 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardTests: Synthesizing High-Quality Test Cases for LLM Coding
May 30, 2025Verifiers play a crucial role in large language model (LLM) reasoning, needed by post-training techniques such as reinforcement learning. However, reliable verifiers are hard to get for difficult coding problems, because a well-disguised wrong solution may only be detected by carefully human-written edge cases that are difficult to synthesize. To address this issue, we propose HARDTESTGEN, a pipeline for high-quality test synthesis using LLMs. With this pipeline, we curate a comprehensive competitive programming dataset HARDTESTS with 47k problems and synthetic high-quality tests. Compared with existing tests, HARDTESTGEN tests demonstrate precision that is 11.3 percentage points higher and recall that is 17.5 percentage points higher when evaluating LLM-generated code. For harder problems, the improvement in precision can be as large as 40 points. HARDTESTS also proves to be more effective for model training, measured by downstream code generation performance. We will open-source our dataset and synthesis pipeline at https://leililab.github.io/HardTests/.
Programming by Examples Meets Historical Linguistics: A Large Language Model Based Approach to Sound Law Induction
Jan 27, 2025



Historical linguists have long written "programs" that convert reconstructed words in an ancestor language into their attested descendants via ordered string rewrite functions (called sound laws) However, writing these programs is time-consuming, motivating the development of automated Sound Law Induction (SLI) which we formulate as Programming by Examples (PBE) with Large Language Models (LLMs) in this paper. While LLMs have been effective for code generation, recent work has shown that PBE is challenging but improvable by fine-tuning, especially with training data drawn from the same distribution as evaluation data. In this paper, we create a conceptual framework of what constitutes a "similar distribution" for SLI and propose four kinds of synthetic data generation methods with varying amounts of inductive bias to investigate what leads to the best performance. Based on the results we create a SOTA open-source model for SLI as PBE (+6% pass rate with a third of the parameters of the second-best LLM) and also highlight exciting future directions for PBE research.
Embracing AI in Education: Understanding the Surge in Large Language Model Use by Secondary Students
Nov 27, 2024
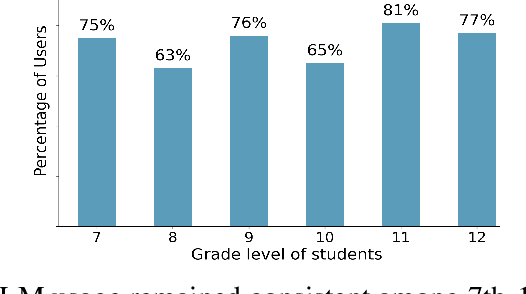

The impressive essay writing and problem-solving capabilities of large language models (LLMs) like OpenAI's ChatGPT have opened up new avenues in education. Our goal is to gain insights into the widespread use of LLMs among secondary students to inform their future development. Despite school restrictions, our survey of over 300 middle and high school students revealed that a remarkable 70% of students have utilized LLMs, higher than the usage percentage among young adults, and this percentage remains consistent across 7th to 12th grade. Students also reported using LLMs for multiple subjects, including language arts, history, and math assignments, but expressed mixed thoughts on their effectiveness due to occasional hallucinations in historical contexts and incorrect answers for lack of rigorous reasoning. The survey feedback called for LLMs better adapted for students, and also raised questions to developers and educators on how to help students from underserved communities leverage LLMs' capabilities for equal access to advanced education resources. We propose a few ideas to address such issues, including subject-specific models, personalized learning, and AI classrooms.
