 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Tasks Relevant to Sleepiness Determined with Deep Transfer Learning
Nov 29, 2021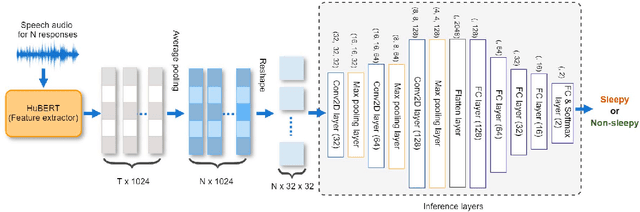
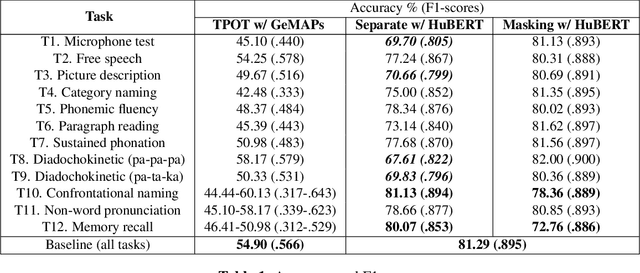
Excessive sleepiness in attention-critical contexts can lead to adverse events, such as car crashes. Detecting and monitoring sleepiness can help prevent these adverse events from happening. In this paper, we use the Voiceome dataset to extract speech from 1,828 participants to develop a deep transfer learning model using Hidden-Unit BERT (HuBERT) speech representations to detect sleepiness from individuals. Speech is an under-utilized source of data in sleep detection, but as speech collection is easy, cost-effective, and non-invasive, it provides a promising resource for sleepiness detection. Two complementary techniques were conducted in order to seek converging evidence regarding the importance of individual speech tasks. Our first technique, masking, evaluated task importance by combining all speech tasks, masking selected responses in the speech, and observing systematic changes in model accuracy. Our second technique, separate training, compared the accuracy of multiple models, each of which used the same architecture, but was trained on a different subset of speech tasks. Our evaluation shows that the best-performing model utilizes the memory recall task and categorical naming task from the Boston Naming Test, which achieved an accuracy of 80.07% (F1-score of 0.85) and 81.13% (F1-score of 0.89), respectively.
Towards Interpretability of Speech Pause in Dementia Detection using Adversarial Learning
Nov 14, 2021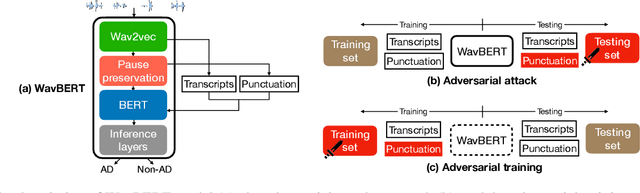
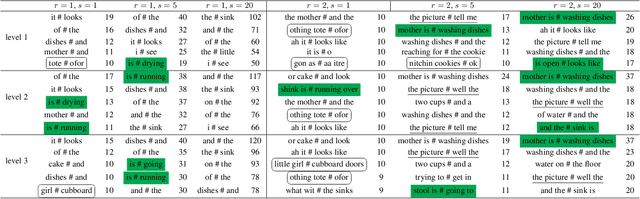

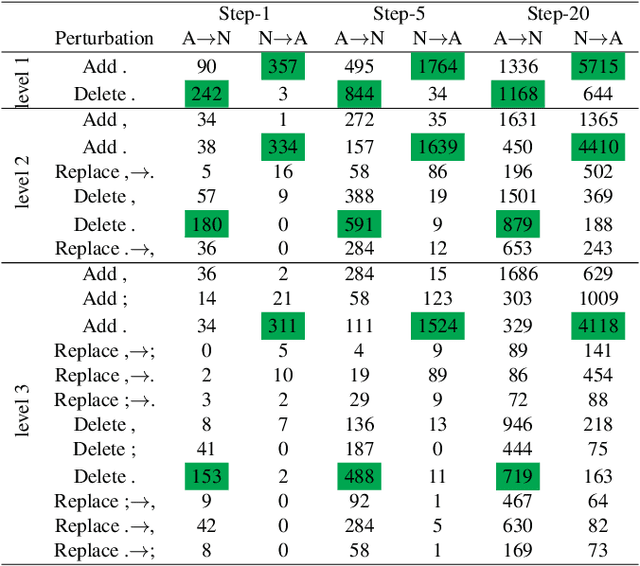
Speech pause is an effective biomarker in dementia detection. Recent deep learning models have exploited speech pauses to achieve highly accurate dementia detection, but have not exploited the interpretability of speech pauses, i.e., what and how positions and lengths of speech pauses affect the result of dementia detection. In this paper, we will study the positions and lengths of dementia-sensitive pauses using adversarial learning approaches. Specifically, we first utilize an adversarial attack approach by adding the perturbation to the speech pauses of the testing samples, aiming to reduce the confidence levels of the detection model. Then, we apply an adversarial training approach to evaluate the impact of the perturbation in training samples on the detection model. We examine the interpretability from the perspectives of model accuracy, pause context, and pause length. We found that some pauses are more sensitive to dementia than other pauses from the model's perspective, e.g., speech pauses near to the verb "is". Increasing lengths of sensitive pauses or adding sensitive pauses leads the model inference to Alzheimer's Disease, while decreasing the lengths of sensitive pauses or deleting sensitive pauses leads to non-AD.