 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Privacy Preservation and Utility in Online Vision-Language Models
Apr 06, 2026The increasing use of Online Vision Language Models (OVLMs) for processing images has introduced significant privacy risks, as individuals frequently upload images for various utilities, unaware of the potential for privacy violations. Images contain relationships that relate to Personally Identifiable Information (PII), where even seemingly harmless details can indirectly reveal sensitive information through surrounding clues. This paper explores the critical issue of PII disclosure in images uploaded to OVLMs and its implications for user privacy. We investigate how the extraction of contextual relationships from images can lead to direct (explicit) or indirect (implicit) exposure of PII, significantly compromising personal privacy. Furthermore, we propose methods to protect privacy while preserving the intended utility of the images in Vision Language Model (VLM)-based applications. Our evaluation demonstrates the efficacy of these techniques, highlighting the delicate balance between maintaining utility and protecting privacy in online image processing environments. Index Terms-Personally Identifiable Information (PII), Privacy, Utility, privacy concerns, sensitive information
SurgGoal: Rethinking Surgical Planning Evaluation via Goal-Satisfiability
Jan 15, 2026Surgical planning integrates visual perception, long-horizon reasoning, and procedural knowledge, yet it remains unclear whether current evaluation protocols reliably assess vision-language models (VLMs) in safety-critical settings. Motivated by a goal-oriented view of surgical planning, we define planning correctness via phase-goal satisfiability, where plan validity is determined by expert-defined surgical rules. Based on this definition, we introduce a multicentric meta-evaluation benchmark with valid procedural variations and invalid plans containing order and content errors. Using this benchmark, we show that sequence similarity metrics systematically misjudge planning quality, penalizing valid plans while failing to identify invalid ones. We therefore adopt a rule-based goal-satisfiability metric as a high-precision meta-evaluation reference to assess Video-LLMs under progressively constrained settings, revealing failures due to perception errors and under-constrained reasoning. Structural knowledge consistently improves performance, whereas semantic guidance alone is unreliable and benefits larger models only when combined with structural constraints.
Cog-TiPRO: Iterative Prompt Refinement with LLMs to Detect Cognitive Decline via Longitudinal Voice Assistant Commands
May 22, 2025Early detection of cognitive decline is crucial for enabling interventions that can slow neurodegenerative disease progression. Traditional diagnostic approaches rely on labor-intensive clinical assessments, which are impractical for frequent monitoring. Our pilot study investigates voice assistant systems (VAS) as non-invasive tools for detecting cognitive decline through longitudinal analysis of speech patterns in voice commands. Over an 18-month period, we collected voice commands from 35 older adults, with 15 participants providing daily at-home VAS interactions. To address the challenges of analyzing these short, unstructured and noisy commands, we propose Cog-TiPRO, a framework that combines (1) LLM-driven iterative prompt refinement for linguistic feature extraction, (2) HuBERT-based acoustic feature extraction, and (3) transformer-based temporal modeling. Using iTransformer, our approach achieves 73.80% accuracy and 72.67% F1-score in detecting MCI, outperforming its baseline by 27.13%. Through our LLM approach, we identify linguistic features that uniquely characterize everyday command usage patterns in individuals experiencing cognitive decline.
Focus Directions Make Your Language Models Pay More Attention to Relevant Contexts
Mar 30, 2025Long-context large language models (LLMs) are prone to be distracted by irrelevant contexts. The reason for distraction remains poorly understood. In this paper, we first identify the contextual heads, a special group of attention heads that control the overall attention of the LLM. Then, we demonstrate that distraction arises when contextual heads fail to allocate sufficient attention to relevant contexts and can be mitigated by increasing attention to these contexts. We further identify focus directions, located at the key and query activations of these heads, which enable them to allocate more attention to relevant contexts without explicitly specifying which context is relevant. We comprehensively evaluate the effect of focus direction on various long-context tasks and find out focus directions could help to mitigate the poor task alignment of the long-context LLMs. We believe our findings could promote further research on long-context LLM alignment.
