 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025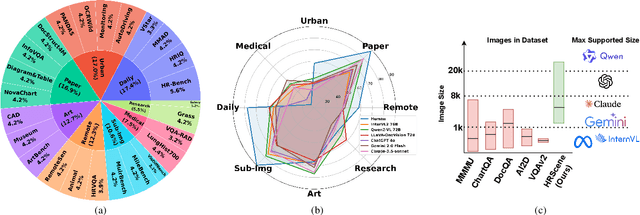
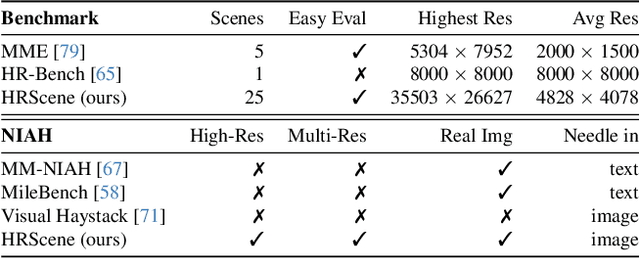
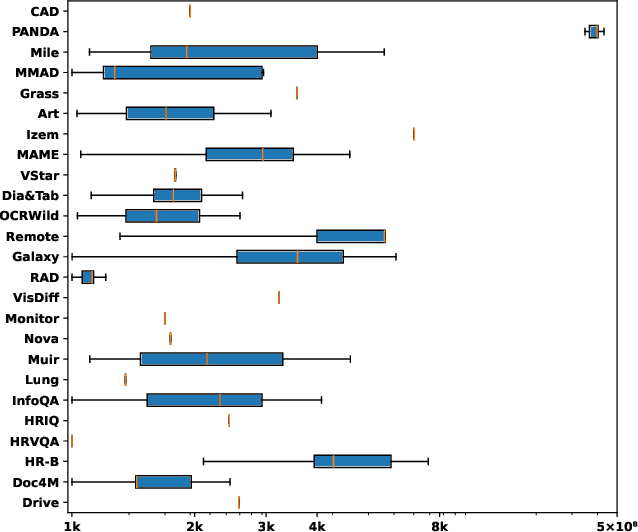
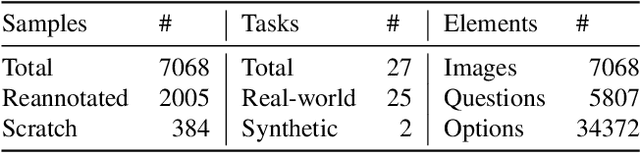
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024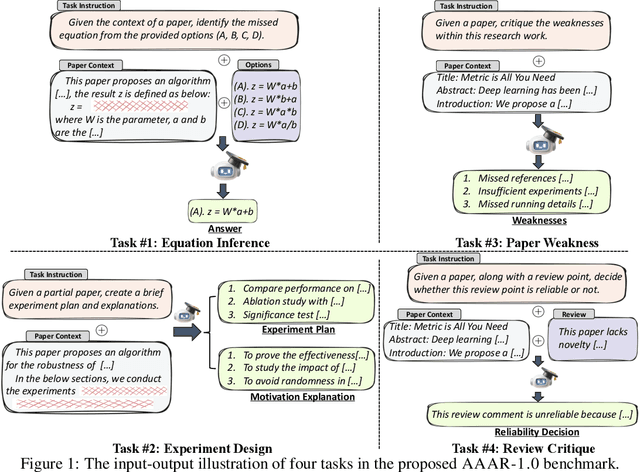
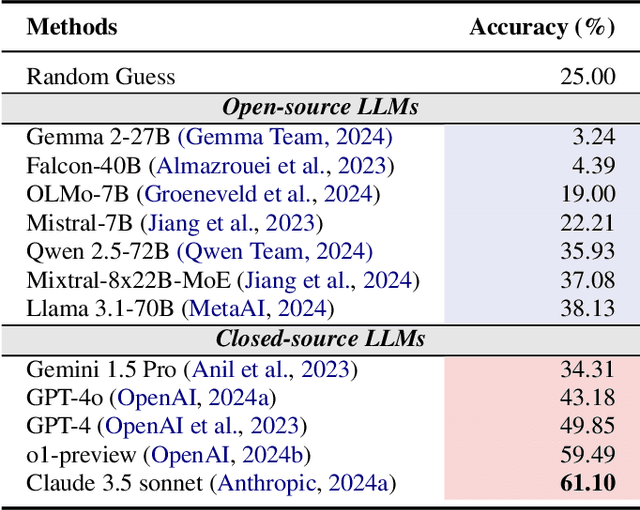
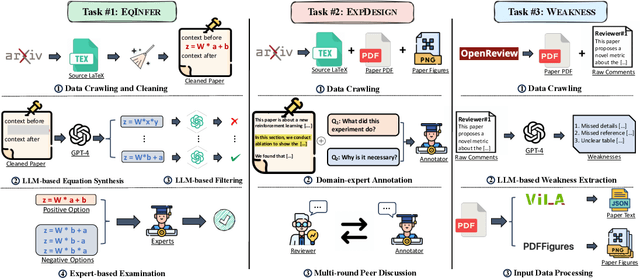
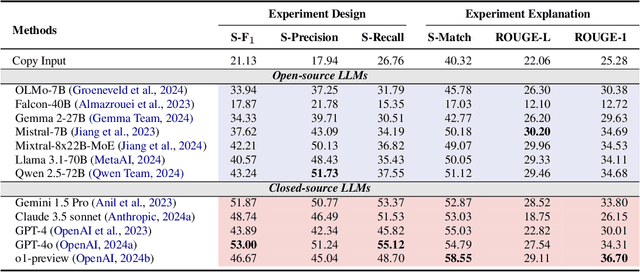
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Aug 13, 2024Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a