 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGuard: Secure Code Generation via Multi-Layer Semantic Aggregation
Apr 10, 2026Large Language Models (LLMs) for code generation can replicate insecure patterns from their training data. To mitigate this, a common strategy for security hardening is to fine-tune models using supervision derived from the final transformer layer. However, this design may suffer from a final-layer bottleneck: vulnerability-discriminative cues can be distributed across layers and become less detectable near the output representations optimized for next-token prediction. To diagnose this issue, we perform layer-wise linear probing. We observe that vulnerability-related signals are most detectable in a band of intermediate-to-upper layers yet attenuate toward the final layers. Motivated by this observation, we introduce DeepGuard, a framework that leverages distributed security-relevant cues by aggregating representations from multiple upper layers via an attention-based module. The aggregated signal powers a dedicated security analyzer within a multi-objective training objective that balances security enhancement and functional correctness, and further supports a lightweight inference-time steering strategy. Extensive experiments across five code LLMs demonstrate that DeepGuard improves the secure-and-correct generation rate by an average of 11.9% over strong baselines such as SVEN. It also preserves functional correctness while exhibiting generalization to held-out vulnerability types. Our code is public at https://github.com/unknownhl/DeepGuard.
Agentic Software Issue Resolution with Large Language Models: A Survey
Dec 24, 2025Software issue resolution aims to address real-world issues in software repositories (e.g., bug fixing and efficiency optimization) based on natural language descriptions provided by users, representing a key aspect of software maintenance. With the rapid development of large language models (LLMs) in reasoning and generative capabilities, LLM-based approaches have made significant progress in automated software issue resolution. However, real-world software issue resolution is inherently complex and requires long-horizon reasoning, iterative exploration, and feedback-driven decision making, which demand agentic capabilities beyond conventional single-step approaches. Recently, LLM-based agentic systems have become mainstream for software issue resolution. Advancements in agentic software issue