 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-Coder-Next Technical Report
Feb 28, 2026We present Qwen3-Coder-Next, an open-weight language model specialized for coding agents. Qwen3-Coder-Next is an 80-billion-parameter model that activates only 3 billion parameters during inference, enabling strong coding capability with efficient inference. In this work, we explore how far strong training recipes can push the capability limits of models with small parameter footprints. To achieve this, we perform agentic training through large-scale synthesis of verifiable coding tasks paired with executable environments, allowing learning directly from environment feedback via mid-training and reinforcement learning. Across agent-centric benchmarks including SWE-Bench and Terminal-Bench, Qwen3-Coder-Next achieves competitive performance relative to its active parameter count. We release both base and instruction-tuned open-weight versions to support research and real-world coding agent development.
SWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
Aug 07, 2025Reinforcement learning (RL) has significantly advanced code generation for large language models (LLMs). However, current paradigms rely on outcome-based rewards from test cases, neglecting the quality of the intermediate reasoning process. While supervising the reasoning process directly is a promising direction, it is highly susceptible to reward hacking, where the policy model learns to exploit the reasoning reward signal without improving final outcomes. To address this, we introduce a unified framework that can effectively incorporate the quality of the reasoning process during RL. First, to enable reasoning evaluation, we develop LCB-RB, a benchmark comprising preference pairs of superior and inferior reasoning processes. Second, to accurately score reasoning quality, we introduce an Optimized-Degraded based (OD-based) method for reward model training. This method generates high-quality preference pairs by systematically optimizing and degrading initial reasoning paths along curated dimensions of reasoning quality, such as factual accuracy, logical rigor, and coherence. A 7B parameter reward model with this method achieves state-of-the-art (SOTA) performance on LCB-RB and generalizes well to other benchmarks. Finally, we introduce Posterior-GRPO (P-GRPO), a novel RL method that conditions process-based rewards on task success. By selectively applying rewards to the reasoning processes of only successful outcomes, P-GRPO effectively mitigates reward hacking and aligns the model's internal reasoning with final code correctness. A 7B parameter model with P-GRPO achieves superior performance across diverse code generation tasks, outperforming outcome-only baselines by 4.5%, achieving comparable performance to GPT-4-Turbo. We further demonstrate the generalizability of our approach by extending it to mathematical tasks. Our models, dataset, and code are publicly available.
The Power of Architecture: Deep Dive into Transformer Architectures for Long-Term Time Series Forecasting
Jul 17, 2025



Transformer-based models have recently become dominant in Long-term Time Series Forecasting (LTSF), yet the variations in their architecture, such as encoder-only, encoder-decoder, and decoder-only designs, raise a crucial question: What Transformer architecture works best for LTSF tasks? However, existing models are often tightly coupled with various time-series-specific designs, making it difficult to isolate the impact of the architecture itself. To address this, we propose a novel taxonomy that disentangles these designs, enabling clearer and more unified comparisons of Transformer architectures. Our taxonomy considers key aspects such as attention mechanisms, forecasting aggregations, forecasting paradigms, and normalization layers. Through extensive experiments, we uncover several key insights: bi-directional attention with joint-attention is most effective; more complete forecasting aggregation improves performance; and the direct-mapping paradigm outperforms autoregressive approaches. Furthermore, our combined model, utilizing optimal architectural choices, consistently outperforms several existing models, reinforcing the validity of our conclusions. We hope these findings offer valuable guidance for future research on Transformer architectural designs in LTSF. Our code is available at https://github.com/HALF111/TSF_architecture.
SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
Jun 11, 2025We introduce **SWE-Flow**, a novel data synthesis framework grounded in Test-Driven Development (TDD). Unlike existing software engineering data that rely on human-submitted issues, **SWE-Flow** automatically infers incremental development steps directly from unit tests, which inherently encapsulate high-level requirements. The core of **SWE-Flow** is the construction of a Runtime Dependency Graph (RDG), which precisely captures function interactions, enabling the generation of a structured, step-by-step *development schedule*. At each step, **SWE-Flow** produces a partial codebase, the corresponding unit tests, and the necessary code modifications, resulting in fully verifiable TDD tasks. With this approach, we generated 16,061 training instances and 2,020 test instances from real-world GitHub projects, creating the **SWE-Flow-Eval** benchmark. Our experiments show that fine-tuning open model on this dataset significantly improves performance in TDD-based coding. To facilitate further research, we release all code, datasets, models, and Docker images at [Github](https://github.com/Hambaobao/SWE-Flow).
