 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Agentic Verifier for Competitive Coding
Feb 04, 2026Large language models (LLMs) have demonstrated strong coding capabilities but still struggle to solve competitive programming problems correctly in a single attempt. Execution-based re-ranking offers a promising test-time scaling strategy, yet existing methods are constrained by either difficult test case generation or inefficient random input sampling. To address this limitation, we propose Agentic Verifier, an execution-based agent that actively reasons about program behaviors and searches for highly discriminative test inputs that expose behavioral discrepancies among candidate solutions. Through multi-turn interaction with code execution environments, the verifier iteratively refines the candidate input generator and produces targeted counterexamples rather than blindly sampling inputs. We train the verifier to acquire this discriminative input generation capability via a scalable pipeline combining large-scale data synthesis, rejection fine-tuning, and agentic reinforcement learning. Extensive experiments across five competitive programming benchmarks demonstrate consistent improvements over strong execution-based baselines, achieving up to +10-15% absolute gains in Best@K accuracy. Further analysis reveals clear test-time scaling behavior and highlights the verifier's broader potential beyond reranking.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Evaluating and Achieving Controllable Code Completion in Code LLM
Jan 22, 2026Code completion has become a central task, gaining significant attention with the rise of large language model (LLM)-based tools in software engineering. Although recent advances have greatly improved LLMs' code completion abilities, evaluation methods have not advanced equally. Most current benchmarks focus solely on functional correctness of code completions based on given context, overlooking models' ability to follow user instructions during completion-a common scenario in LLM-assisted programming. To address this limitation, we present the first instruction-guided code completion benchmark, Controllable Code Completion Benchmark (C3-Bench), comprising 2,195 carefully designed completion tasks. Through comprehensive evaluation of over 40 mainstream LLMs across C3-Bench and conventional benchmarks, we reveal substantial gaps in instruction-following capabilities between open-source and advanced proprietary models during code completion tasks. Moreover, we develop a straightforward data synthesis pipeline that leverages Qwen2.5-Coder to generate high-quality instruction-completion pairs for supervised fine-tuning (SFT). The resulting model, Qwen2.5-Coder-C3, achieves state-of-the-art performance on C3-Bench. Our findings provide valuable insights for enhancing LLMs' code completion and instruction-following capabilities, establishing new directions for future research in code LLMs. To facilitate reproducibility and foster further research in code LLMs, we open-source all code, datasets, and models.
From Completion to Editing: Unlocking Context-Aware Code Infilling via Search-and-Replace Instruction Tuning
Jan 19, 2026The dominant Fill-in-the-Middle (FIM) paradigm for code completion is constrained by its rigid inability to correct contextual errors and reliance on unaligned, insecure Base models. While Chat LLMs offer safety and Agentic workflows provide flexibility, they suffer from performance degradation and prohibitive latency, respectively. To resolve this dilemma, we propose Search-and-Replace Infilling (SRI), a framework that internalizes the agentic verification-and-editing mechanism into a unified, single-pass inference process. By structurally grounding edits via an explicit search phase, SRI harmonizes completion tasks with the instruction-following priors of Chat LLMs, extending the paradigm from static infilling to dynamic context-aware editing. We synthesize a high-quality dataset, SRI-200K, and fine-tune the SRI-Coder series. Extensive evaluations demonstrate that with minimal data (20k samples), SRI-Coder enables Chat models to surpass the completion performance of their Base counterparts. Crucially, unlike FIM-style tuning, SRI preserves general coding competencies and maintains inference latency comparable to standard FIM. We empower the entire Qwen3-Coder series with SRI, encouraging the developer community to leverage this framework for advanced auto-completion and assisted development.