Scaling LLM Inference with Optimized Sample Compute Allocation
Oct 29, 2024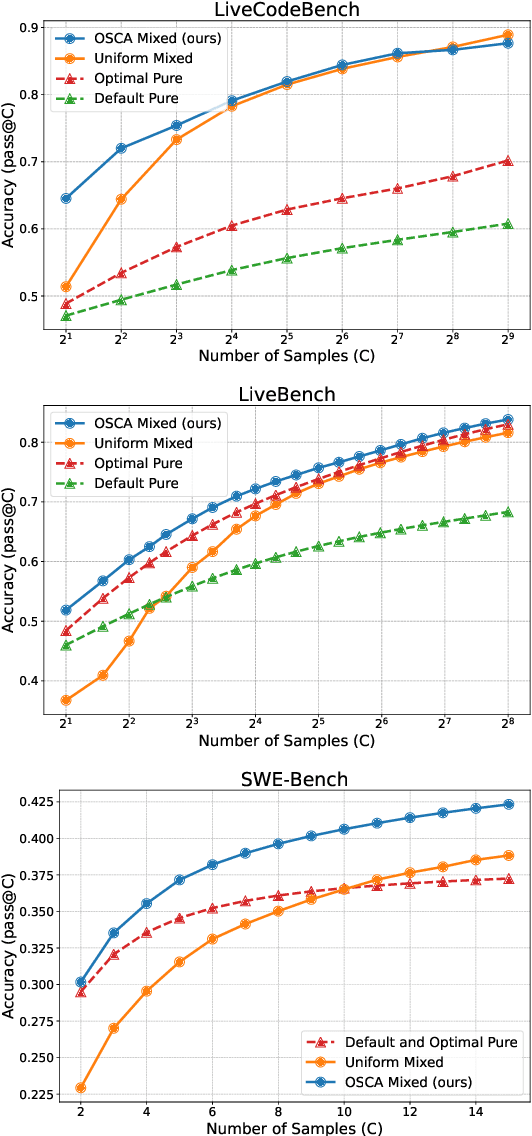
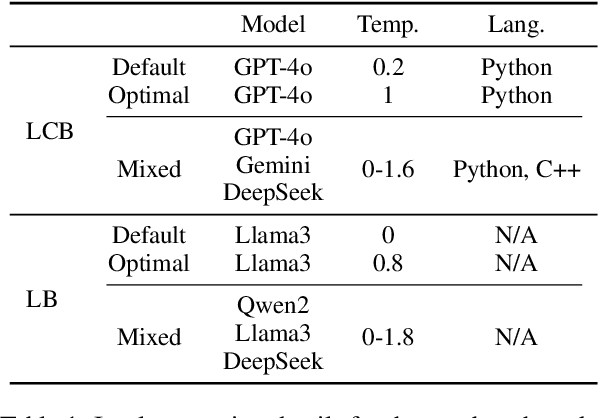
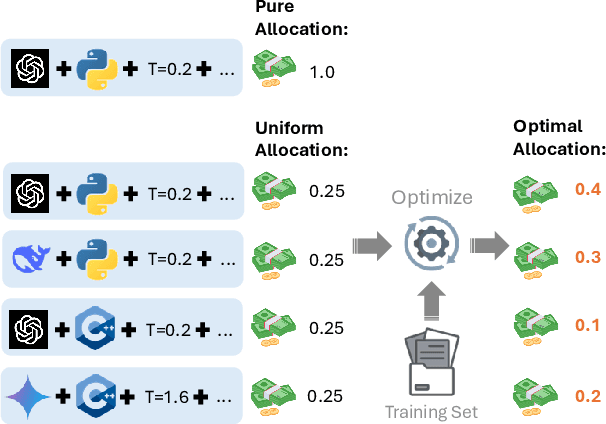
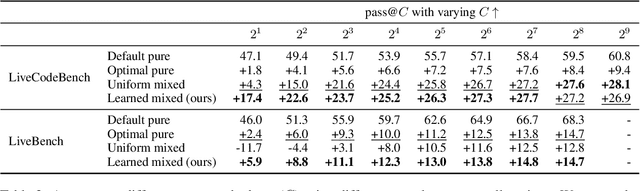
Sampling is a basic operation in many inference-time algorithms of large language models (LLMs). To scale up inference efficiently with a limited compute, it is crucial to find an optimal allocation for sample compute budgets: Which sampling configurations (model, temperature, language, etc.) do we use? How many samples do we generate in each configuration? We formulate these choices as a learning problem and propose OSCA, an algorithm that Optimizes Sample Compute Allocation by finding an optimal mix of different inference configurations. Our experiments show that with our learned mixed allocation, we can achieve accuracy better than the best single configuration with 128x less compute on code generation and 25x less compute on 4 reasoning tasks. OSCA is also shown to be effective in agentic workflows beyond single-turn tasks, achieving a better accuracy on SWE-Bench with 3x less compute than the default configuration. Our code and generations are released at https://github.com/LeiLiLab/OSCA.