group of open-source SWE agents, with a maximum individual resolve rate of 27.3% on SWE-Bench Lite, can achieve a 34.3% resolve rate with DEI, making a 25% improvement and beating most closed-source solutions. Our best-performing group excels with a 55% resolve rate, securing the highest ranking on SWE-Bench Lite. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024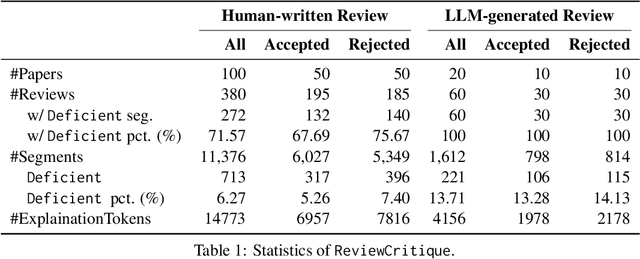
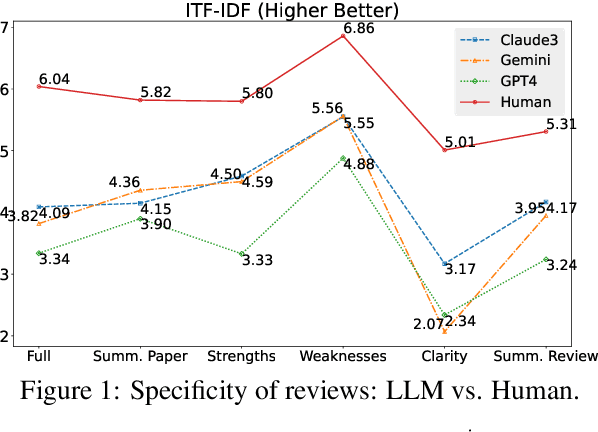

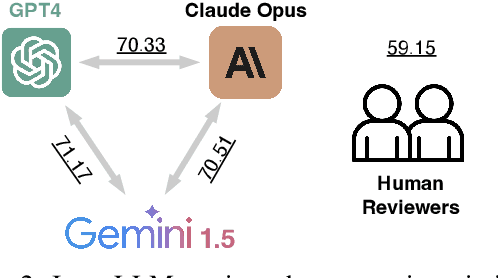
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.
