 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Reasoning Tokens and Boilerplate Tokens For Language Model Fine-tuning
Dec 19, 2024



When using agent-task datasets to enhance agent capabilities for Large Language Models (LLMs), current methodologies often treat all tokens within a sample equally. However, we argue that tokens serving different roles - specifically, reasoning tokens versus boilerplate tokens (e.g., those governing output format) - differ significantly in importance and learning complexity, necessitating their disentanglement and distinct treatment. To address this, we propose a novel Shuffle-Aware Discriminator (SHAD) for adaptive token discrimination. SHAD classifies tokens by exploiting predictability differences observed after shuffling input-output combinations across samples: boilerplate tokens, due to their repetitive nature among samples, maintain predictability, whereas reasoning tokens do not. Using SHAD, we propose the Reasoning-highlighted Fine-Tuning (RFT) method, which adaptively emphasizes reasoning tokens during fine-tuning, yielding notable performance gains over common Supervised Fine-Tuning (SFT).
TypedThinker: Typed Thinking Improves Large Language Model Reasoning
Oct 02, 2024Despite significant advancements in the reasoning capabilities of Large Language Models (LLMs), the lack of diverse reasoning solutions often makes them trapped in a limited solution search area. In this paper, we propose TypedThinker, a novel framework that enhances LLMs' problem-solving abilities by incorporating multiple reasoning types (deductive, inductive, abductive, and analogical). Our analysis across four benchmarks reveals that different reasoning types uniquely solve distinct sets of problems, highlighting the importance of diverse thinking approaches. TypedThinker addresses two key challenges: selecting appropriate reasoning types for given problems and effectively implementing specific reasoning types. Through self-training on successful experiences, TypedThinker learns an implicit policy for reasoning