 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling LLM Inference with Optimized Sample Compute Allocation
Paper and Code
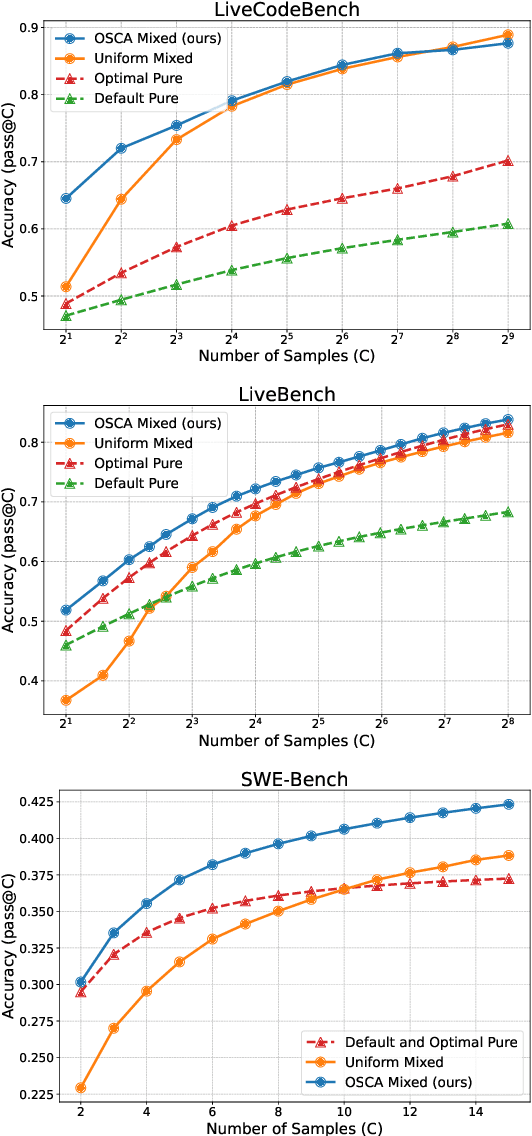
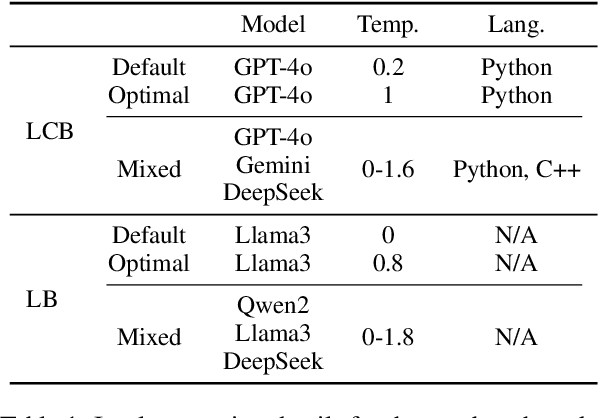
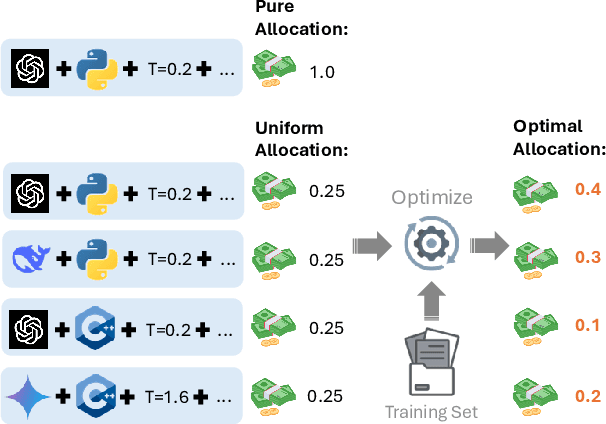
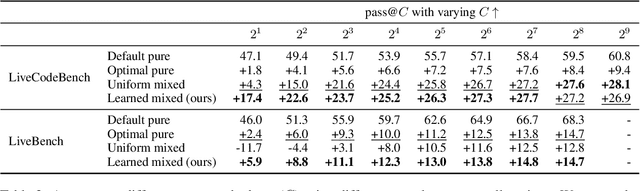
Sampling is a basic operation in many inference-time algorithms of large language models (LLMs). To scale up inference efficiently with a limited compute, it is crucial to find an optimal allocation for sample compute budgets: Which sampling configurations (model, temperature, language, etc.) do we use? How many samples do we generate in each configuration? We formulate these choices as a learning problem and propose OSCA, an algorithm that Optimizes Sample Compute Allocation by finding an optimal mix of different inference configurations. Our experiments show that with our learned mixed allocation, we can achieve accuracy better than the best single configuration with 128x less compute on code generation and 25x less compute on 4 reasoning tasks. OSCA is also shown to be effective in agentic workflows beyond single-turn tasks, achieving a better accuracy on SWE-Bench with 3x less compute than the default configuration. Our code and generations are released at https://github.com/LeiLiLab/OSCA.