 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEviRank: Evidence-Based Confidence Estimation for LLM-Based Ranking
Jun 03, 2026Large Language Models show promise for recommendation, but they raise reliability concerns due to limited domain coverage and inherent stochasticity. Existing uncertainty quantification methods persist two fundamental challenges: (1) the global confidence score designed for question answering fails to reveal which positions are unreliable in ranking list; (2) fine-grained confidence extracted from model internals exhibits uniformly low values across all positions, making it impossible to filter unreliable predictions. To tackle the challenges, we propose an evidence-based confidence estimation for LLM-based ranking (EviRank). We extract three complementary evidences from a single forward pass and aggregate them via reliable opinion aggregation. Furthermore, we recognize that ranking positions are inherently unequal, and introduce a position-aware calibration. Lastly, the calibrated confidence guides ranking optimization. Experiments on three datasets demonstrate that our method achieves state-of-the-art performance on both recommendation and uncertainty quantification.
DeepGuard: Secure Code Generation via Multi-Layer Semantic Aggregation
Apr 10, 2026Large Language Models (LLMs) for code generation can replicate insecure patterns from their training data. To mitigate this, a common strategy for security hardening is to fine-tune models using supervision derived from the final transformer layer. However, this design may suffer from a final-layer bottleneck: vulnerability-discriminative cues can be distributed across layers and become less detectable near the output representations optimized for next-token prediction. To diagnose this issue, we perform layer-wise linear probing. We observe that vulnerability-related signals are most detectable in a band of intermediate-to-upper layers yet attenuate toward the final layers. Motivated by this observation, we introduce DeepGuard, a framework that leverages distributed security-relevant cues by aggregating representations from multiple upper layers via an attention-based module. The aggregated signal powers a dedicated security analyzer within a multi-objective training objective that balances security enhancement and functional correctness, and further supports a lightweight inference-time steering strategy. Extensive experiments across five code LLMs demonstrate that DeepGuard improves the secure-and-correct generation rate by an average of 11.9% over strong baselines such as SVEN. It also preserves functional correctness while exhibiting generalization to held-out vulnerability types. Our code is public at https://github.com/unknownhl/DeepGuard.
DynaFix: Iterative Automated Program Repair Driven by Execution-Level Dynamic Information
Dec 31, 2025Automated Program Repair (APR) aims to automatically generate correct patches for buggy programs. Recent approaches leveraging large language models (LLMs) have shown promise but face limitations. Most rely solely on static analysis, ignoring runtime behaviors. Some attempt to incorporate dynamic signals, but these are often restricted to training or fine-tuning, or injected only once into the repair prompt, without iterative use. This fails to fully capture program execution. Current iterative repair frameworks typically rely on coarse-grained feedback, such as pass/fail results or exception types, and do not leverage fine-grained execution-level information effectively. As a result, models struggle to simulate human stepwise debugging, limiting their effectiveness in multi-step reasoning and complex bug repair. To address these challenges, we propose DynaFix, an execution-level dynamic information-driven APR method that iteratively leverages runtime information to refine the repair process. In each repair round, DynaFix captures execution-level dynamic information such as variable states, control-flow paths, and call stacks, transforming them into structured prompts to guide LLMs in generating candidate patches. If a patch fails validation, DynaFix re-executes the modified program to collect new execution information for the next attempt. This iterative loop incrementally improves patches based on updated feedback, similar to the stepwise debugging practices of human developers. We evaluate DynaFix on the Defects4J v1.2 and v2.0 benchmarks. DynaFix repairs 186 single-function bugs, a 10% improvement over state-of-the-art baselines, including 38 bugs previously unrepaired. It achieves correct patches within at most 35 attempts, reducing the patch search space by 70% compared with existing methods, thereby demonstrating both effectiveness and efficiency in repairing complex bugs.