SWE-Search: Enhancing Software Agents with Monte Carlo Tree Search and Iterative Refinement
Oct 29, 2024



Software engineers operating in complex and dynamic environments must continuously adapt to evolving requirements, learn iteratively from experience, and reconsider their approaches based on new insights. However, current large language model (LLM)-based software agents often rely on rigid processes and tend to repeat ineffective actions without the capacity to evaluate their performance or adapt their strategies over time. To address these challenges, we propose SWE-Search, a multi-agent framework that integrates Monte Carlo Tree Search (MCTS) with a self-improvement mechanism to enhance software agents' performance on repository-level software tasks. SWE-Search extends traditional MCTS by incorporating a hybrid value function that leverages LLMs for both numerical value estimation and qualitative evaluation. This enables self-feedback loops where agents iteratively refine their strategies based on both quantitative numerical evaluations and qualitative natural language assessments of pursued trajectories. The framework includes a SWE-Agent for adaptive exploration, a Value Agent for iterative feedback, and a Discriminator Agent that facilitates multi-agent debate for collaborative decision-making. Applied to the SWE-bench benchmark, our approach demonstrates a 23% relative improvement in performance across five models compared to standard open-source agents without MCTS. Our analysis reveals how performance scales with increased search depth and identifies key factors that facilitate effective self-evaluation in software agents. This work highlights the potential of self-evaluation driven search techniques to enhance agent reasoning and planning in complex, dynamic software engineering environments.
Revealing the Barriers of Language Agents in Planning
Oct 16, 2024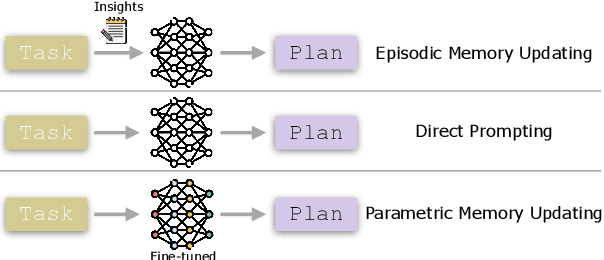
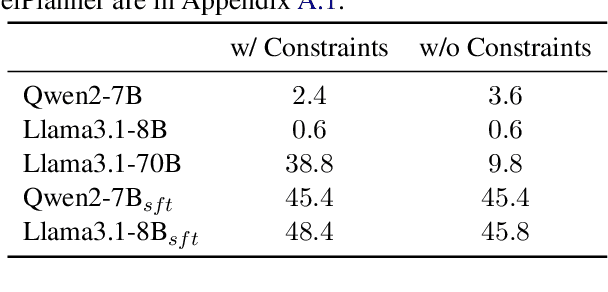
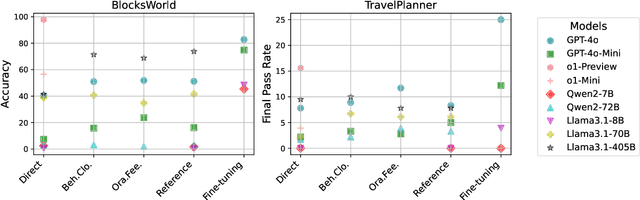
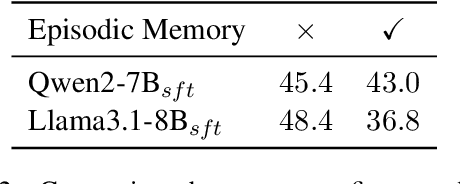
Autonomous planning has been an ongoing pursuit since the inception of artificial intelligence. Based on curated problem solvers, early planning agents could deliver precise solutions for specific tasks but lacked generalization. The emergence of large language models (LLMs) and their powerful reasoning capabilities has reignited interest in autonomous planning by automatically generating reasonable solutions for given tasks. However, prior research and our experiments show that current language agents still lack human-level planning abilities. Even the state-of-the-art reasoning model, OpenAI o1, achieves only 15.6% on one of the complex real-world planning benchmarks. This highlights a critical question: What hinders language agents from achieving human-level planning? Although existing studies have highlighted weak performance in agent planning, the deeper underlying issues and the mechanisms and limitations of the strategies proposed to address them remain insufficiently understood. In this work, we apply the feature attribution study and identify two key factors that hinder agent planning: the limited role of constraints and the diminishing influence of questions. We also find that although current strategies help mitigate these challenges, they do not fully resolve them, indicating that agents still have a long way to go before reaching human-level intelligence.