Parallel Scaling Law for Language Models
May 15, 2025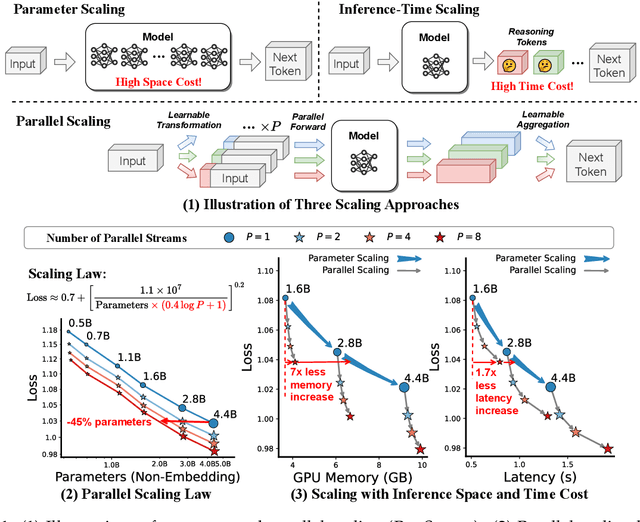

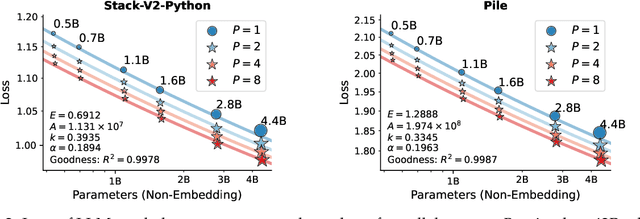

It is commonly believed that scaling language models should commit a significant space or time cost, by increasing the parameters (parameter scaling) or output tokens (inference-time scaling). We introduce the third and more inference-efficient scaling paradigm: increasing the model's parallel computation during both training and inference time. We apply $P$ diverse and learnable transformations to the input, execute forward passes of the model in parallel, and dynamically aggregate the $P$ outputs. This method, namely parallel scaling (ParScale), scales parallel computation by reusing existing parameters and can be applied to any model structure, optimization procedure, data, or task. We theoretically propose a new scaling law and validate it through large-scale pre-training, which shows that a model with $P$ parallel streams is similar to scaling the parameters by $O(\log P)$ while showing superior inference efficiency. For example, ParScale can use up to 22$\times$ less memory increase and 6$\times$ less latency increase compared to parameter scaling that achieves the same performance improvement. It can also recycle an off-the-shelf pre-trained model into a parallelly scaled one by post-training on a small amount of tokens, further reducing the training budget. The new scaling law we discovered potentially facilitates the deployment of more powerful models in low-resource scenarios, and provides an alternative perspective for the role of computation in machine learning.
Self-Explained Keywords Empower Large Language Models for Code Generation
Oct 21, 2024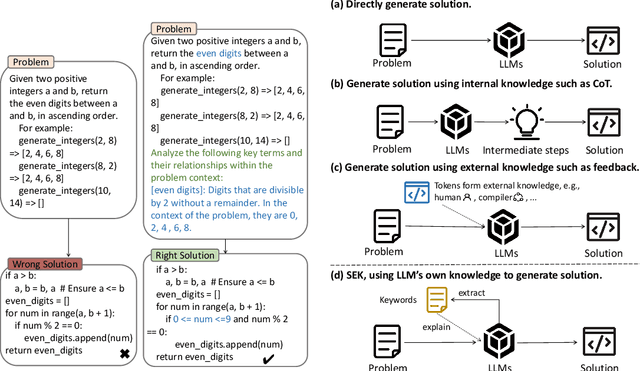
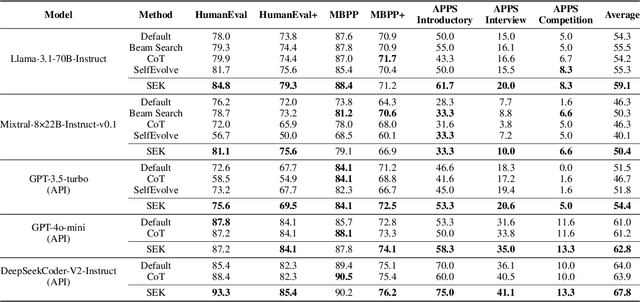

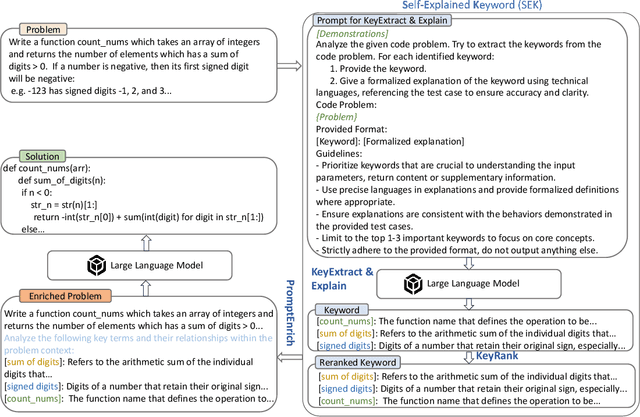
Large language models (LLMs) have achieved impressive performance in code generation. However, due to the long-tail distribution of LLMs' training data, low-frequency terms are typically underrepresented in the training process. Consequently, LLMs often misunderstand or overlook problem-specific, low-frequency keywords during code generation, compromising the accuracy of the generated code. To address this, we propose a novel technique named SEK(\textbf{S}elf-\textbf{E}xplained \textbf{K}eywords), which empowers an LLM for better code generation by extracting and explaining the key terms in the problem description with the LLM itself