LLMs' Classification Performance is Overclaimed
Jun 23, 2024In many classification tasks designed for AI or human to solve, gold labels are typically included within the label space by default, often posed as "which of the following is correct?" This standard setup has traditionally highlighted the strong performance of advanced AI, particularly top-performing Large Language Models (LLMs), in routine classification tasks. However, when the gold label is intentionally excluded from the label space, it becomes evident that LLMs still attempt to select from the available label candidates, even when none are correct. This raises a pivotal question: Do LLMs truly demonstrate their intelligence in understanding the essence of classification tasks? In this study, we evaluate both closed-source and open-source LLMs across representative classification tasks, arguing that the perceived performance of LLMs is overstated due to their inability to exhibit the expected comprehension of the task. This paper makes a threefold contribution: i) To our knowledge, this is the first work to identify the limitations of LLMs in classification tasks when gold labels are absent. We define this task as Classify-w/o-Gold and propose it as a new testbed for LLMs. ii) We introduce a benchmark, Know-No, comprising two existing classification tasks and one new task, to evaluate Classify-w/o-Gold. iii) This work defines and advocates for a new evaluation metric, OmniAccuracy, which assesses LLMs' performance in classification tasks both when gold labels are present and absent.
Chain-of-Scrutiny: Detecting Backdoor Attacks for Large Language Models
Jun 10, 2024



Backdoor attacks present significant threats to Large Language Models (LLMs), particularly with the rise of third-party services that offer API integration and prompt engineering. Untrustworthy third parties can plant backdoors into LLMs and pose risks to users by embedding malicious instructions into user queries. The backdoor-compromised LLM will generate malicious output when and input is embedded with a specific trigger predetermined by an attacker. Traditional defense strategies, which primarily involve model parameter fine-tuning and gradient calculation, are inadequate for LLMs due to their extensive computational and clean data requirements. In this paper, we propose a novel solution, Chain-of-Scrutiny (CoS), to address these challenges. Backdoor attacks fundamentally create a shortcut from the trigger to the target output, thus lack reasoning support. Accordingly, CoS guides the LLMs to generate detailed reasoning steps for the input, then scrutinizes the reasoning process to ensure consistency with the final answer. Any inconsistency may indicate an attack. CoS only requires black-box access to LLM, offering a practical defense, particularly for API-accessible LLMs. It is user-friendly, enabling users to conduct the defense themselves. Driven by natural language, the entire defense process is transparent to users. We validate the effectiveness of CoS through extensive experiments across various tasks and LLMs. Additionally, experiments results shows CoS proves more beneficial for more powerful LLMs.
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024



With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
TravelPlanner: A Benchmark for Real-World Planning with Language Agents
Feb 05, 2024
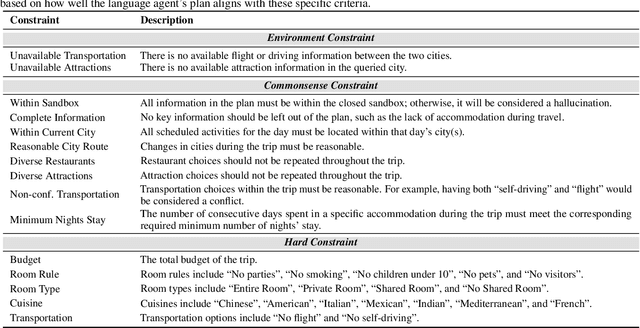

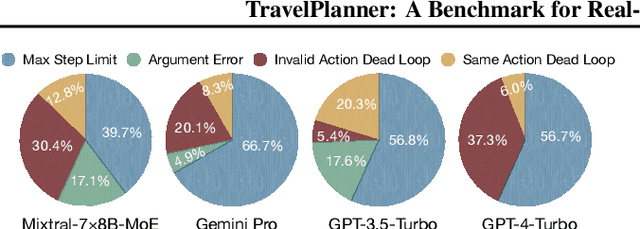
Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of the cognitive substrates necessary for human-level planning have been lacking. Recently, language agents powered by large language models (LLMs) have shown interesting capabilities such as tool use and reasoning. Are these language agents capable of planning in more complex settings that are out of the reach of prior AI agents? To advance this investigation, we propose TravelPlanner, a new planning benchmark that focuses on travel planning, a common real-world planning scenario. It provides a rich sandbox environment, various tools for accessing nearly four million data records, and 1,225 meticulously curated planning intents and reference plans. Comprehensive evaluations show that the current language agents are not yet capable of handling such complex planning tasks-even GPT-4 only achieves a success rate of 0.6%. Language agents struggle to stay on task, use the right tools to collect information, or keep track of multiple constraints. However, we note that the mere possibility for language agents to tackle such a complex problem is in itself non-trivial progress. TravelPlanner provides a challenging yet meaningful testbed for future language agents.