Diversity Empowers Intelligence: Integrating Expertise of Software Engineering Agents
Aug 13, 2024Large language model (LLM) agents have shown great potential in solving real-world software engineering (SWE) problems. The most advanced open-source SWE agent can resolve over 27% of real GitHub issues in SWE-Bench Lite. However, these sophisticated agent frameworks exhibit varying strengths, excelling in certain tasks while underperforming in others. To fully harness the diversity of these agents, we propose DEI (Diversity Empowered Intelligence), a framework that leverages their unique expertise. DEI functions as a meta-module atop existing SWE agent frameworks, managing agent collectives for enhanced problem-solving. Experimental results show that a DEI-guided committee of agents is able to surpass the best individual agent's performance by a large margin. For instance, a group of open-source SWE agents, with a maximum individual resolve rate of 27.3% on SWE-Bench Lite, can achieve a 34.3% resolve rate with DEI, making a 25% improvement and beating most closed-source solutions. Our best-performing group excels with a 55% resolve rate, securing the highest ranking on SWE-Bench Lite. Our findings contribute to the growing body of research on collaborative AI systems and their potential to solve complex software engineering challenges.
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Jul 20, 2024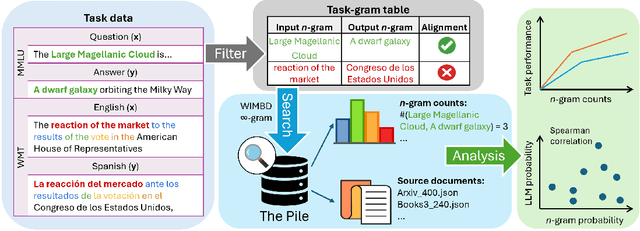
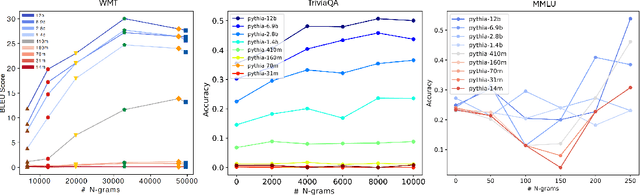
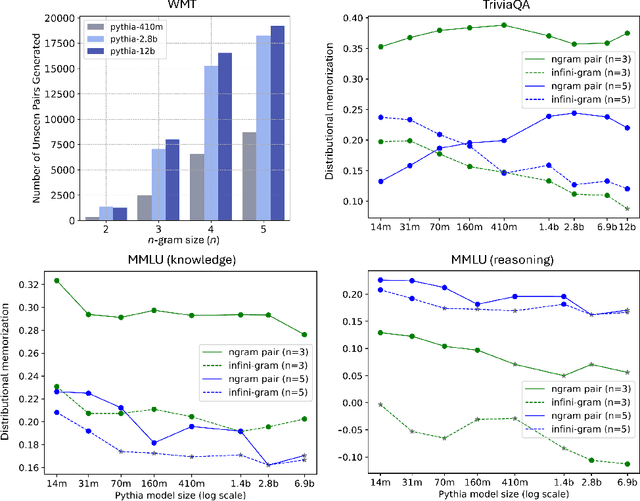
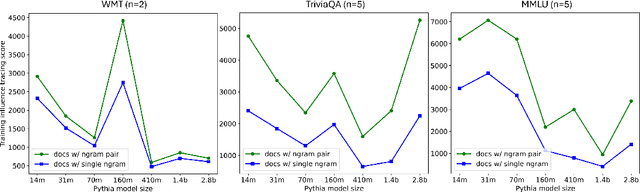
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
Can Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
DeFT: Flash Tree-attention with IO-Awareness for Efficient Tree-search-based LLM Inference
Mar 30, 2024Decoding using tree search can greatly enhance the inference quality for transformer-based Large Language Models (LLMs). Depending on the guidance signal, it searches for the best path from root to leaf in the tree by forming LLM outputs to improve controllability, reasoning ability, alignment, et cetera. However, current tree decoding strategies and their inference systems do not suit each other well due to redundancy in computation, memory footprints, and memory access, resulting in inefficient inference. To address this issue, we propose DeFT, an IO-aware tree attention algorithm that maintains memory-efficient attention calculation with low memory footprints in two stages: (1) QKV Preparation: we propose a KV-Guided Tree Split strategy to group QKV wisely for high utilization of GPUs and reduction of memory reads/writes for the KV cache between GPU global memory and on-chip shared memory as much as possible; (2) Attention Calculation: we calculate partial attention of each QKV groups in a fused kernel then apply a Tree-topology-aware Global Reduction strategy to get final attention. Thanks to a reduction in KV cache IO by 3.6-4.5$\times$, along with an additional reduction in IO for $\mathbf{Q} \mathbf{K}^\top$ and Softmax equivalent to 25% of the total KV cache IO, DeFT can achieve a speedup of 1.7-2.4$\times$ in end-to-end latency across two practical reasoning tasks over the SOTA attention algorithms.