UMB@PerAnsSumm 2025: Enhancing Perspective-Aware Summarization with Prompt Optimization and Supervised Fine-Tuning
Mar 14, 2025



We present our approach to the PerAnsSumm Shared Task, which involves perspective span identification and perspective-aware summarization in community question-answering (CQA) threads. For span identification, we adopt ensemble learning that integrates three transformer models through averaging to exploit individual model strengths, achieving an 82.91% F1-score on test data. For summarization, we design a suite of Chain-of-Thought (CoT) prompting strategies that incorporate keyphrases and guide information to structure summary generation into manageable steps. To further enhance summary quality, we apply prompt optimization using the DSPy framework and supervised fine-tuning (SFT) on Llama-3 to adapt the model to domain-specific data. Experimental results on validation and test sets show that structured prompts with keyphrases and guidance improve summaries aligned with references, while the combination of prompt optimization and fine-tuning together yields significant improvement in both relevance and factuality evaluation metrics.
Analyzing Multimodal Features of Spontaneous Voice Assistant Commands for Mild Cognitive Impairment Detection
Nov 06, 2024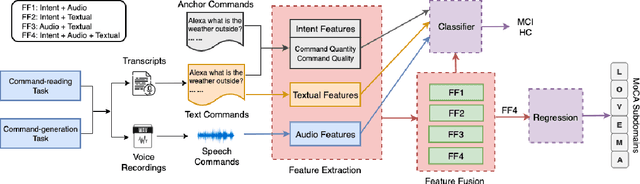

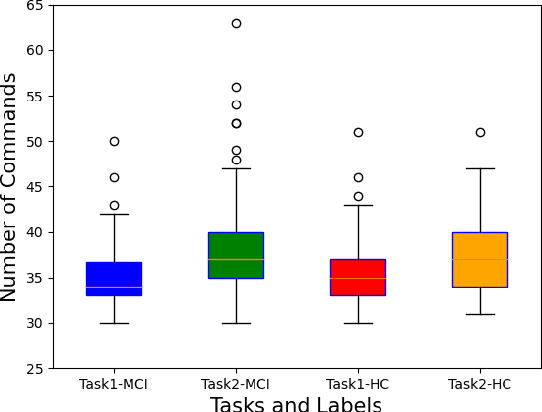
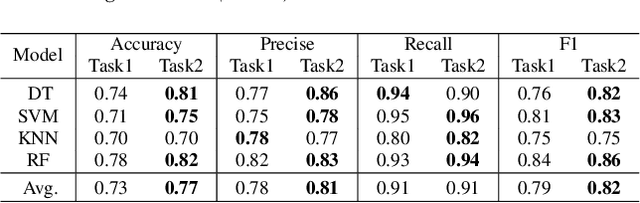
Mild cognitive impairment (MCI) is a major public health concern due to its high risk of progressing to dementia. This study investigates the potential of detecting MCI with spontaneous voice assistant (VA) commands from 35 older adults in a controlled setting. Specifically, a command-generation task is designed with pre-defined intents for participants to freely generate commands that are more associated with cognitive ability than read commands. We develop MCI classification and regression models with audio, textual, intent, and multimodal fusion features. We find the command-generation task outperforms the command-reading task with an average classification accuracy of 82%, achieved by leveraging multimodal fusion features. In addition, generated commands correlate more strongly with memory and attention subdomains than read commands. Our results confirm the effectiveness of the command-generation task and imply the promise of using longitudinal in-home commands for MCI detection.
