 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting DNN Training for Intermittently Powered Energy Harvesting Micro Computers
Aug 25, 2024
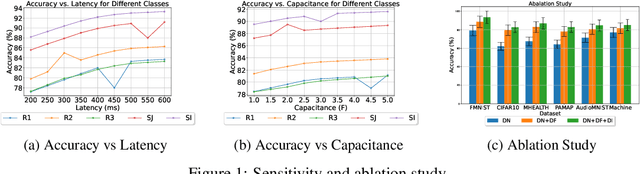


The deployment of Deep Neural Networks in energy-constrained environments, such as Energy Harvesting Wireless Sensor Networks, presents unique challenges, primarily due to the intermittent nature of power availability. To address these challenges, this study introduces and evaluates a novel training methodology tailored for DNNs operating within such contexts. In particular, we propose a dynamic dropout technique that adapts to both the architecture of the device and the variability in energy availability inherent in energy harvesting scenarios. Our proposed approach leverages a device model that incorporates specific parameters of the network architecture and the energy harvesting profile to optimize dropout rates dynamically during the training phase. By modulating the network's training process based on predicted energy availability, our method not only conserves energy but also ensures sustained learning and inference capabilities under power constraints. Our preliminary results demonstrate that this strategy provides 6 to 22 percent accuracy improvements compared to the state of the art with less than 5 percent additional compute. This paper details the development of the device model, describes the integration of energy profiles with intermittency aware dropout and quantization algorithms, and presents a comprehensive evaluation of the proposed approach using real-world energy harvesting data.
Cocktail: Leveraging Ensemble Learning for Optimized Model Serving in Public Cloud
Jun 09, 2021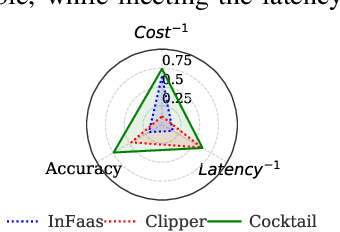
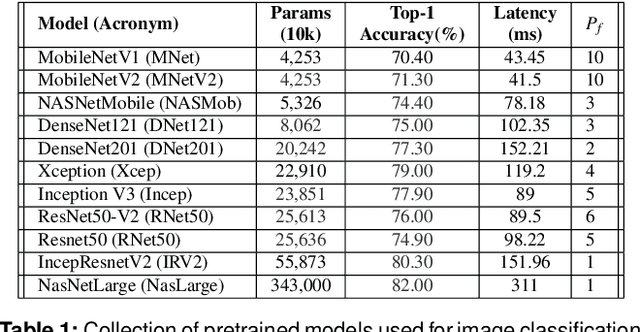
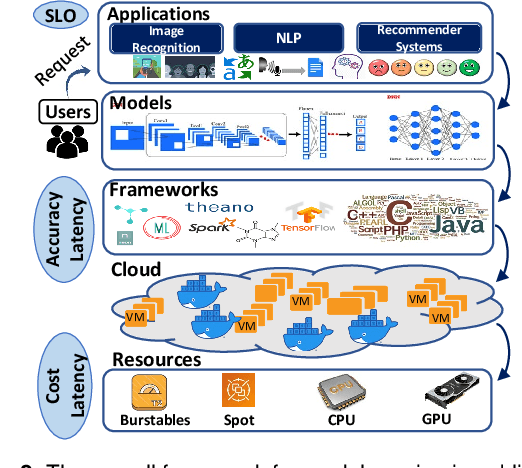
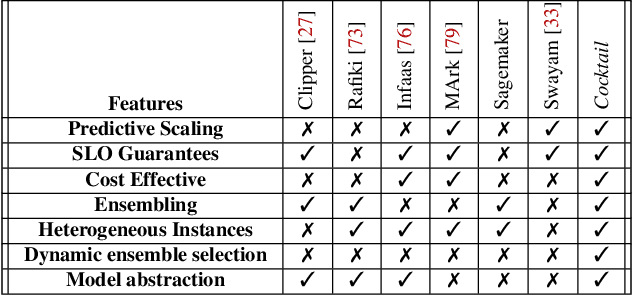
With a growing demand for adopting ML models for a varietyof application services, it is vital that the frameworks servingthese models are capable of delivering highly accurate predic-tions with minimal latency along with reduced deploymentcosts in a public cloud environment. Despite high latency,prior works in this domain are crucially limited by the accu-racy offered by individual models. Intuitively, model ensem-bling can address the accuracy gap by intelligently combiningdifferent models in parallel. However, selecting the appro-priate models dynamically at runtime to meet the desiredaccuracy with low latency at minimal deployment cost is anontrivial problem. Towards this, we proposeCocktail, a costeffective ensembling-based model serving framework.Cock-tailcomprises of two key components: (i) a dynamic modelselection framework, which reduces the number of modelsin the ensemble, while satisfying the accuracy and latencyrequirements; (ii) an adaptive resource management (RM)framework that employs a distributed proactive autoscalingpolicy combined with importance sampling, to efficiently allo-cate resources for the models. The RM framework leveragestransient virtual machine (VM) instances to reduce the de-ployment cost in a public cloud. A prototype implementationofCocktailon the AWS EC2 platform and exhaustive evalua-tions using a variety of workloads demonstrate thatCocktailcan reduce deployment cost by 1.45x, while providing 2xreduction in latency and satisfying the target accuracy for upto 96% of the requests, when compared to state-of-the-artmodel-serving frameworks.