and ranking them based on frequency. Comprehensive experiments across three benchmarks, i.e., HumanEval(+), MBPP(+), and APPS, with five representative LLMs, show that SEK can significantly improve LLMs in code generation, yielding substantial and consistent gains. For instance, SEK improves the Pass@1 of DeepSeek-Coder-V2-Instruct from 85.4\% to 93.3\% on the Humaneval benchmark. Further analysis confirms that SEK enables the LLMs to shift their attention from low-frequency keywords to their corresponding high-frequency counterparts.
B4: Towards Optimal Assessment of Plausible Code Solutions with Plausible Tests
Sep 13, 2024



Selecting the best code solution from multiple generated ones is an essential task in code generation, which can be achieved by using some reliable validators (e.g., developer-written test cases) for assistance. Since reliable test cases are not always available and can be expensive to build in practice, researchers propose to automatically generate test cases to assess code solutions. However, when both code solutions and test cases are plausible and not reliable, selecting the best solution becomes challenging. Although some heuristic strategies have been proposed to tackle this problem, they lack a strong theoretical guarantee and it is still an open question whether an optimal selection strategy exists. Our work contributes in two ways. First, we show that within a Bayesian framework, the optimal selection strategy can be defined based on the posterior probability of the observed passing states between solutions and tests. The problem of identifying the best solution is then framed as an integer programming problem. Second, we propose an efficient approach for approximating this optimal (yet uncomputable) strategy, where the approximation error is bounded by the correctness of prior knowledge. We then incorporate effective prior knowledge to tailor code generation tasks. Both theoretical and empirical studies confirm that existing heuristics are limited in selecting the best solutions with plausible test cases. Our proposed approximated optimal strategy B4 significantly surpasses existing heuristics in selecting code solutions generated by large language models (LLMs) with LLM-generated tests, achieving a relative performance improvement by up to 50% over the strongest heuristic and 246% over the random selection in the most challenging scenarios. Our code is publicly available at https://github.com/ZJU-CTAG/B4.