Classification, Regression and Segmentation directly from k-Space in Cardiac MRI
Jul 29, 2024
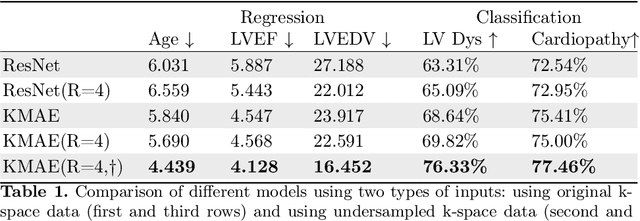
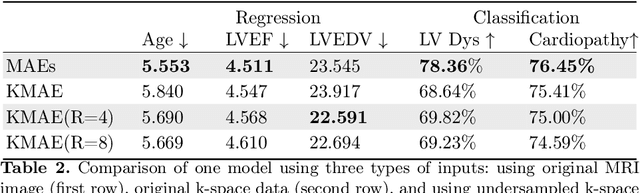

Cardiac Magnetic Resonance Imaging (CMR) is the gold standard for diagnosing cardiovascular diseases. Clinical diagnoses predominantly rely on magnitude-only Digital Imaging and Communications in Medicine (DICOM) images, omitting crucial phase information that might provide additional diagnostic benefits. In contrast, k-space is complex-valued and encompasses both magnitude and phase information, while humans cannot directly perceive. In this work, we propose KMAE, a Transformer-based model specifically designed to process k-space data directly, eliminating conventional intermediary conversion steps to the image domain. KMAE can handle critical cardiac disease classification, relevant phenotype regression, and cardiac morphology segmentation tasks. We utilize this model to investigate the potential of k-space-based diagnosis in cardiac MRI. Notably, this model achieves competitive classification and regression performance compared to image-domain methods e.g. Masked Autoencoders (MAEs) and delivers satisfactory segmentation performance with a myocardium dice score of 0.884. Last but not least, our model exhibits robust performance with consistent results even when the k-space is 8* undersampled. We encourage the MR community to explore the untapped potential of k-space and pursue end-to-end, automated diagnosis with reduced human intervention.
Evaluating Picture Description Speech for Dementia Detection using Image-text Alignment
Aug 11, 2023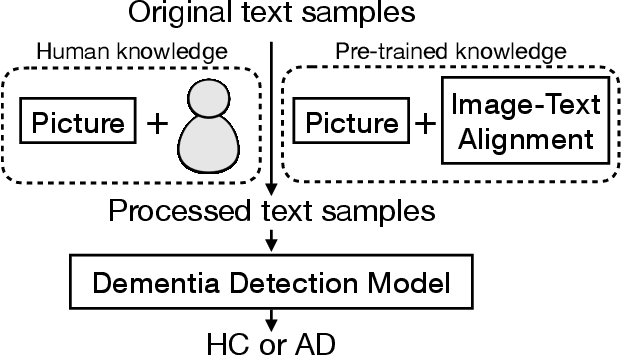



Using picture description speech for dementia detection has been studied for 30 years. Despite the long history, previous models focus on identifying the differences in speech patterns between healthy subjects and patients with dementia but do not utilize the picture information directly. In this paper, we propose the first dementia detection models that take both the picture and the description texts as inputs and incorporate knowledge from large pre-trained image-text alignment models. We observe the difference between dementia and healthy samples in terms of the text's relevance to the picture and the focused area of the picture. We thus consider such a difference could be used to enhance dementia detection accuracy. Specifically, we use the text's relevance to the picture to rank and filter the sentences of the samples. We also identified focused areas of the picture as topics and categorized the sentences according to the focused areas. We propose three advanced models that pre-processed the samples based on their relevance to the picture, sub-image, and focused areas. The evaluation results show that our advanced models, with knowledge of the picture and large image-text alignment models, achieve state-of-the-art performance with the best detection accuracy at 83.44%, which is higher than the text-only baseline model at 79.91%. Lastly, we visualize the sample and picture results to explain the advantages of our models.
Speech Tasks Relevant to Sleepiness Determined with Deep Transfer Learning
Nov 29, 2021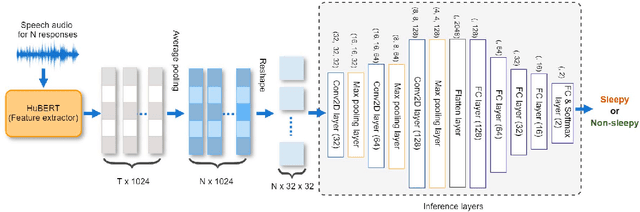
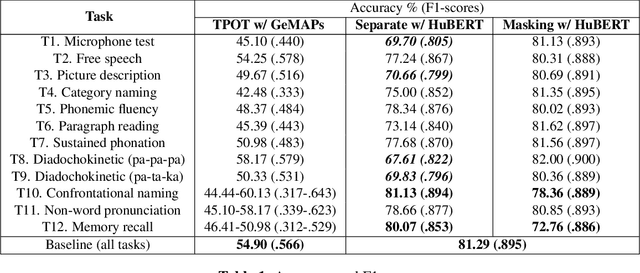
Excessive sleepiness in attention-critical contexts can lead to adverse events, such as car crashes. Detecting and monitoring sleepiness can help prevent these adverse events from happening. In this paper, we use the Voiceome dataset to extract speech from 1,828 participants to develop a deep transfer learning model using Hidden-Unit BERT (HuBERT) speech representations to detect sleepiness from individuals. Speech is an under-utilized source of data in sleep detection, but as speech collection is easy, cost-effective, and non-invasive, it provides a promising resource for sleepiness detection. Two complementary techniques were conducted in order to seek converging evidence regarding the importance of individual speech tasks. Our first technique, masking, evaluated task importance by combining all speech tasks, masking selected responses in the speech, and observing systematic changes in model accuracy. Our second technique, separate training, compared the accuracy of multiple models, each of which used the same architecture, but was trained on a different subset of speech tasks. Our evaluation shows that the best-performing model utilizes the memory recall task and categorical naming task from the Boston Naming Test, which achieved an accuracy of 80.07% (F1-score of 0.85) and 81.13% (F1-score of 0.89), respectively.