type selection and application. Experimental results demonstrate significant improvements over baseline models, with accuracy increases of 3.4% for Mistral 7B and 16.7% for LLaMA3 8B across four reasoning benchmarks. Notably, TypedThinker shows effective generalization to new benchmarks and can further enhance the reasoning capability of powerful models like GPT-4o. The code is released at https://github.com/dqwang122/ThinkHub.
Qwen2 Technical Report
Jul 16, 2024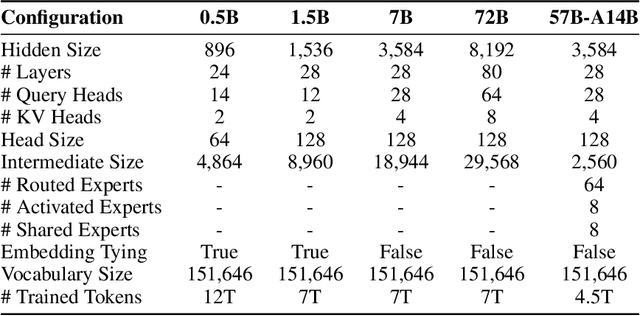
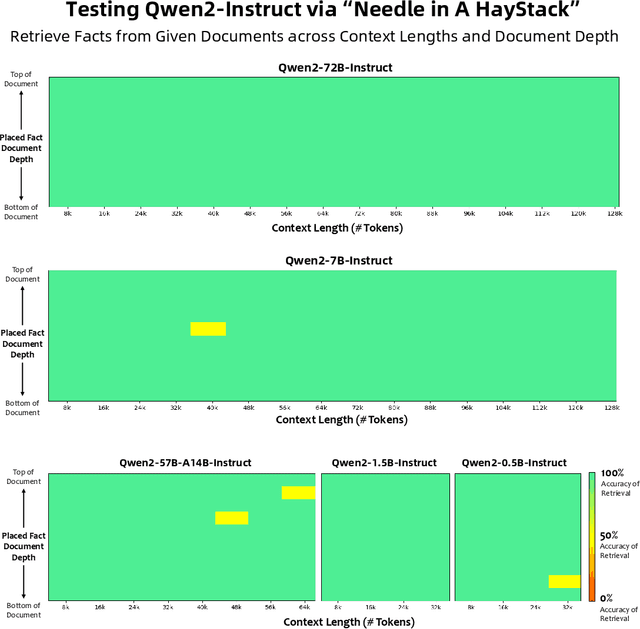
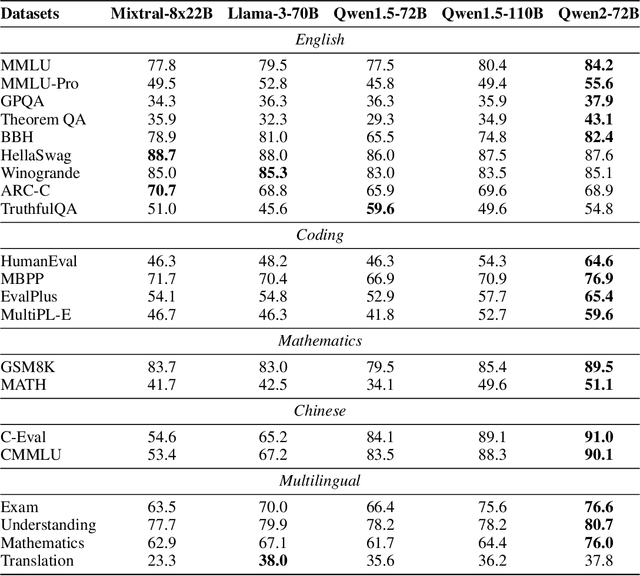
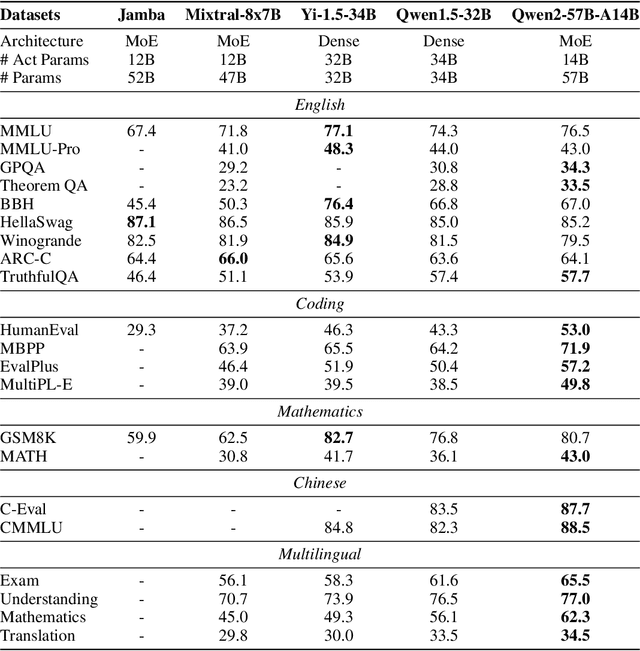
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
Controllable 3D Face Generation with Conditional Style Code Diffusion
Jan 11, 2024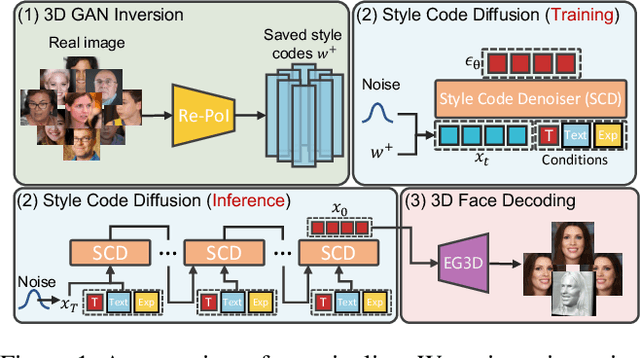


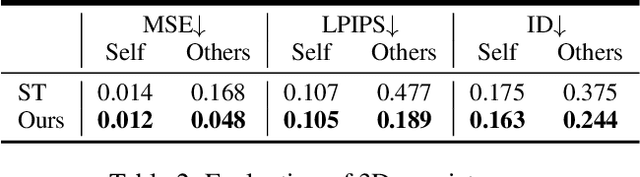
Generating photorealistic 3D faces from given conditions is a challenging task. Existing methods often rely on time-consuming one-by-one optimization approaches, which are not efficient for modeling the same distribution content, e.g., faces. Additionally, an ideal controllable 3D face generation model should consider both facial attributes and expressions. Thus we propose a novel approach called TEx-Face(TExt & Expression-to-Face) that addresses these challenges by dividing the task into three components, i.e., 3D GAN Inversion, Conditional Style Code Diffusion, and 3D Face Decoding. For 3D GAN inversion, we introduce two methods which aim to enhance the representation of style codes and alleviate 3D inconsistencies. Furthermore, we design a style code denoiser to incorporate multiple conditions into the style code and propose a data augmentation strategy to address the issue of insufficient paired visual-language data. Extensive experiments conducted on FFHQ, CelebA-HQ, and CelebA-Dialog demonstrate the promising performance of our TEx-Face in achieving the efficient and controllable generation of photorealistic 3D faces. The code will be available at https://github.com/sxl142/TEx-Face.