resolution not only greatly enhance software maintenance efficiency and quality but also provide a realistic environment for validating agentic systems' reasoning, planning, and execution capabilities, bridging artificial intelligence and software engineering. This work presents a systematic survey of 126 recent studies at the forefront of LLM-based agentic software issue resolution research. It outlines the general workflow of the task and establishes a taxonomy across three dimensions: benchmarks, techniques, and empirical studies. Furthermore, it highlights how the emergence of agentic reinforcement learning has brought a paradigm shift in the design and training of agentic systems for software engineering. Finally, it summarizes key challenges and outlines promising directions for future research.
Intention Chain-of-Thought Prompting with Dynamic Routing for Code Generation
Dec 16, 2025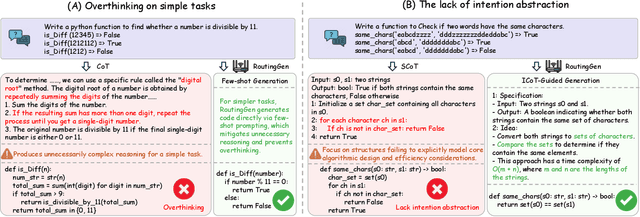
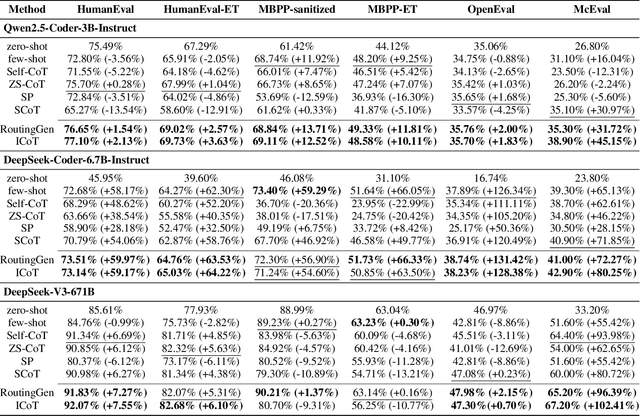
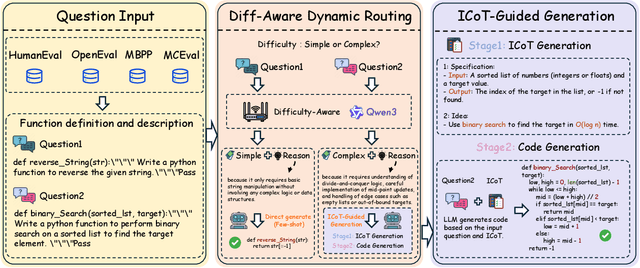
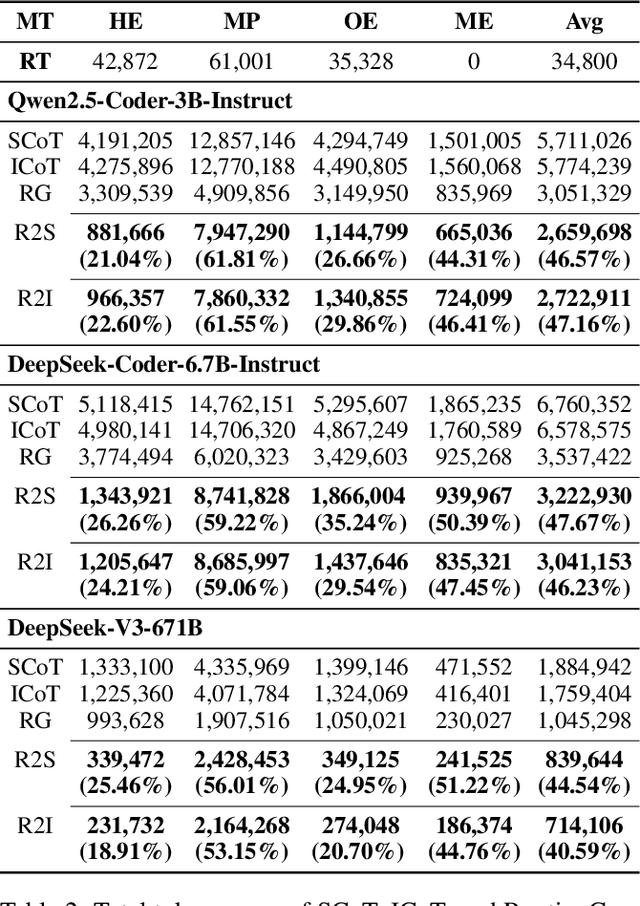
Large language models (LLMs) exhibit strong generative capabilities and have shown great potential in code generation. Existing chain-of-thought (CoT) prompting methods enhance model reasoning by eliciting intermediate steps, but suffer from two major limitations: First, their uniform application tends to induce overthinking on simple tasks. Second, they lack intention abstraction in code generation, such as explicitly modeling core algorithmic design and efficiency, leading models to focus on surface-level structures while neglecting the global problem objective. Inspired by the cognitive economy principle of engaging structured reasoning only when necessary to conserve cognitive resources, we propose RoutingGen, a novel difficulty-aware routing framework that dynamically adapts prompting strategies for code generation. For simple tasks, it adopts few-shot prompting; for more complex ones, it invokes a structured reasoning strategy, termed Intention Chain-of-Thought (ICoT), which we introduce to guide the model in capturing task intention, such as the core algorithmic logic and its time complexity. Experiments across three models and six standard code generation benchmarks show that RoutingGen achieves state-of-the-art performance in most settings, while reducing total token usage by 46.37% on average across settings. Furthermore, ICoT outperforms six existing prompting baselines on challenging benchmarks.
