 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Multimodal Features of Spontaneous Voice Assistant Commands for Mild Cognitive Impairment Detection
Nov 06, 2024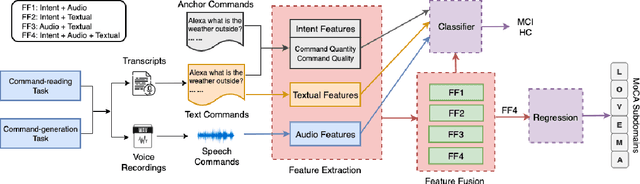

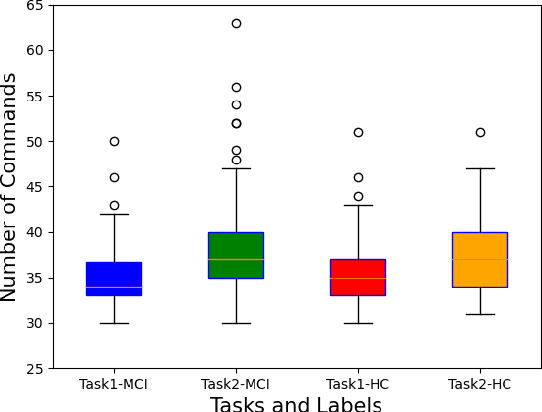
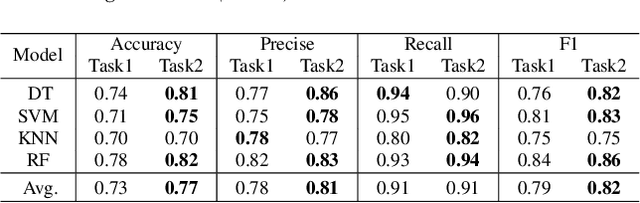
Mild cognitive impairment (MCI) is a major public health concern due to its high risk of progressing to dementia. This study investigates the potential of detecting MCI with spontaneous voice assistant (VA) commands from 35 older adults in a controlled setting. Specifically, a command-generation task is designed with pre-defined intents for participants to freely generate commands that are more associated with cognitive ability than read commands. We develop MCI classification and regression models with audio, textual, intent, and multimodal fusion features. We find the command-generation task outperforms the command-reading task with an average classification accuracy of 82%, achieved by leveraging multimodal fusion features. In addition, generated commands correlate more strongly with memory and attention subdomains than read commands. Our results confirm the effectiveness of the command-generation task and imply the promise of using longitudinal in-home commands for MCI detection.
Evaluating Picture Description Speech for Dementia Detection using Image-text Alignment
Aug 11, 2023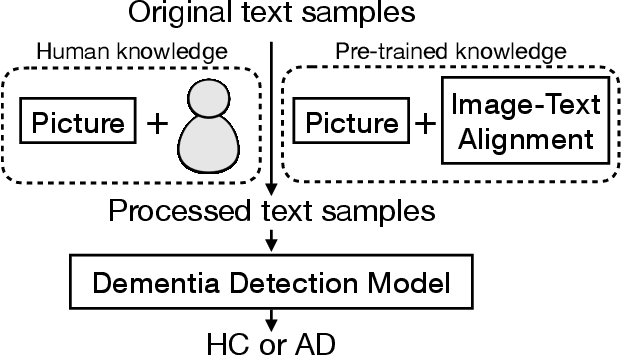



Using picture description speech for dementia detection has been studied for 30 years. Despite the long history, previous models focus on identifying the differences in speech patterns between healthy subjects and patients with dementia but do not utilize the picture information directly. In this paper, we propose the first dementia detection models that take both the picture and the description texts as inputs and incorporate knowledge from large pre-trained image-text alignment models. We observe the difference between dementia and healthy samples in terms of the text's relevance to the picture and the focused area of the picture. We thus consider such a difference could be used to enhance dementia detection accuracy. Specifically, we use the text's relevance to the picture to rank and filter the sentences of the samples. We also identified focused areas of the picture as topics and categorized the sentences according to the focused areas. We propose three advanced models that pre-processed the samples based on their relevance to the picture, sub-image, and focused areas. The evaluation results show that our advanced models, with knowledge of the picture and large image-text alignment models, achieve state-of-the-art performance with the best detection accuracy at 83.44%, which is higher than the text-only baseline model at 79.91%. Lastly, we visualize the sample and picture results to explain the advantages of our models.