VisionTS: Visual Masked Autoencoders Are Free-Lunch Zero-Shot Time Series Forecasters
Aug 30, 2024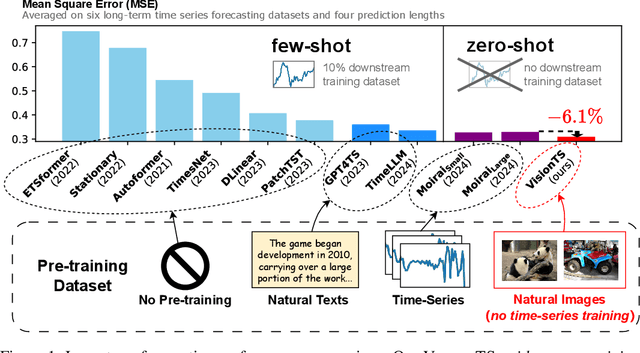
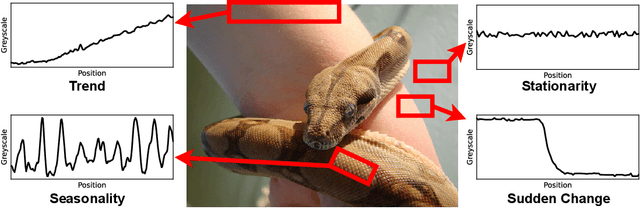
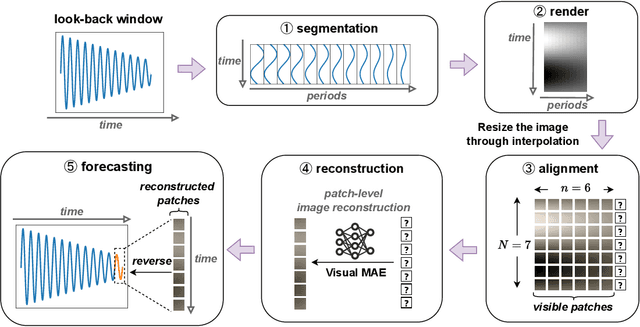
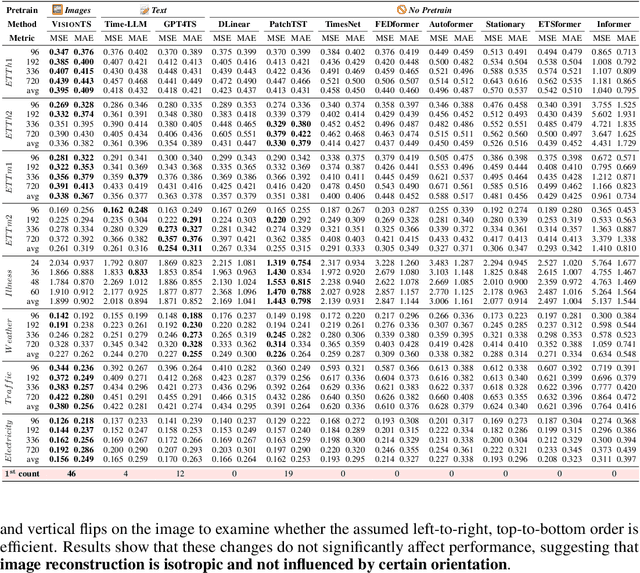
Foundation models have emerged as a promising approach in time series forecasting (TSF). Existing approaches either fine-tune large language models (LLMs) or build large-scale time-series datasets to develop TSF foundation models. However, these methods face challenges due to the severe cross-domain gap or in-domain heterogeneity. In this paper, we explore a new road to building a TSF foundation model from rich and high-quality natural images, based on the intrinsic similarities between images and time series. To bridge the gap between the two domains, we reformulate the TSF task as an image reconstruction task, which is further processed by a visual masked autoencoder (MAE) self-supervised pre-trained on the ImageNet dataset. Surprisingly, without further adaptation in the time-series domain, the proposed VisionTS could achieve superior zero-shot forecasting performance compared to existing TSF foundation models. With minimal fine-tuning, VisionTS could further improve the forecasting and achieve state-of-the-art performance in most cases. These findings suggest that visual models could be a free lunch for TSF and highlight the potential for future cross-domain research between computer vision and TSF. Our code is publicly available at https://github.com/Keytoyze/VisionTS.
JumpCoder: Go Beyond Autoregressive Coder via Online Modification
Jan 15, 2024



While existing code large language models (code LLMs) exhibit impressive capabilities in code generation, their autoregressive sequential generation inherently lacks reversibility. This limitation hinders them from timely correcting previous missing statements during coding as humans do, often leading to error propagation and suboptimal performance. We introduce JumpCoder, a novel modelagnostic framework that enables online modification and non-sequential generation to augment the code LLMs. The key idea behind JumpCoder is to insert new code into the currently generated code when necessary during generation, which is achieved through an auxiliary infilling model that works in tandem with the code LLM. Since identifying the best infill position beforehand is intractable, we adopt an infill-first, judge-later strategy, which experiments with filling at the $k$ most critical positions following the generation of each line, and uses an Abstract Syntax Tree (AST) parser alongside the Generation Model Scoring to effectively judge the validity of each potential infill. Extensive experiments using six state-of-the-art code LLMs across multiple benchmarks consistently indicate significant improvements over all baselines. Notably, JumpCoder assists code LLMs in achieving up to a 3.6% increase in Pass@1 for Python, 6.3% for Java, and 3.7% for C++ in the multilingual HumanEval benchmarks. Our code is public at https://github.com/Keytoyze/JumpCoder.