Posterior-GRPO: Rewarding Reasoning Processes in Code Generation
Aug 07, 2025Reinforcement learning (RL) has significantly advanced code generation for large language models (LLMs). However, current paradigms rely on outcome-based rewards from test cases, neglecting the quality of the intermediate reasoning process. While supervising the reasoning process directly is a promising direction, it is highly susceptible to reward hacking, where the policy model learns to exploit the reasoning reward signal without improving final outcomes. To address this, we introduce a unified framework that can effectively incorporate the quality of the reasoning process during RL. First, to enable reasoning evaluation, we develop LCB-RB, a benchmark comprising preference pairs of superior and inferior reasoning processes. Second, to accurately score reasoning quality, we introduce an Optimized-Degraded based (OD-based) method for reward model training. This method generates high-quality preference pairs by systematically optimizing and degrading initial reasoning paths along curated dimensions of reasoning quality, such as factual accuracy, logical rigor, and coherence. A 7B parameter reward model with this method achieves state-of-the-art (SOTA) performance on LCB-RB and generalizes well to other benchmarks. Finally, we introduce Posterior-GRPO (P-GRPO), a novel RL method that conditions process-based rewards on task success. By selectively applying rewards to the reasoning processes of only successful outcomes, P-GRPO effectively mitigates reward hacking and aligns the model's internal reasoning with final code correctness. A 7B parameter model with P-GRPO achieves superior performance across diverse code generation tasks, outperforming outcome-only baselines by 4.5%, achieving comparable performance to GPT-4-Turbo. We further demonstrate the generalizability of our approach by extending it to mathematical tasks. Our models, dataset, and code are publicly available.
Enhancing Project-Specific Code Completion by Inferring Internal API Information
Jul 28, 2025Project-specific code completion is a critical task that leverages context from a project to generate accurate code. State-of-the-art methods use retrieval-augmented generation (RAG) with large language models (LLMs) and project information for code completion. However, they often struggle to incorporate internal API information, which is crucial for accuracy, especially when APIs are not explicitly imported in the file. To address this, we propose a method to infer internal API information without relying on imports. Our method extends the representation of APIs by constructing usage examples and semantic descriptions, building a knowledge base for LLMs to generate relevant completions. We also introduce ProjBench, a benchmark that avoids leaked imports and consists of large-scale real-world projects. Experiments on ProjBench and CrossCodeEval show that our approach significantly outperforms existing methods, improving code exact match by 22.72% and identifier exact match by 18.31%. Additionally, integrating our method with existing baselines boosts code match by 47.80% and identifier match by 35.55%.
Parallel Scaling Law for Language Models
May 15, 2025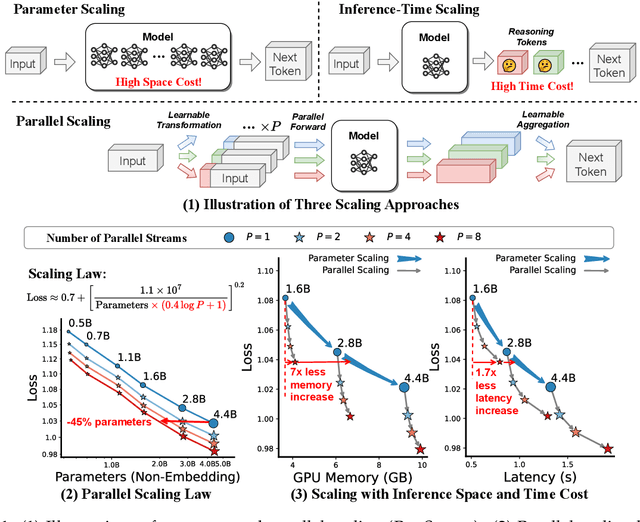

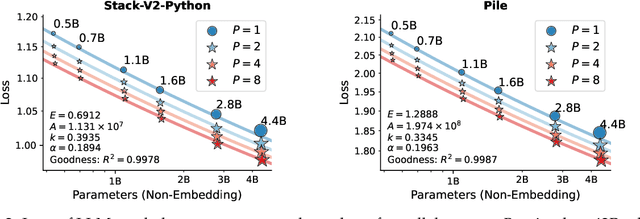

It is commonly believed that scaling language models should commit a significant space or time cost, by increasing the parameters (parameter scaling) or output tokens (inference-time scaling). We introduce the third and more inference-efficient scaling paradigm: increasing the model's parallel computation during both training and inference time. We apply $P$ diverse and learnable transformations to the input, execute forward passes of the model in parallel, and dynamically aggregate the $P$ outputs. This method, namely parallel scaling (ParScale), scales parallel computation by reusing existing parameters and can be applied to any model structure, optimization procedure, data, or task. We theoretically propose a new scaling law and validate it through large-scale pre-training, which shows that a model with $P$ parallel streams is similar to scaling the parameters by $O(\log P)$ while showing superior inference efficiency. For example, ParScale can use up to 22$\times$ less memory increase and 6$\times$ less latency increase compared to parameter scaling that achieves the same performance improvement. It can also recycle an off-the-shelf pre-trained model into a parallelly scaled one by post-training on a small amount of tokens, further reducing the training budget. The new scaling law we discovered potentially facilitates the deployment of more powerful models in low-resource scenarios, and provides an alternative perspective for the role of computation in machine learning.
