 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Reverse Inconsistency: LLM Self-Inconsistency Beyond Generative Randomness and Prompt Paraphrasing
Apr 02, 2025While the inconsistency of LLMs is not a novel topic, prior research has predominantly addressed two types of generative inconsistencies: i) Randomness Inconsistency: running the same LLM multiple trials, yielding varying responses; ii) Paraphrase Inconsistency: paraphrased prompts result in different responses from the same LLM. Randomness Inconsistency arises from the inherent randomness due to stochastic sampling in generative models, while Paraphrase Inconsistency is a consequence of the language modeling objectives, where paraphrased prompts alter the distribution of vocabulary logits. This research discovers Prompt-Reverse Inconsistency (PRIN), a new form of LLM self-inconsistency: given a question and a couple of LLM-generated answer candidates, the LLM often has conflicting responses when prompted "Which are correct answers?" and "Which are incorrect answers?". PRIN poses a big concern as it undermines the credibility of LLM-as-a-judge, and suggests a challenge for LLMs to adhere to basic logical rules. We conduct a series of experiments to investigate PRIN, examining the extent of PRIN across different LLMs, methods to mitigate it, potential applications, and its relationship with Randomness Inconsistency and Paraphrase Inconsistency. As the first study to explore PRIN, our findings offer valuable insights into the inner workings of LLMs and contribute to advancing trustworthy AI.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024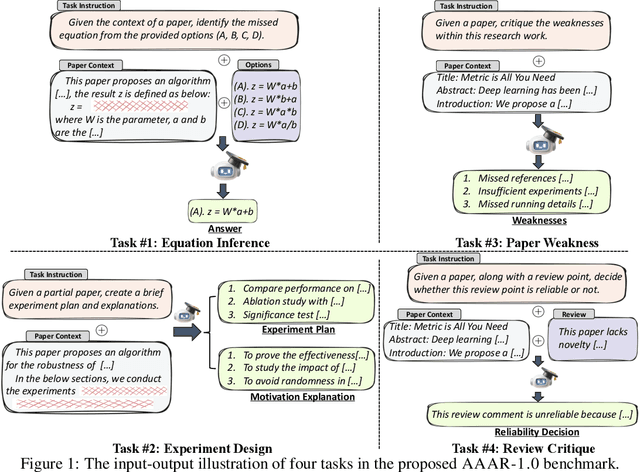
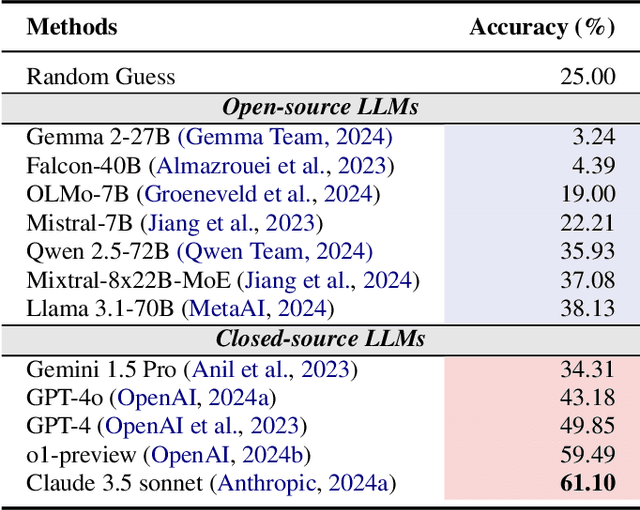
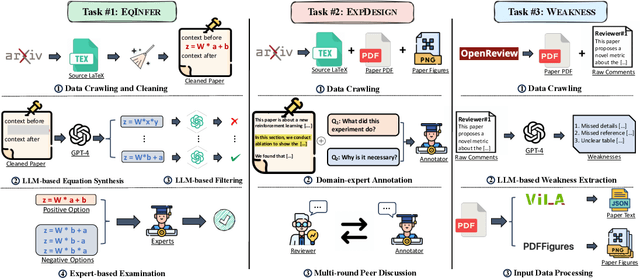
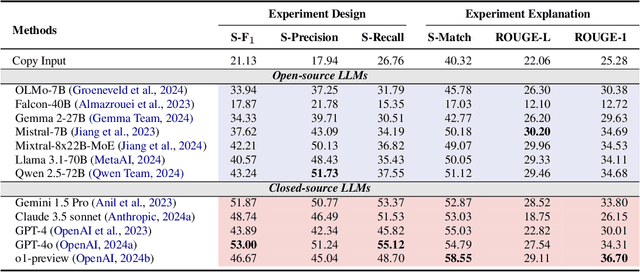
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
Can Prompt Modifiers Control Bias? A Comparative Analysis of Text-to-Image Generative Models
Jun 09, 2024



It has been shown that many generative models inherit and amplify societal biases. To date, there is no uniform/systematic agreed standard to control/adjust for these biases. This study examines the presence and manipulation of societal biases in leading text-to-image models: Stable Diffusion, DALL-E 3, and Adobe Firefly. Through a comprehensive analysis combining base prompts with modifiers and their sequencing, we uncover the nuanced ways these AI technologies encode biases across gender, race, geography, and region/culture. Our findings reveal the challenges and potential of prompt engineering in controlling biases, highlighting the critical need for ethical AI development promoting diversity and inclusivity. This work advances AI ethics by not only revealing the nuanced dynamics of bias in text-to-image generation models but also by offering a novel framework for future research in controlling bias. Our contributions-panning comparative analyses, the strategic use of prompt modifiers, the exploration of prompt sequencing effects, and the introduction of a bias sensitivity taxonomy-lay the groundwork for the development of common metrics and standard analyses for evaluating whether and how future AI models exhibit and respond to requests to adjust for inherent biases.
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024



With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.