalities have fundamentally different properties: vision tokens are spatially redundant and dominate prefill, while text tokens are causally dependent and accumulate during decoding. Based on this asymmetry, we propose and empirically evaluate AsymVLM, which applies aggressive pruning to vision tokens before prefill using a learned importance scorer with per-sample adaptive budgeting, and temporal threshold-based eviction to text tokens only when they exceed a fixed budget. Our experiments indicate that AsymVLM achieves the highest FLOPs savings (up to 54%) among state-of-the-art methods while outperforming existing approaches by 2--3% on document and chart understanding tasks where visual information is spatially localized and query-specific, and maintaining competitive accuracy on holistic benchmarks. In text-dominated scenarios, our eviction strategy substantially outperforms standard LLM cache compression methods by adapting to the short-context nature of VLM.
Parallel Context Compaction for Long-Horizon LLM Agent Serving
May 22, 2026Long-horizon LLM agents accumulate growing conversation histories that eventually exceed the model's context window. Context compaction via LLM-based summarization keeps the conversation bounded, but summarization is inherently lossy and the blocking call stalls agent inference for tens of seconds. Moreover, the operator has no fine-grained control over summary volume since prompt instructions are largely ignored, and as context grows, both the amount of output tokens the model produces and the information it retains fluctuate substantially from run to run, making the agent's retained knowledge unpredictable across runs. We introduce \textbf{parallel compaction} for long-horizon agentic flows and characterize it against the sequential synchronous baseline across four backbones spanning 8B to 120B parameters, mixing dense and MoE architectures with reasoning and non-reasoning models, on the HotpotQA multi-hop QA and LoCoMo long-context dialogue benchmarks. Parallel compaction gives the operator fine-grained, predictable control over summary volume and enables more targeted prompt engineering per block. At matched compaction decode volume, it reduces end-to-end wall time and improves compaction throughput over the sequential baseline.
Pretraining large language models with MXFP4
May 11, 2026Why does full-pipeline FP4 training of large language models often diverge, even when forward activations and activation gradients remain stable? We address this question through a controlled study of MXFP4 quantization in transformer training, progressively enabling FP4 across forward propagation (Fprop), activation gradients (Dgrad), and weight gradients (Wgrad) while holding all other factors fixed. In full pretraining of Llama 3.1-8B on the C4 dataset, we observe that quantizing Wgrad is the primary driver of convergence degradation, whereas FP4 in Fprop and Dgrad alone introduces only modest additional token requirements. To interpret this behavior, we evaluate both structured and stochastic interventions under a controlled experimental setting. We find that stochastic rounding and randomized Hadamard rotations fail to stabilize training once Wgrad is quantized, whereas deterministic Hadamard rotations consistently restore stable optimization. These results suggest that FP4 training instability is driven by structured micro-scaling errors along sensitive gradient paths, rather than by insufficient stochasticity. We run experiments with native MXFP4 support on AMD Instinct MI355X GPUs, enabling controlled investigation of these effects without reliance on software emulation.
PIFS-Rec: Process-In-Fabric-Switch for Large-Scale Recommendation System Inferences
Sep 25, 2024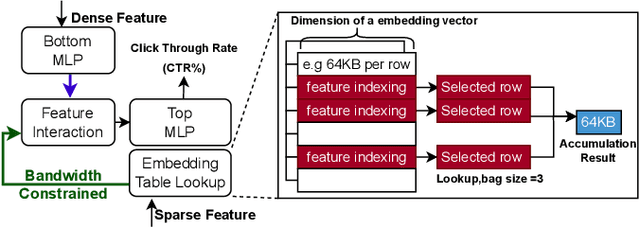
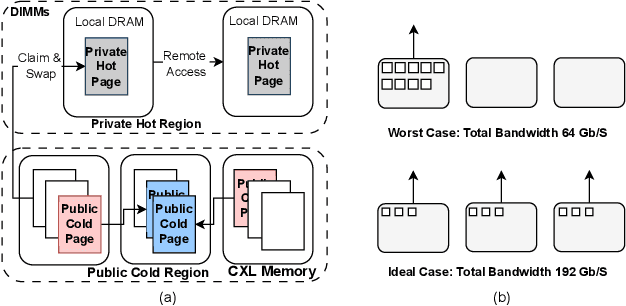
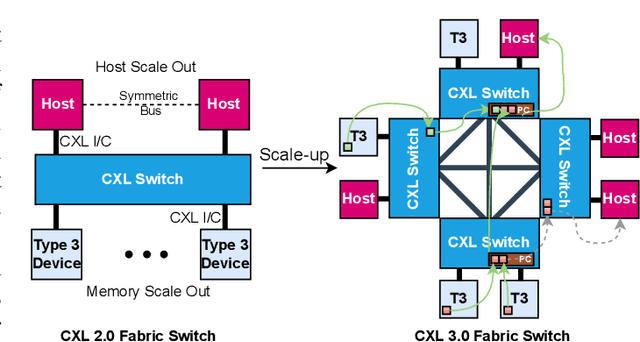

Deep Learning Recommendation Models (DLRMs) have become increasingly popular and prevalent in today's datacenters, consuming most of the AI inference cycles. The performance of DLRMs is heavily influenced by available bandwidth due to their large vector sizes in embedding tables and concurrent accesses. To achieve substantial improvements over existing solutions, novel approaches towards DLRM optimization are needed, especially, in the context of emerging interconnect technologies like CXL. This study delves into exploring CXL-enabled systems, implementing a process-in-fabric-switch (PIFS) solution to accelerate DLRMs while optimizing their memory and bandwidth scalability. We present an in-depth characterization of industry-scale DLRM workloads running on CXL-ready systems, identifying the predominant bottlenecks in existing CXL systems. We, therefore, propose PIFS-Rec, a PIFS-based scheme that implements near-data processing through downstream ports of the fabric switch. PIFS-Rec achieves a latency that is 3.89x lower than Pond, an industry-standard CXL-based system, and also outperforms BEACON, a state-of-the-art scheme, by 2.03x.