Zero-Shot Cross-Domain Code Search without Fine-Tuning
Apr 10, 2025



Code search aims to retrieve semantically relevant code snippets for natural language queries. While pre-trained language models (PLMs) have shown remarkable performance in this task, they struggle in cross-domain scenarios, often requiring costly fine-tuning or facing performance drops in zero-shot settings. RAPID, which generates synthetic data for model fine-tuning, is currently the only effective method for zero-shot cross-domain code search. Despite its effectiveness, RAPID demands substantial computational resources for fine-tuning and needs to maintain specialized models for each domain, underscoring the need for a zero-shot, fine-tuning-free approach for cross-domain code search. The key to tackling zero-shot cross-domain code search lies in bridging the gaps among domains. In this work, we propose to break the query-code matching process of code search into two simpler tasks: query-comment matching and code-code matching. Our empirical study reveals the strong complementarity among the three matching schemas in zero-shot cross-domain settings, i.e., query-code, query-comment, and code-code matching. Based on the findings, we propose CodeBridge, a zero-shot, fine-tuning-free approach for cross-domain code search. Specifically, CodeBridge uses Large Language Models (LLMs) to generate comments and pseudo-code, then combines query-code, query-comment, and code-code matching via PLM-based similarity scoring and sampling-based fusion. Experimental results show that our approach outperforms the state-of-the-art PLM-based code search approaches, i.e., CoCoSoDa and UniXcoder, by an average of 21.4% and 24.9% in MRR, respectively, across three datasets. Our approach also yields results that are better than or comparable to those of the zero-shot cross-domain code search approach RAPID, which requires costly fine-tuning.
CoSIL: Software Issue Localization via LLM-Driven Code Repository Graph Searching
Mar 28, 2025



Large language models (LLMs) have significantly advanced autonomous software engineering, leading to a growing number of software engineering agents that assist developers in automatic program repair. Issue localization forms the basis for accurate patch generation. However, because of limitations caused by the context window length of LLMs, existing issue localization methods face challenges in balancing concise yet effective contexts and adequately comprehensive search spaces. In this paper, we introduce CoSIL, an LLM driven, simple yet powerful function level issue localization method without training or indexing. CoSIL reduces the search space through module call graphs, iteratively searches the function call graph to obtain relevant contexts, and uses context pruning to control the search direction and manage contexts effectively. Importantly, the call graph is dynamically constructed by the LLM during search, eliminating the need for pre-parsing. Experiment results demonstrate that CoSIL achieves a Top-1 localization success rate of 43 percent and 44.6 percent on SWE bench Lite and SWE bench Verified, respectively, using Qwen2.5 Coder 32B, outperforming existing methods by 8.6 to 98.2 percent. When CoSIL is applied to guide the patch generation stage, the resolved rate further improves by 9.3 to 31.5 percent.
