 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Explained Keywords Empower Large Language Models for Code Generation
Paper and Code
Oct 21, 2024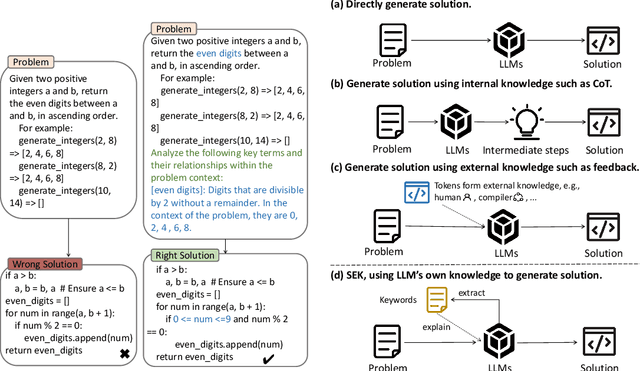
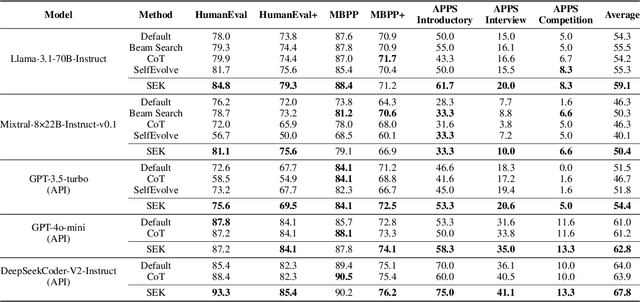

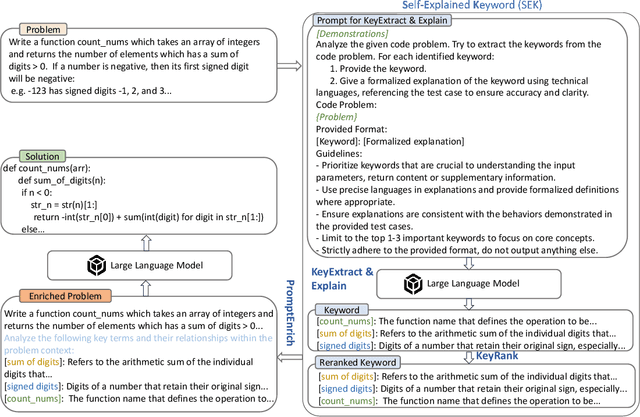
Large language models (LLMs) have achieved impressive performance in code generation. However, due to the long-tail distribution of LLMs' training data, low-frequency terms are typically underrepresented in the training process. Consequently, LLMs often misunderstand or overlook problem-specific, low-frequency keywords during code generation, compromising the accuracy of the generated code. To address this, we propose a novel technique named SEK(\textbf{S}elf-\textbf{E}xplained \textbf{K}eywords), which empowers an LLM for better code generation by extracting and explaining the key terms in the problem description with the LLM itself and ranking them based on frequency. Comprehensive experiments across three benchmarks, i.e., HumanEval(+), MBPP(+), and APPS, with five representative LLMs, show that SEK can significantly improve LLMs in code generation, yielding substantial and consistent gains. For instance, SEK improves the Pass@1 of DeepSeek-Coder-V2-Instruct from 85.4\% to 93.3\% on the Humaneval benchmark. Further analysis confirms that SEK enables the LLMs to shift their attention from low-frequency keywords to their corresponding high-frequency counterparts.