Intention Chain-of-Thought Prompting with Dynamic Routing for Code Generation
Dec 16, 2025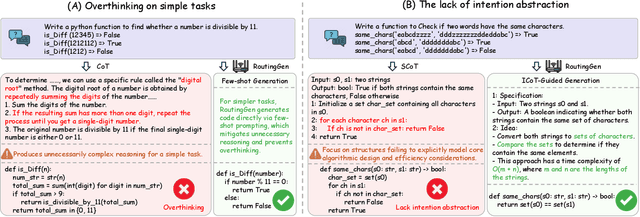
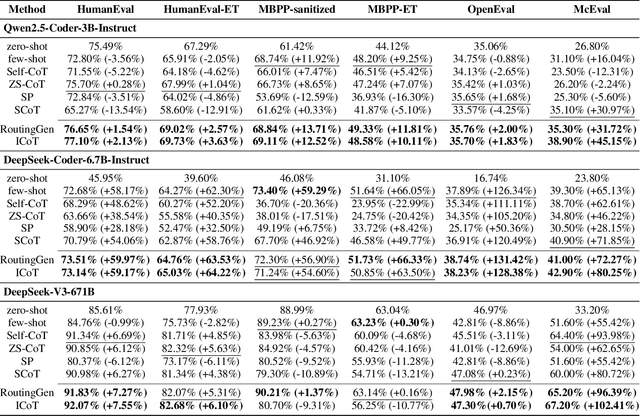
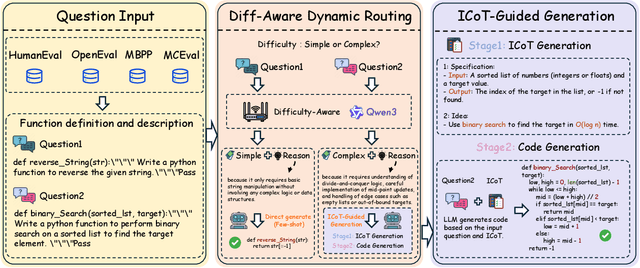
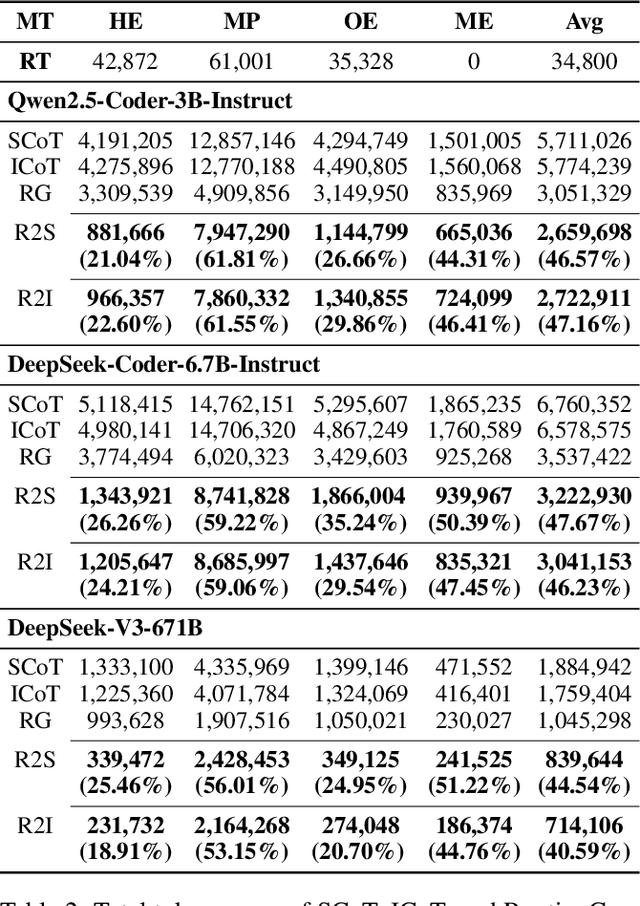
Large language models (LLMs) exhibit strong generative capabilities and have shown great potential in code generation. Existing chain-of-thought (CoT) prompting methods enhance model reasoning by eliciting intermediate steps, but suffer from two major limitations: First, their uniform application tends to induce overthinking on simple tasks. Second, they lack intention abstraction in code generation, such as explicitly modeling core algorithmic design and efficiency, leading models to focus on surface-level structures while neglecting the global problem objective. Inspired by the cognitive economy principle of engaging structured reasoning only when necessary to conserve cognitive resources, we propose RoutingGen, a novel difficulty-aware routing framework that dynamically adapts prompting strategies for code generation. For simple tasks, it adopts few-shot prompting; for more complex ones, it invokes a structured reasoning strategy, termed Intention Chain-of-Thought (ICoT), which we introduce to guide the model in capturing task intention, such as the core algorithmic logic and its time complexity. Experiments across three models and six standard code generation benchmarks show that RoutingGen achieves state-of-the-art performance in most settings, while reducing total token usage by 46.37% on average across settings. Furthermore, ICoT outperforms six existing prompting baselines on challenging benchmarks.
Conf-GNNRec: Quantifying and Calibrating the Prediction Confidence for GNN-based Recommendation Methods
May 22, 2025Recommender systems based on graph neural networks perform well in tasks such as rating and ranking. However, in real-world recommendation scenarios, noise such as user misuse and malicious advertisement gradually accumulates through the message propagation mechanism. Even if existing studies mitigate their effects by reducing the noise propagation weights, the severe sparsity of the recommender system still leads to the low-weighted noisy neighbors being mistaken as meaningful information, and the prediction result obtained based on the polluted nodes is not entirely trustworthy. Therefore, it is crucial to measure the confidence of the prediction results in this highly noisy framework. Furthermore, our evaluation of the existing representative GNN-based recommendation shows that it suffers from overconfidence. Based on the above considerations, we propose a new method to quantify and calibrate the prediction confidence of GNN-based recommendations (Conf-GNNRec). Specifically, we propose a rating calibration method that dynamically adjusts excessive ratings to mitigate overconfidence based on user personalization. We also design a confidence loss function to reduce the overconfidence of negative samples and effectively improve recommendation performance. Experiments on public datasets demonstrate the validity of Conf-GNNRec in prediction confidence and recommendation performance.
