 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Relations Break: Analyzing Relation Hallucination in Vision-Language Model Under Rotation and Noise
May 06, 2026Vision-language models (VLMs) achieve strong multimodal performance but remain prone to relation hallucination, which requires accurate reasoning over inter-object interactions. We study the impact of visual perturbations, specifically rotation and noise, and show that even mild distortions significantly degrade relational reasoning across models and datasets. We further evaluate prompt-based augmentation and preprocessing strategies (orientation correction and denoising), finding that while they offer partial improvements, they do not fully resolve hallucinations. Our results reveal a gap between perceptual robustness and relational understanding, highlighting the need for more robust, geometry-aware VLMs.
Disharmony: Forensics using Reverse Lighting Harmonization
Jan 17, 2025



Content generation and manipulation approaches based on deep learning methods have seen significant advancements, leading to an increased need for techniques to detect whether an image has been generated or edited. Another area of research focuses on the insertion and harmonization of objects within images. In this study, we explore the potential of using harmonization data in conjunction with a segmentation model to enhance the detection of edited image regions. These edits can be either manually crafted or generated using deep learning methods. Our findings demonstrate that this approach can effectively identify such edits. Existing forensic models often overlook the detection of harmonized objects in relation to the background, but our proposed Disharmony Network addresses this gap. By utilizing an aggregated dataset of harmonization techniques, our model outperforms existing forensic networks in identifying harmonized objects integrated into their backgrounds, and shows potential for detecting various forms of edits, including virtual try-on tasks.
Efficient Spatio-Temporal Signal Recognition on Edge Devices Using PointLCA-Net
Nov 21, 2024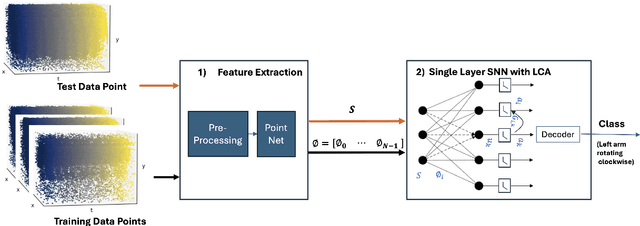
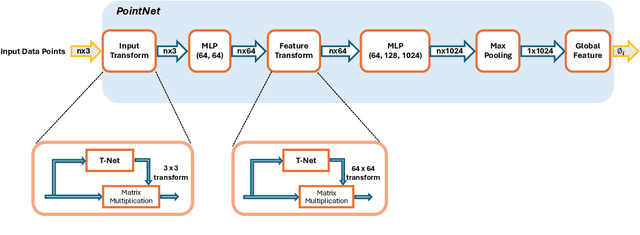
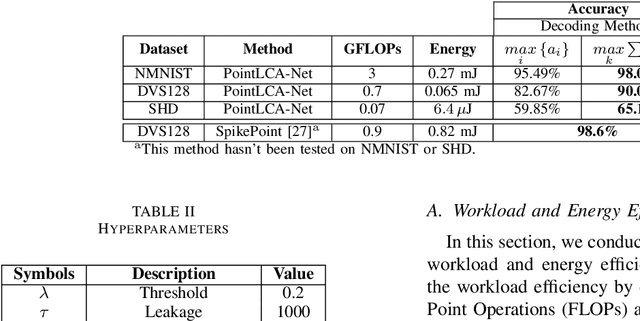
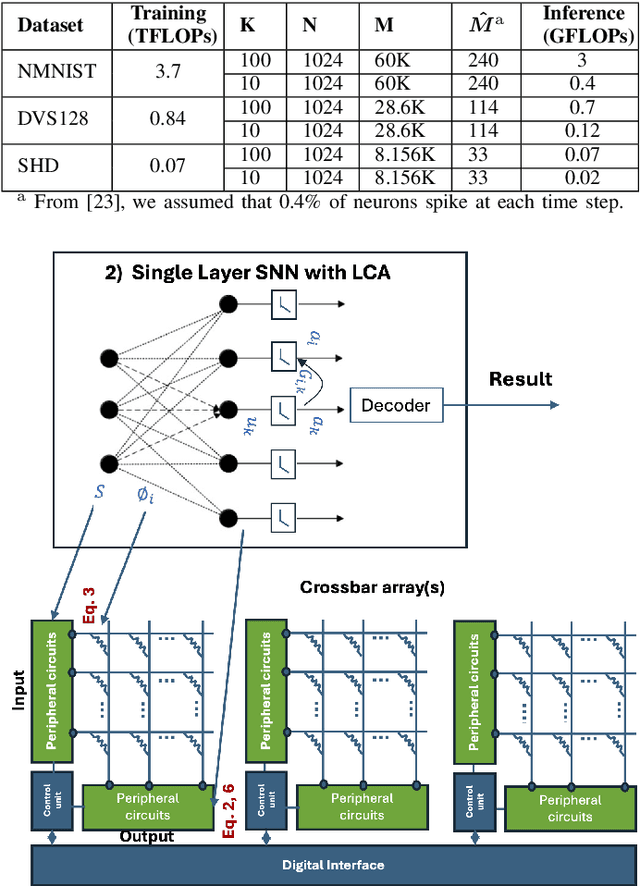
Recent advancements in machine learning, particularly through deep learning architectures like PointNet, have transformed the processing of three-dimensional (3D) point clouds, significantly improving 3D object classification and segmentation tasks. While 3D point clouds provide detailed spatial information, spatio-temporal signals introduce a dynamic element that accounts for changes over time. However, applying deep learning techniques to spatio-temporal signals and deploying them on edge devices presents challenges, including real-time processing, memory capacity, and power consumption. To address these issues, this paper presents a novel approach that combines PointNet's feature extraction with the in-memory computing capabilities and energy efficiency of neuromorphic systems for spatio-temporal signal recognition. The proposed method consists of a two-stage process: in the first stage, PointNet extracts features from the spatio-temporal signals, which are then stored in non-volatile memristor crossbar arrays. In the second stage, these features are processed by a single-layer spiking neural encoder-decoder that employs the Locally Competitive Algorithm (LCA) for efficient encoding and classification. This work integrates the strengths of both PointNet and LCA, enhancing computational efficiency and energy performance on edge devices. PointLCA-Net achieves high recognition accuracy for spatio-temporal data with substantially lower energy burden during both inference and training than comparable approaches, thus advancing the deployment of advanced neural architectures in energy-constrained environments.
Revisiting DNN Training for Intermittently Powered Energy Harvesting Micro Computers
Aug 25, 2024
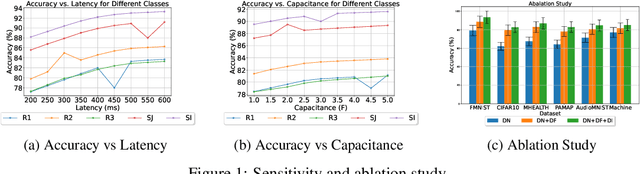