SWE-RM: Execution-free Feedback For Software Engineering Agents
Dec 26, 2025
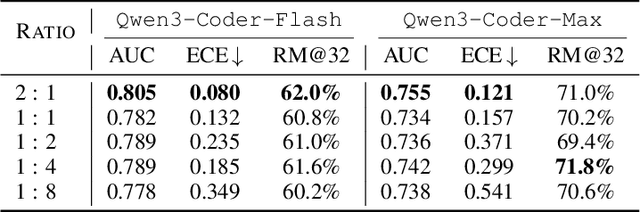

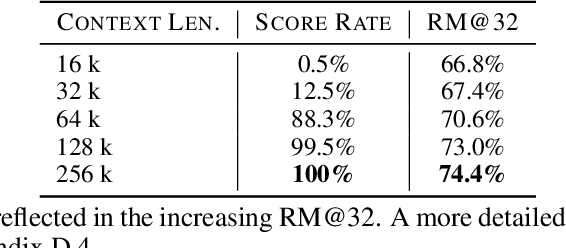
Execution-based feedback like unit testing is widely used in the development of coding agents through test-time scaling (TTS) and reinforcement learning (RL). This paradigm requires scalable and reliable collection of unit test cases to provide accurate feedback, and the resulting feedback is often sparse and cannot effectively distinguish between trajectories that are both successful or both unsuccessful. In contrast, execution-free feedback from reward models can provide more fine-grained signals without depending on unit test cases. Despite this potential, execution-free feedback for realistic software engineering (SWE) agents remains underexplored. Aiming to develop versatile reward models that are effective across TTS and RL, however, we observe that two verifiers with nearly identical TTS performance can nevertheless yield very different results in RL. Intuitively, TTS primarily reflects the model's ability to select the best trajectory, but this ability does not necessarily generalize to RL. To address this limitation, we identify two additional aspects that are crucial for RL training: classification accuracy and calibration. We then conduct comprehensive controlled experiments to investigate how to train a robust reward model that performs well across these metrics. In particular, we analyze the impact of various factors such as training data scale, policy mixtures, and data source composition. Guided by these investigations, we introduce SWE-RM, an accurate and robust reward model adopting a mixture-of-experts architecture with 30B total parameters and 3B activated during inference. SWE-RM substantially improves SWE agents on both TTS and RL performance. For example, it increases the accuracy of Qwen3-Coder-Flash from 51.6% to 62.0%, and Qwen3-Coder-Max from 67.0% to 74.6% on SWE-Bench Verified using TTS, achieving new state-of-the-art performance among open-source models.
IFEvalCode: Controlled Code Generation
Jul 30, 2025Code large language models (Code LLMs) have made significant progress in code generation by translating natural language descriptions into functional code; however, real-world applications often demand stricter adherence to detailed requirements such as coding style, line count, and structural constraints, beyond mere correctness. To address this, the paper introduces forward and backward constraints generation to improve the instruction-following capabilities of Code LLMs in controlled code generation, ensuring outputs align more closely with human-defined guidelines. The authors further present IFEvalCode, a multilingual benchmark comprising 1.6K test samples across seven programming languages (Python, Java, JavaScript, TypeScript, Shell, C++, and C#), with each sample featuring both Chinese and English queries. Unlike existing benchmarks, IFEvalCode decouples evaluation into two metrics: correctness (Corr.) and instruction-following (Instr.), enabling a more nuanced assessment. Experiments on over 40 LLMs reveal that closed-source models outperform open-source ones in controllable code generation and highlight a significant gap between the models' ability to generate correct code versus code that precisely follows instructions.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025


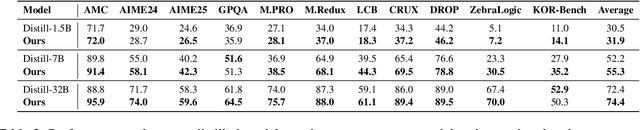
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
Jun 11, 2025We introduce **SWE-Flow**, a novel data synthesis framework grounded in Test-Driven Development (TDD). Unlike existing software engineering data that rely on human-submitted issues, **SWE-Flow** automatically infers incremental development steps directly from unit tests, which inherently encapsulate high-level requirements. The core of **SWE-Flow** is the construction of a Runtime Dependency Graph (RDG), which precisely captures function interactions, enabling the generation of a structured, step-by-step *development schedule*. At each step, **SWE-Flow** produces a partial codebase, the corresponding unit tests, and the necessary code modifications, resulting in fully verifiable TDD tasks. With this approach, we generated 16,061 training instances and 2,020 test instances from real-world GitHub projects, creating the **SWE-Flow-Eval** benchmark. Our experiments show that fine-tuning open model on this dataset significantly improves performance in TDD-based coding. To facilitate further research, we release all code, datasets, models, and Docker images at [Github](https://github.com/Hambaobao/SWE-Flow).
