 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAB-Bench: Evaluating LLM Agents under Complex Task Dependencies and Human-aligned User Simulation
Jun 01, 2026Evaluating LLM agents in realistic service scenarios requires complex task dependencies, imperfect user behavior, and an evaluation that accommodates multiple valid solutions. We introduce CRAB-Bench (Constraint-based Realistic Agent Benchmark) and RUSE (Realistic User Simulation Engine) to address this gap. CRAB-Bench generates tasks via a constraint graph over multiple interdependent entities with structured distractors, requiring agents to reason carefully over thousands of misleading candidates where only a tiny fraction of solutions are valid. RUSE replaces cooperative, template-like simulators with realistic users grounded in human behavioral studies, instantiated across diverse personas and four behavioral dimensions. Experiments on four frontier LLM agents show that the best model achieves only 61% pass@1 on CRAB-Bench, and switching to RUSE causes further drops of up to 57%, concentrated in task-solving ability rather than conversational quality. Information Disclosure is the most damaging behavioral dimension, and agents interacting with RUSE are less likely to admit mistakes, instead masking errors through implicit corrections.
Learning to Interrupt in Language-based Multi-agent Communication
Apr 07, 2026Multi-agent systems using large language models (LLMs) have demonstrated impressive capabilities across various domains. However, current agent communication suffers from verbose output that overload context and increase computational costs. Although existing approaches focus on compressing the message from the speaker side, they struggle to adapt to different listeners and identify relevant information. An effective way in human communication is to allow the listener to interrupt and express their opinion or ask for clarification. Motivated by this, we propose an interruptible communication framework that allows the agent who is listening to interrupt the current speaker. Through prompting experiments, we find that current LLMs are often overconfident and interrupt before receiving enough information. Therefore, we propose a learning method that predicts the appropriate interruption points based on the estimated future reward and cost. We evaluate our framework across various multi-agent scenarios, including 2-agent text pictionary games, 3-agent meeting scheduling, and 3-agent debate. The results of the experiment show that our HANDRAISER can reduce the communication cost by 32.2% compared to the baseline with comparable or superior task performance. This learned interruption behavior can also be generalized to different agents and tasks.
Strategic Planning and Rationalizing on Trees Make LLMs Better Debaters
May 20, 2025Winning competitive debates requires sophisticated reasoning and argument skills. There are unique challenges in the competitive debate: (1) The time constraints force debaters to make strategic choices about which points to pursue rather than covering all possible arguments; (2) The persuasiveness of the debate relies on the back-and-forth interaction between arguments, which a single final game status cannot evaluate. To address these challenges, we propose TreeDebater, a novel debate framework that excels in competitive debate. We introduce two tree structures: the Rehearsal Tree and Debate Flow Tree. The Rehearsal Tree anticipates the attack and defenses to evaluate the strength of the claim, while the Debate Flow Tree tracks the debate status to identify the active actions. TreeDebater allocates its time budget among candidate actions and uses the speech time controller and feedback from the simulated audience to revise its statement. The human evaluation on both the stage-level and the debate-level comparison shows that our TreeDebater outperforms the state-of-the-art multi-agent debate system. Further investigation shows that TreeDebater shows better strategies in limiting time to important debate actions, aligning with the strategies of human debate experts.
Focus Directions Make Your Language Models Pay More Attention to Relevant Contexts
Mar 30, 2025Long-context large language models (LLMs) are prone to be distracted by irrelevant contexts. The reason for distraction remains poorly understood. In this paper, we first identify the contextual heads, a special group of attention heads that control the overall attention of the LLM. Then, we demonstrate that distraction arises when contextual heads fail to allocate sufficient attention to relevant contexts and can be mitigated by increasing attention to these contexts. We further identify focus directions, located at the key and query activations of these heads, which enable them to allocate more attention to relevant contexts without explicitly specifying which context is relevant. We comprehensively evaluate the effect of focus direction on various long-context tasks and find out focus directions could help to mitigate the poor task alignment of the long-context LLMs. We believe our findings could promote further research on long-context LLM alignment.