Large Language Models for Mathematical Reasoning: Progresses and Challenges
Jan 31, 2024Mathematical reasoning serves as a cornerstone for assessing the fundamental cognitive capabilities of human intelligence. In recent times, there has been a notable surge in the development of Large Language Models (LLMs) geared towards the automated resolution of mathematical problems. However, the landscape of mathematical problem types is vast and varied, with LLM-oriented techniques undergoing evaluation across diverse datasets and settings. This diversity makes it challenging to discern the true advancements and obstacles within this burgeoning field. This survey endeavors to address four pivotal dimensions: i) a comprehensive exploration of the various mathematical problems and their corresponding datasets that have been investigated; ii) an examination of the spectrum of LLM-oriented techniques that have been proposed for mathematical problem-solving; iii) an overview of factors and concerns affecting LLMs in solving math; and iv) an elucidation of the persisting challenges within this domain. To the best of our knowledge, this survey stands as one of the first extensive examinations of the landscape of LLMs in the realm of mathematics, providing a holistic perspective on the current state, accomplishments, and future challenges in this rapidly evolving field.
UMIE: Unified Multimodal Information Extraction with Instruction Tuning
Jan 05, 2024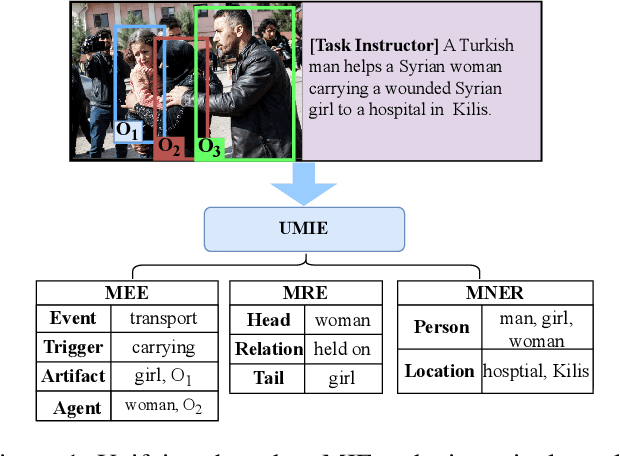

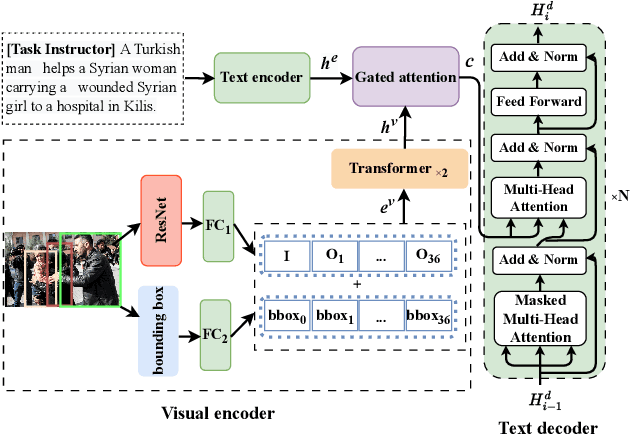

Multimodal information extraction (MIE) gains significant attention as the popularity of multimedia content increases. However, current MIE methods often resort to using task-specific model structures, which results in limited generalizability across tasks and underutilizes shared knowledge across MIE tasks. To address these issues, we propose UMIE, a unified multimodal information extractor to unify three MIE tasks as a generation problem using instruction tuning, being able to effectively extract both textual and visual mentions. Extensive experiments show that our single UMIE outperforms various state-of-the-art (SoTA) methods across six MIE datasets on three tasks. Furthermore, in-depth analysis demonstrates UMIE's strong generalization in the zero-shot setting, robustness to instruction variants, and interpretability. Our research serves as an initial step towards a unified MIE model and initiates the exploration into both instruction tuning and large language models within the MIE domain. Our code, data, and model are available at https://github.com/ZUCC-AI/UMIE