Analysis of Distributed Deep Learning in the Cloud
Aug 30, 2022We aim to resolve this problem by introducing a comprehensive distributed deep learning (DDL) profiler, which can determine the various execution "stalls" that DDL suffers from while running on a public cloud. We have implemented the profiler by extending prior work to additionally estimate two types of communication stalls - interconnect and network stalls. We train popular DNN models using the profiler to characterize various AWS GPU instances and list their advantages and shortcomings for users to make an informed decision. We observe that the more expensive GPU instances may not be the most performant for all DNN models and AWS may sub-optimally allocate hardware interconnect resources. Specifically, the intra-machine interconnect can introduce communication overheads up to 90% of DNN training time and network-connected instances can suffer from up to 5x slowdown compared to training on a single instance. Further, we model the impact of DNN macroscopic features such as the number of layers and the number of gradients on communication stalls. Finally, we propose a measurement-based recommendation model for users to lower their public cloud monetary costs for DDL, given a time budget.
Cocktail: Leveraging Ensemble Learning for Optimized Model Serving in Public Cloud
Jun 09, 2021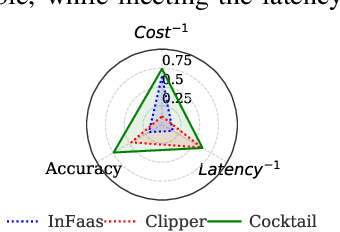
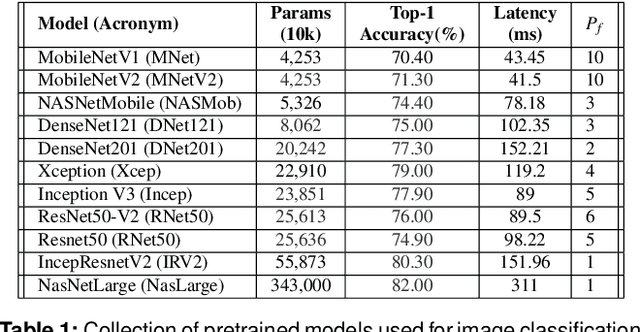
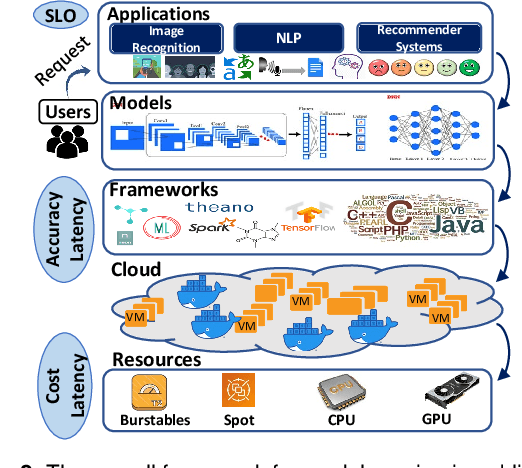
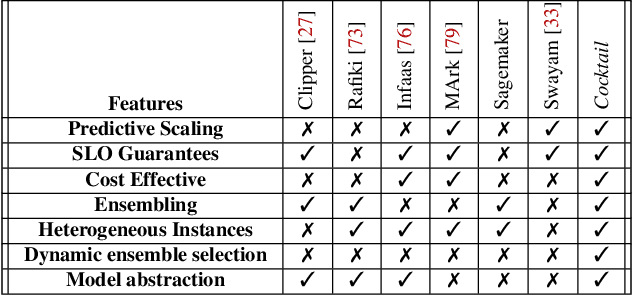
With a growing demand for adopting ML models for a varietyof application services, it is vital that the frameworks servingthese models are capable of delivering highly accurate predic-tions with minimal latency along with reduced deploymentcosts in a public cloud environment. Despite high latency,prior works in this domain are crucially limited by the accu-racy offered by individual models. Intuitively, model ensem-bling can address the accuracy gap by intelligently combiningdifferent models in parallel. However, selecting the appro-priate models dynamically at runtime to meet the desiredaccuracy with low latency at minimal deployment cost is anontrivial problem. Towards this, we proposeCocktail, a costeffective ensembling-based model serving framework.Cock-tailcomprises of two key components: (i) a dynamic modelselection framework, which reduces the number of modelsin the ensemble, while satisfying the accuracy and latencyrequirements; (ii) an adaptive resource management (RM)framework that employs a distributed proactive autoscalingpolicy combined with importance sampling, to efficiently allo-cate resources for the models. The RM framework leveragestransient virtual machine (VM) instances to reduce the de-ployment cost in a public cloud. A prototype implementationofCocktailon the AWS EC2 platform and exhaustive evalua-tions using a variety of workloads demonstrate thatCocktailcan reduce deployment cost by 1.45x, while providing 2xreduction in latency and satisfying the target accuracy for upto 96% of the requests, when compared to state-of-the-artmodel-serving frameworks.