Scaling LLM Inference with Optimized Sample Compute Allocation
Oct 29, 2024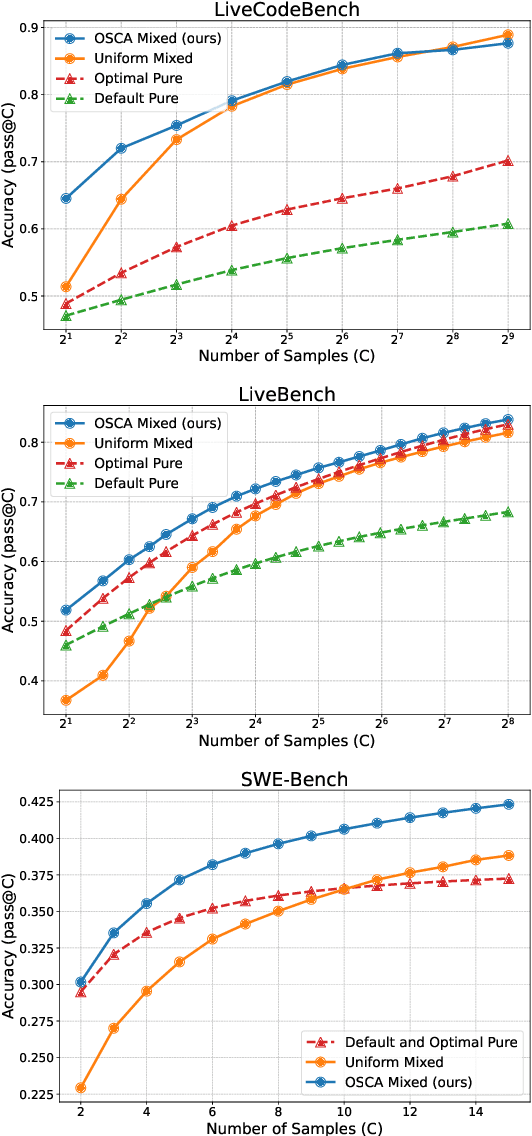
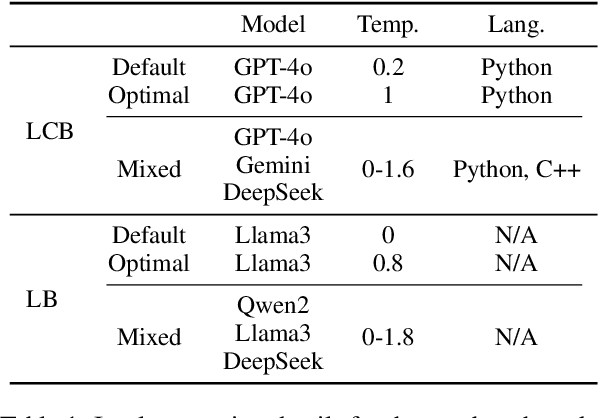
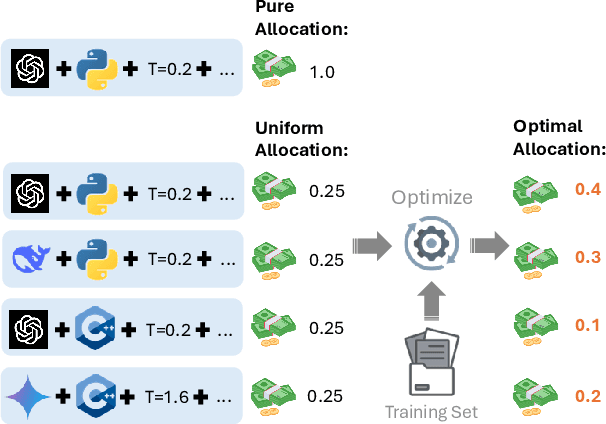
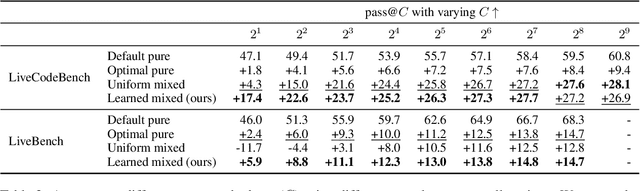
Sampling is a basic operation in many inference-time algorithms of large language models (LLMs). To scale up inference efficiently with a limited compute, it is crucial to find an optimal allocation for sample compute budgets: Which sampling configurations (model, temperature, language, etc.) do we use? How many samples do we generate in each configuration? We formulate these choices as a learning problem and propose OSCA, an algorithm that Optimizes Sample Compute Allocation by finding an optimal mix of different inference configurations. Our experiments show that with our learned mixed allocation, we can achieve accuracy better than the best single configuration with 128x less compute on code generation and 25x less compute on 4 reasoning tasks. OSCA is also shown to be effective in agentic workflows beyond single-turn tasks, achieving a better accuracy on SWE-Bench with 3x less compute than the default configuration. Our code and generations are released at https://github.com/LeiLiLab/OSCA.
Cooperative Strategic Planning Enhances Reasoning Capabilities in Large Language Models
Oct 25, 2024



Enhancing the reasoning capabilities of large language models (LLMs) is crucial for enabling them to tackle complex, multi-step problems. Multi-agent frameworks have shown great potential in enhancing LLMs' reasoning capabilities. However, the lack of effective cooperation between LLM agents hinders their performance, especially for multi-step reasoning tasks. This paper proposes a novel cooperative multi-agent reasoning framework (CoPlanner) by separating reasoning steps and assigning distinct duties to different agents. CoPlanner consists of two LLM agents: a planning agent and a reasoning agent. The planning agent provides high-level strategic hints, while the reasoning agent follows these hints and infers answers. By training the planning agent's policy through the interactive reasoning process via Proximal Policy Optimization (PPO), the LLaMA-3-8B-based CoPlanner outperforms the previous best method by 9.94\% on LogiQA and 3.09\% on BBH. Our results demonstrate that the guidance from the planning agent and the effective cooperation between the agents contribute to the superior performance of CoPlanner in tackling multi-step reasoning problems.