Towards Interpretability of Speech Pause in Dementia Detection using Adversarial Learning
Nov 14, 2021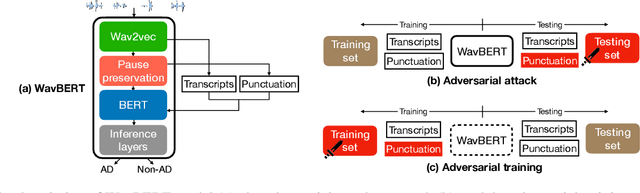
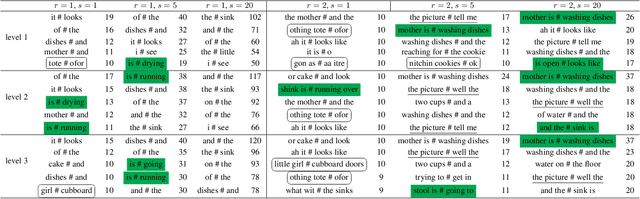

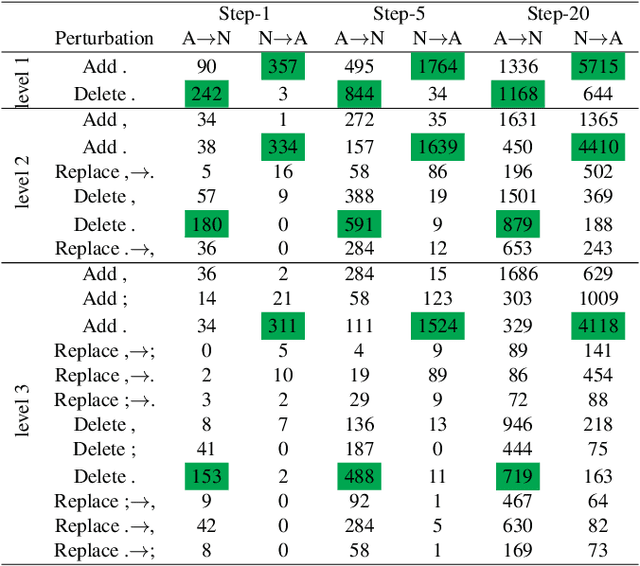
Speech pause is an effective biomarker in dementia detection. Recent deep learning models have exploited speech pauses to achieve highly accurate dementia detection, but have not exploited the interpretability of speech pauses, i.e., what and how positions and lengths of speech pauses affect the result of dementia detection. In this paper, we will study the positions and lengths of dementia-sensitive pauses using adversarial learning approaches. Specifically, we first utilize an adversarial attack approach by adding the perturbation to the speech pauses of the testing samples, aiming to reduce the confidence levels of the detection model. Then, we apply an adversarial training approach to evaluate the impact of the perturbation in training samples on the detection model. We examine the interpretability from the perspectives of model accuracy, pause context, and pause length. We found that some pauses are more sensitive to dementia than other pauses from the model's perspective, e.g., speech pauses near to the verb "is". Increasing lengths of sensitive pauses or adding sensitive pauses leads the model inference to Alzheimer's Disease, while decreasing the lengths of sensitive pauses or deleting sensitive pauses leads to non-AD.