A Survey of LLM $\times$ DATA
May 24, 2025The integration of large language model (LLM) and data management (DATA) is rapidly redefining both domains. In this survey, we comprehensively review the bidirectional relationships. On the one hand, DATA4LLM, spanning large-scale data processing, storage, and serving, feeds LLMs with high quality, diversity, and timeliness of data required for stages like pre-training, post-training, retrieval-augmented generation, and agentic workflows: (i) Data processing for LLMs includes scalable acquisition, deduplication, filtering, selection, domain mixing, and synthetic augmentation; (ii) Data Storage for LLMs focuses on efficient data and model formats, distributed and heterogeneous storage hierarchies, KV-cache management, and fault-tolerant checkpointing; (iii) Data serving for LLMs tackles challenges in RAG (e.g., knowledge post-processing), LLM inference (e.g., prompt compression, data provenance), and training strategies (e.g., data packing and shuffling). On the other hand, in LLM4DATA, LLMs are emerging as general-purpose engines for data management. We review recent advances in (i) data manipulation, including automatic data cleaning, integration, discovery; (ii) data analysis, covering reasoning over structured, semi-structured, and unstructured data, and (iii) system optimization (e.g., configuration tuning, query rewriting, anomaly diagnosis), powered by LLM techniques like retrieval-augmented prompting, task-specialized fine-tuning, and multi-agent collaboration.
Parallel Scaling Law for Language Models
May 15, 2025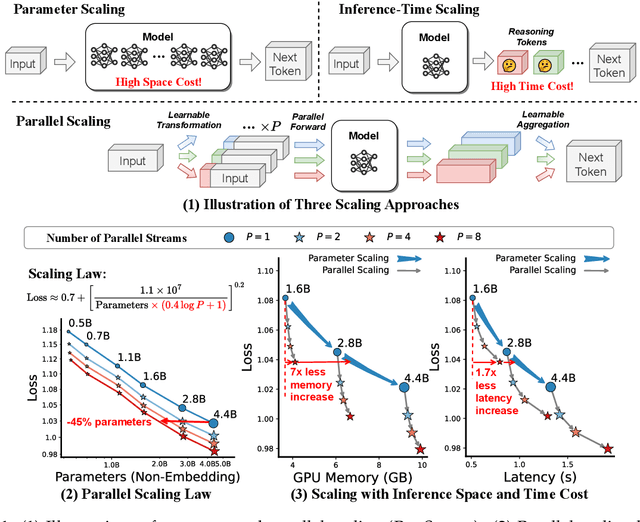

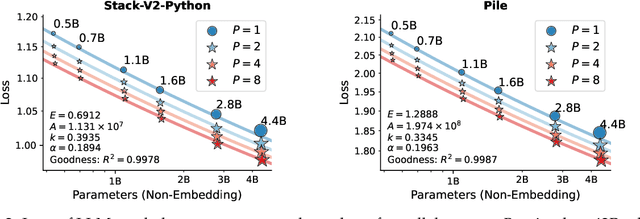

It is commonly believed that scaling language models should commit a significant space or time cost, by increasing the parameters (parameter scaling) or output tokens (inference-time scaling). We introduce the third and more inference-efficient scaling paradigm: increasing the model's parallel computation during both training and inference time. We apply $P$ diverse and learnable transformations to the input, execute forward passes of the model in parallel, and dynamically aggregate the $P$ outputs. This method, namely parallel scaling (ParScale), scales parallel computation by reusing existing parameters and can be applied to any model structure, optimization procedure, data, or task. We theoretically propose a new scaling law and validate it through large-scale pre-training, which shows that a model with $P$ parallel streams is similar to scaling the parameters by $O(\log P)$ while showing superior inference efficiency. For example, ParScale can use up to 22$\times$ less memory increase and 6$\times$ less latency increase compared to parameter scaling that achieves the same performance improvement. It can also recycle an off-the-shelf pre-trained model into a parallelly scaled one by post-training on a small amount of tokens, further reducing the training budget. The new scaling law we discovered potentially facilitates the deployment of more powerful models in low-resource scenarios, and provides an alternative perspective for the role of computation in machine learning.