TypedThinker: Typed Thinking Improves Large Language Model Reasoning
Oct 02, 2024Despite significant advancements in the reasoning capabilities of Large Language Models (LLMs), the lack of diverse reasoning solutions often makes them trapped in a limited solution search area. In this paper, we propose TypedThinker, a novel framework that enhances LLMs' problem-solving abilities by incorporating multiple reasoning types (deductive, inductive, abductive, and analogical). Our analysis across four benchmarks reveals that different reasoning types uniquely solve distinct sets of problems, highlighting the importance of diverse thinking approaches. TypedThinker addresses two key challenges: selecting appropriate reasoning types for given problems and effectively implementing specific reasoning types. Through self-training on successful experiences, TypedThinker learns an implicit policy for reasoning type selection and application. Experimental results demonstrate significant improvements over baseline models, with accuracy increases of 3.4% for Mistral 7B and 16.7% for LLaMA3 8B across four reasoning benchmarks. Notably, TypedThinker shows effective generalization to new benchmarks and can further enhance the reasoning capability of powerful models like GPT-4o. The code is released at https://github.com/dqwang122/ThinkHub.
Global Human-guided Counterfactual Explanations for Molecular Properties via Reinforcement Learning
Jun 19, 2024Counterfactual explanations of Graph Neural Networks (GNNs) offer a powerful way to understand data that can naturally be represented by a graph structure. Furthermore, in many domains, it is highly desirable to derive data-driven global explanations or rules that can better explain the high-level properties of the models and data in question. However, evaluating global counterfactual explanations is hard in real-world datasets due to a lack of human-annotated ground truth, which limits their use in areas like molecular sciences. Additionally, the increasing scale of these datasets provides a challenge for random search-based methods. In this paper, we develop a novel global explanation model RLHEX for molecular property prediction. It aligns the counterfactual explanations with human-defined principles, making the explanations more interpretable and easy for experts to evaluate. RLHEX includes a VAE-based graph generator to generate global explanations and an adapter to adjust the latent representation space to human-defined principles. Optimized by Proximal Policy Optimization (PPO), the global explanations produced by RLHEX cover 4.12% more input graphs and reduce the distance between the counterfactual explanation set and the input set by 0.47% on average across three molecular datasets. RLHEX provides a flexible framework to incorporate different human-designed principles into the counterfactual explanation generation process, aligning these explanations with domain expertise. The code and data are released at https://github.com/dqwang122/RLHEX.
End-to-end Story Plot Generator
Oct 13, 2023Story plots, while short, carry most of the essential information of a full story that may contain tens of thousands of words. We study the problem of automatic generation of story plots, which includes story premise, character descriptions, plot outlines, etc. To generate a single engaging plot, existing plot generators (e.g., DOC (Yang et al., 2022a)) require hundreds to thousands of calls to LLMs (e.g., OpenAI API) in the planning stage of the story plot, which is costly and takes at least several minutes. Moreover, the hard-wired nature of the method makes the pipeline non-differentiable, blocking fast specialization and personalization of the plot generator. In this paper, we propose three models, $\texttt{OpenPlot}$, $\texttt{E2EPlot}$ and $\texttt{RLPlot}$, to address these challenges. $\texttt{OpenPlot}$ replaces expensive OpenAI API calls with LLaMA2 (Touvron et al., 2023) calls via careful prompt designs, which leads to inexpensive generation of high-quality training datasets of story plots. We then train an end-to-end story plot generator, $\texttt{E2EPlot}$, by supervised fine-tuning (SFT) using approximately 13000 story plots generated by $\texttt{OpenPlot}$. $\texttt{E2EPlot}$ generates story plots of comparable quality to $\texttt{OpenPlot}$, and is > 10$\times$ faster (1k tokens in only 30 seconds on average). Finally, we obtain $\texttt{RLPlot}$ that is further fine-tuned with RLHF on several different reward models for different aspects of story quality, which yields 60.0$\%$ winning rate against $\texttt{E2EPlot}$ along the aspect of suspense and surprise.
Learning Personalized Story Evaluation
Oct 10, 2023While large language models (LLMs) have shown impressive results for more objective tasks such as QA and retrieval, it remains nontrivial to evaluate their performance on open-ended text generation for reasons including (1) data contamination; (2) multi-dimensional evaluation criteria; and (3) subjectiveness stemming from reviewers' personal preferences. To address such issues, we propose to model personalization in an uncontaminated open-ended generation assessment. We create two new datasets Per-MPST and Per-DOC for personalized story evaluation, by re-purposing existing datasets with proper anonymization and new personalized labels. We further develop a personalized story evaluation model PERSE to infer reviewer preferences and provide a personalized evaluation. Specifically, given a few exemplary reviews from a particular reviewer, PERSE predicts either a detailed review or fine-grained comparison in several aspects (such as interestingness and surprise) for that reviewer on a new text input. Experimental results show that PERSE outperforms GPT-4 by 15.8% on Kendall correlation of story ratings, and by 13.7% on pairwise preference prediction accuracy. Both datasets and code will be released.