Qwen Technical Report
Sep 28, 2023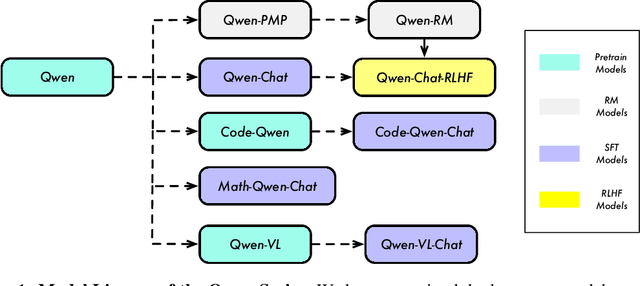

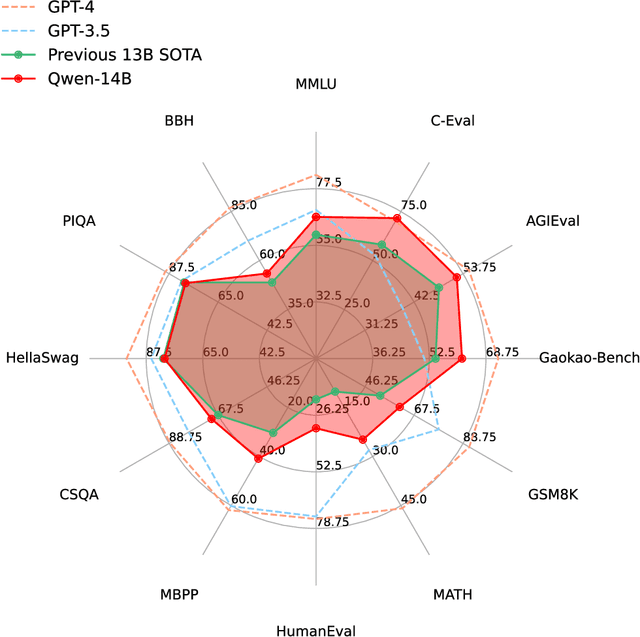
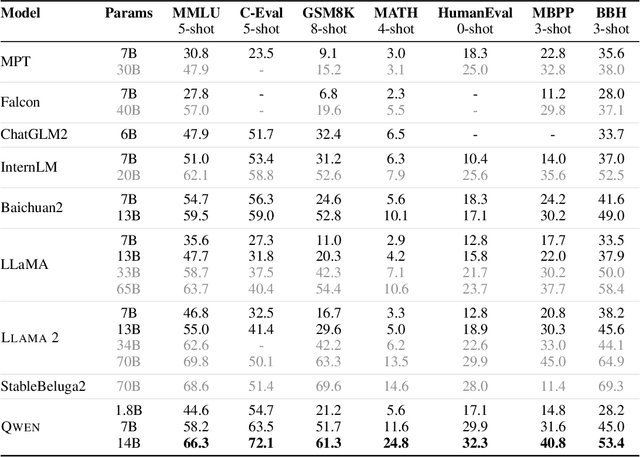
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
JOTR: 3D Joint Contrastive Learning with Transformers for Occluded Human Mesh Recovery
Aug 17, 2023In this study, we focus on the problem of 3D human mesh recovery from a single image under obscured conditions. Most state-of-the-art methods aim to improve 2D alignment technologies, such as spatial averaging and 2D joint sampling. However, they tend to neglect the crucial aspect of 3D alignment by improving 3D representations. Furthermore, recent methods struggle to separate the target human from occlusion or background in crowded scenes as they optimize the 3D space of target human with 3D joint coordinates as local supervision. To address these issues, a desirable method would involve a framework for fusing 2D and 3D features and a strategy for optimizing the 3D space globally. Therefore, this paper presents 3D JOint contrastive learning with TRansformers (JOTR) framework for handling occluded 3D human mesh recovery. Our method includes an encoder-decoder transformer architecture to fuse 2D and 3D representations for achieving 2D$\&$3D aligned results in a coarse-to-fine manner and a novel 3D joint contrastive learning approach for adding explicitly global supervision for the 3D feature space. The contrastive learning approach includes two contrastive losses: joint-to-joint contrast for enhancing the similarity of semantically similar voxels (i.e., human joints), and joint-to-non-joint contrast for ensuring discrimination from others (e.g., occlusions and background). Qualitative and quantitative analyses demonstrate that our method outperforms state-of-the-art competitors on both occlusion-specific and standard benchmarks, significantly improving the reconstruction of occluded humans.
TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering
Jul 23, 2023In this paper, we focus on the task of generalizable neural human rendering which trains conditional Neural Radiance Fields (NeRF) from multi-view videos of different characters. To handle the dynamic human motion, previous methods have primarily used a SparseConvNet (SPC)-based human representation to process the painted SMPL. However, such SPC-based representation i) optimizes under the volatile observation space which leads to the pose-misalignment between training and inference stages, and ii) lacks the global relationships among human parts that is critical for handling the incomplete painted SMPL. Tackling these issues, we present a brand-new framework named TransHuman, which learns the painted SMPL under the canonical space and captures the global relationships between human parts with transformers. Specifically, TransHuman is mainly composed of Transformer-based Human Encoding (TransHE), Deformable Partial Radiance Fields (DPaRF), and Fine-grained Detail Integration (FDI). TransHE first processes the painted SMPL under the canonical space via transformers for capturing the global relationships between human parts. Then, DPaRF binds each output token with a deformable radiance field for encoding the query point under the observation space. Finally, the FDI is employed to further integrate fine-grained information from reference images. Extensive experiments on ZJU-MoCap and H36M show that our TransHuman achieves a significantly new state-of-the-art performance with high efficiency. Project page: https://pansanity666.github.io/TransHuman/
Global-to-Local Modeling for Video-based 3D Human Pose and Shape Estimation
Mar 26, 2023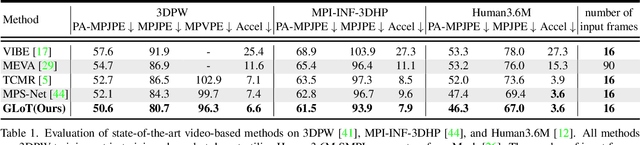
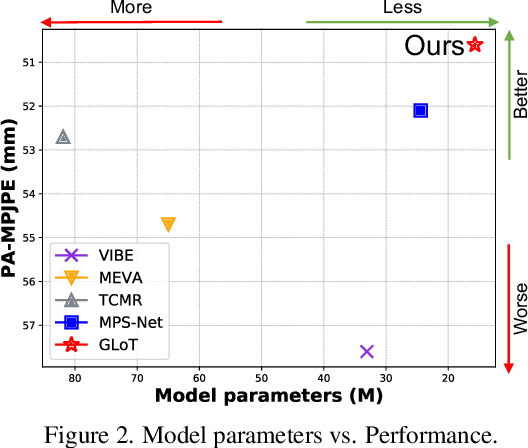
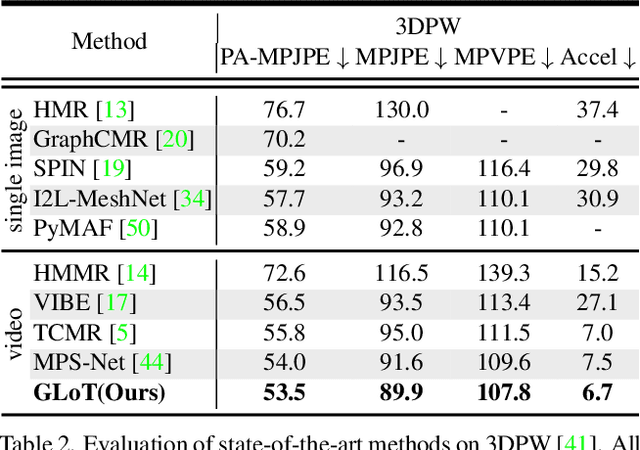

Video-based 3D human pose and shape estimations are evaluated by intra-frame accuracy and inter-frame smoothness. Although these two metrics are responsible for different ranges of temporal consistency, existing state-of-the-art methods treat them as a unified problem and use monotonous modeling structures (e.g., RNN or attention-based block) to design their networks. However, using a single kind of modeling structure is difficult to balance the learning of short-term and long-term temporal correlations, and may bias the network to one of them, leading to undesirable predictions like global location shift, temporal inconsistency, and insufficient local details. To solve these problems, we propose to structurally decouple the modeling of long-term and short-term correlations in an end-to-end framework, Global-to-Local Transformer (GLoT). First, a global transformer is introduced with a Masked Pose and Shape Estimation strategy for long-term modeling. The strategy stimulates the global transformer to learn more inter-frame correlations by randomly masking the features of several frames. Second, a local transformer is responsible for exploiting local details on the human mesh and interacting with the global transformer by leveraging cross-attention. Moreover, a Hierarchical Spatial Correlation Regressor is further introduced to refine intra-frame estimations by decoupled global-local representation and implicit kinematic constraints. Our GLoT surpasses previous state-of-the-art methods with the lowest model parameters on popular benchmarks, i.e., 3DPW, MPI-INF-3DHP, and Human3.6M. Codes are available at https://github.com/sxl142/GLoT.