KSHSeek: Data-Driven Approaches to Mitigating and Detecting Knowledge-Shortcut Hallucinations in Generative Models
Mar 25, 2025The emergence of large language models (LLMs) has significantly advanced the development of natural language processing (NLP), especially in text generation tasks like question answering. However, model hallucinations remain a major challenge in natural language generation (NLG) tasks due to their complex causes. We systematically expand on the causes of factual hallucinations from the perspective of knowledge shortcuts, analyzing hallucinations arising from correct and defect-free data and demonstrating that knowledge-shortcut hallucinations are prevalent in generative models. To mitigate this issue, we propose a high similarity pruning algorithm at the data preprocessing level to reduce spurious correlations in the data. Additionally, we design a specific detection method for knowledge-shortcut hallucinations to evaluate the effectiveness of our mitigation strategy. Experimental results show that our approach effectively reduces knowledge-shortcut hallucinations, particularly in fine-tuning tasks, without negatively impacting model performance in question answering. This work introduces a new paradigm for mitigating specific hallucination issues in generative models, enhancing their robustness and reliability in real-world applications.
Self-Explained Keywords Empower Large Language Models for Code Generation
Oct 21, 2024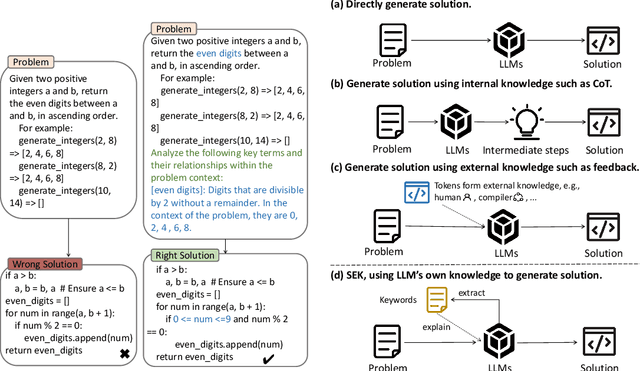
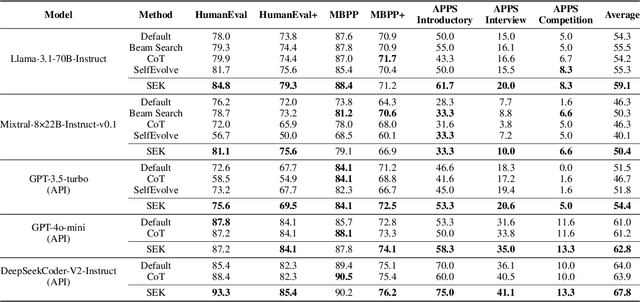

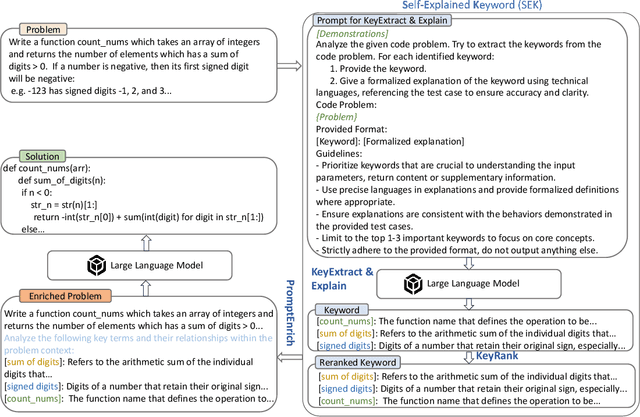
Large language models (LLMs) have achieved impressive performance in code generation. However, due to the long-tail distribution of LLMs' training data, low-frequency terms are typically underrepresented in the training process. Consequently, LLMs often misunderstand or overlook problem-specific, low-frequency keywords during code generation, compromising the accuracy of the generated code. To address this, we propose a novel technique named SEK(\textbf{S}elf-\textbf{E}xplained \textbf{K}eywords), which empowers an LLM for better code generation by extracting and explaining the key terms in the problem description with the LLM itself and ranking them based on frequency. Comprehensive experiments across three benchmarks, i.e., HumanEval(+), MBPP(+), and APPS, with five representative LLMs, show that SEK can significantly improve LLMs in code generation, yielding substantial and consistent gains. For instance, SEK improves the Pass@1 of DeepSeek-Coder-V2-Instruct from 85.4\% to 93.3\% on the Humaneval benchmark. Further analysis confirms that SEK enables the LLMs to shift their attention from low-frequency keywords to their corresponding high-frequency counterparts.