 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocktail: Leveraging Ensemble Learning for Optimized Model Serving in Public Cloud
Paper and Code
Jun 09, 2021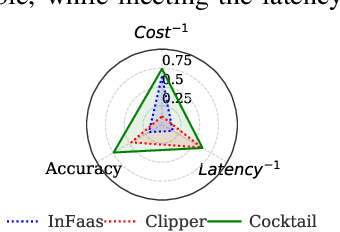
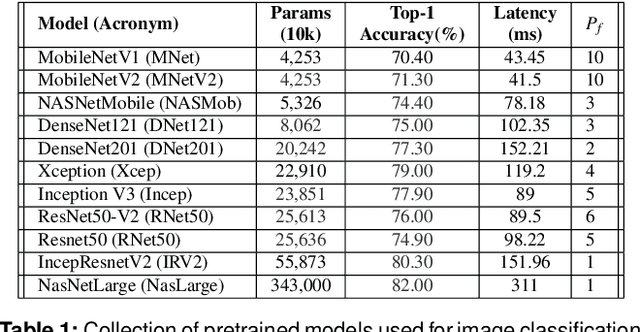
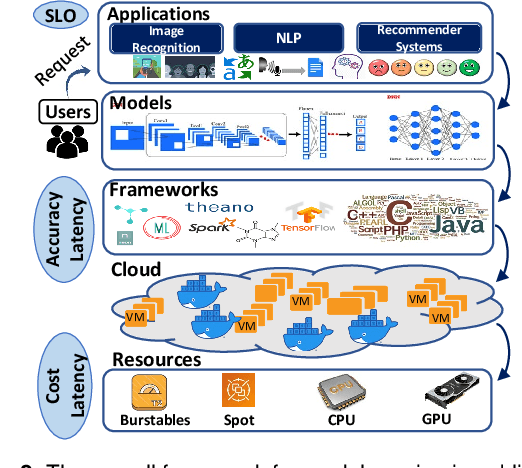
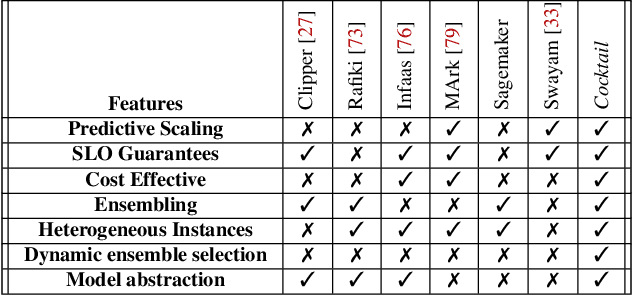
With a growing demand for adopting ML models for a varietyof application services, it is vital that the frameworks servingthese models are capable of delivering highly accurate predic-tions with minimal latency along with reduced deploymentcosts in a public cloud environment. Despite high latency,prior works in this domain are crucially limited by the accu-racy offered by individual models. Intuitively, model ensem-bling can address the accuracy gap by intelligently combiningdifferent models in parallel. However, selecting the appro-priate models dynamically at runtime to meet the desiredaccuracy with low latency at minimal deployment cost is anontrivial problem. Towards this, we proposeCocktail, a costeffective ensembling-based model serving framework.Cock-tailcomprises of two key components: (i) a dynamic modelselection framework, which reduces the number of modelsin the ensemble, while satisfying the accuracy and latencyrequirements; (ii) an adaptive resource management (RM)framework that employs a distributed proactive autoscalingpolicy combined with importance sampling, to efficiently allo-cate resources for the models. The RM framework leveragestransient virtual machine (VM) instances to reduce the de-ployment cost in a public cloud. A prototype implementationofCocktailon the AWS EC2 platform and exhaustive evalua-tions using a variety of workloads demonstrate thatCocktailcan reduce deployment cost by 1.45x, while providing 2xreduction in latency and satisfying the target accuracy for upto 96% of the requests, when compared to state-of-the-artmodel-serving frameworks.