OFASys: A Multi-Modal Multi-Task Learning System for Building Generalist Models
Dec 08, 2022



Generalist models, which are capable of performing diverse multi-modal tasks in a task-agnostic way within a single model, have been explored recently. Being, hopefully, an alternative to approaching general-purpose AI, existing generalist models are still at an early stage, where modality and task coverage is limited. To empower multi-modal task-scaling and speed up this line of research, we release a generalist model learning system, OFASys, built on top of a declarative task interface named multi-modal instruction. At the core of OFASys is the idea of decoupling multi-modal task representations from the underlying model implementations. In OFASys, a task involving multiple modalities can be defined declaratively even with just a single line of code. The system automatically generates task plans from such instructions for training and inference. It also facilitates multi-task training for diverse multi-modal workloads. As a starting point, we provide presets of 7 different modalities and 23 highly-diverse example tasks in OFASys, with which we also develop a first-in-kind, single model, OFA+, that can handle text, image, speech, video, and motion data. The single OFA+ model achieves 95% performance in average with only 16% parameters of 15 task-finetuned models, showcasing the performance reliability of multi-modal task-scaling provided by OFASys. Available at https://github.com/OFA-Sys/OFASys
Pretrained Diffusion Models for Unified Human Motion Synthesis
Dec 06, 2022
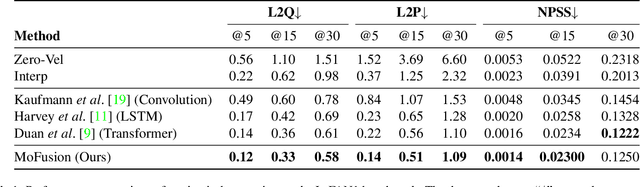


Generative modeling of human motion has broad applications in computer animation, virtual reality, and robotics. Conventional approaches develop separate models for different motion synthesis tasks, and typically use a model of a small size to avoid overfitting the scarce data available in each setting. It remains an open question whether developing a single unified model is feasible, which may 1) benefit the acquirement of novel skills by combining skills learned from multiple tasks, and 2) help in increasing the model capacity without overfitting by combining multiple data sources. Unification is challenging because 1) it involves diverse control signals as well as targets of varying granularity, and 2) motion datasets may use different skeletons and default poses. In this paper, we present MoFusion, a framework for unified motion synthesis. MoFusion employs a Transformer backbone to ease the inclusion of diverse control signals via cross attention, and pretrains the backbone as a diffusion model to support multi-granularity synthesis ranging from motion completion of a body part to whole-body motion generation. It uses a learnable adapter to accommodate the differences between the default skeletons used by the pretraining and the fine-tuning data. Empirical results show that pretraining is vital for scaling the model size without overfitting, and demonstrate MoFusion's potential in various tasks, e.g., text-to-motion, motion completion, and zero-shot mixing of multiple control signals. Project page: \url{https://ofa-sys.github.io/MoFusion/}.