The deployment of Deep Neural Networks in energy-constrained environments, such as Energy Harvesting Wireless Sensor Networks, presents unique challenges, primarily due to the intermittent nature of power availability. To address these challenges, this study introduces and evaluates a novel training methodology tailored for DNNs operating within such contexts. In particular, we propose a dynamic dropout technique that adapts to both the architecture of the device and the variability in energy availability inherent in energy harvesting scenarios. Our proposed approach leverages a device model that incorporates specific parameters of the network architecture and the energy harvesting profile to optimize dropout rates dynamically during the training phase. By modulating the network's training process based on predicted energy availability, our method not only conserves energy but also ensures sustained learning and inference capabilities under power constraints. Our preliminary results demonstrate that this strategy provides 6 to 22 percent accuracy improvements compared to the state of the art with less than 5 percent additional compute. This paper details the development of the device model, describes the integration of energy profiles with intermittency aware dropout and quantization algorithms, and presents a comprehensive evaluation of the proposed approach using real-world energy harvesting data.
Rouser: Robust SNN training using adaptive threshold learning
Jul 28, 2024In Spiking Neural Networks (SNNs), learning rules are based on neuron spiking behavior, that is, if and when spikes are generated due to a neuron's membrane potential exceeding that neuron's firing threshold, and this spike timing encodes vital information. However, the threshold is generally treated as a hyperparameter, and incorrect selection can lead to neurons that do not spike for large portions of the training process, hindering the effective rate of learning. Inspired by homeostatic mechanisms in biological neurons, this work (Rouser) presents a study to rouse training-inactive neurons and improve the SNN training by using an in-loop adaptive threshold learning mechanism. Rouser's adaptive threshold allows for dynamic adjustments based on input data and network hyperparameters, influencing spike timing and improving training. This study focuses primarily on investigating the significance of learning neuron thresholds alongside weights in SNNs. We evaluate the performance of Rouser on the spatiotemporal datasets NMNIST, DVS128 and Spiking Heidelberg Digits (SHD), compare our results with state-of-the-art SNN training techniques, and discuss the strengths and limitations of our approach. Our results suggest that promoting threshold from a hyperparameter to a parameter can effectively address the issue of dead neurons during training, resulting in a more robust training algorithm that leads to improved training convergence, increased test accuracy, and substantial reductions in the number of training epochs needed to achieve viable accuracy. Rouser achieves up to 70% lower training latency while providing up to 2% higher accuracy over state-of-the-art SNNs with similar network architecture on the neuromorphic datasets NMNIST, DVS128 and SHD.
Can Prompt Modifiers Control Bias? A Comparative Analysis of Text-to-Image Generative Models
Jun 09, 2024



It has been shown that many generative models inherit and amplify societal biases. To date, there is no uniform/systematic agreed standard to control/adjust for these biases. This study examines the presence and manipulation of societal biases in leading text-to-image models: Stable Diffusion, DALL-E 3, and Adobe Firefly. Through a comprehensive analysis combining base prompts with modifiers and their sequencing, we uncover the nuanced ways these AI technologies encode biases across gender, race, geography, and region/culture. Our findings reveal the challenges and potential of prompt engineering in controlling biases, highlighting the critical need for ethical AI development promoting diversity and inclusivity. This work advances AI ethics by not only revealing the nuanced dynamics of bias in text-to-image generation models but also by offering a novel framework for future research in controlling bias. Our contributions-panning comparative analyses, the strategic use of prompt modifiers, the exploration of prompt sequencing effects, and the introduction of a bias sensitivity taxonomy-lay the groundwork for the development of common metrics and standard analyses for evaluating whether and how future AI models exhibit and respond to requests to adjust for inherent biases.