QoSBERT: An Uncertainty-Aware Approach based on Pre-trained Language Models for Service Quality Prediction
May 09, 2025Accurate prediction of Quality of Service (QoS) metrics is fundamental for selecting and managing cloud based services. Traditional QoS models rely on manual feature engineering and yield only point estimates, offering no insight into the confidence of their predictions. In this paper, we propose QoSBERT, the first framework that reformulates QoS prediction as a semantic regression task based on pre trained language models. Unlike previous approaches relying on sparse numerical features, QoSBERT automatically encodes user service metadata into natural language descriptions, enabling deep semantic understanding. Furthermore, we integrate a Monte Carlo Dropout based uncertainty estimation module, allowing for trustworthy and risk-aware service quality prediction, which is crucial yet underexplored in existing QoS models. QoSBERT applies attentive pooling over contextualized embeddings and a lightweight multilayer perceptron regressor, fine tuned jointly to minimize absolute error. We further exploit the resulting uncertainty estimates to select high quality training samples, improving robustness in low resource settings. On standard QoS benchmark datasets, QoSBERT achieves an average reduction of 11.7% in MAE and 6.7% in RMSE for response time prediction, and 6.9% in MAE for throughput prediction compared to the strongest baselines, while providing well calibrated confidence intervals for robust and trustworthy service quality estimation. Our approach not only advances the accuracy of service quality prediction but also delivers reliable uncertainty quantification, paving the way for more trustworthy, data driven service selection and optimization.
CoSIL: Software Issue Localization via LLM-Driven Code Repository Graph Searching
Mar 28, 2025



Large language models (LLMs) have significantly advanced autonomous software engineering, leading to a growing number of software engineering agents that assist developers in automatic program repair. Issue localization forms the basis for accurate patch generation. However, because of limitations caused by the context window length of LLMs, existing issue localization methods face challenges in balancing concise yet effective contexts and adequately comprehensive search spaces. In this paper, we introduce CoSIL, an LLM driven, simple yet powerful function level issue localization method without training or indexing. CoSIL reduces the search space through module call graphs, iteratively searches the function call graph to obtain relevant contexts, and uses context pruning to control the search direction and manage contexts effectively. Importantly, the call graph is dynamically constructed by the LLM during search, eliminating the need for pre-parsing. Experiment results demonstrate that CoSIL achieves a Top-1 localization success rate of 43 percent and 44.6 percent on SWE bench Lite and SWE bench Verified, respectively, using Qwen2.5 Coder 32B, outperforming existing methods by 8.6 to 98.2 percent. When CoSIL is applied to guide the patch generation stage, the resolved rate further improves by 9.3 to 31.5 percent.
TruthSR: Trustworthy Sequential Recommender Systems via User-generated Multimodal Content
Apr 26, 2024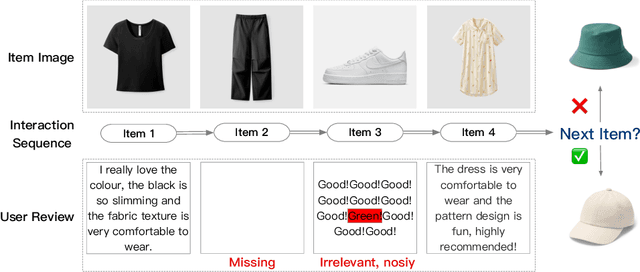
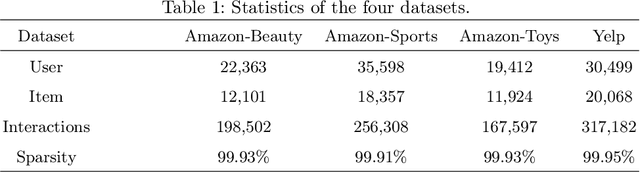
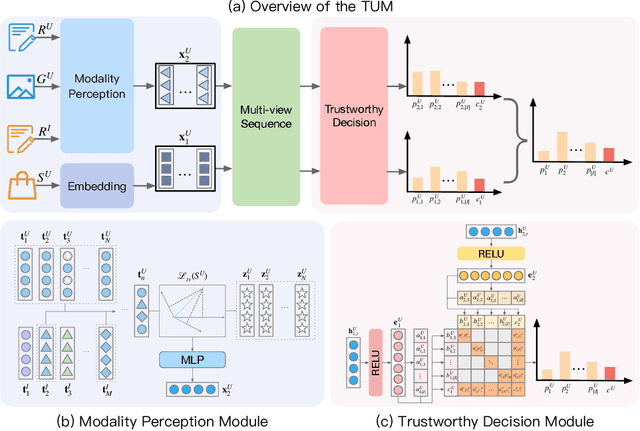
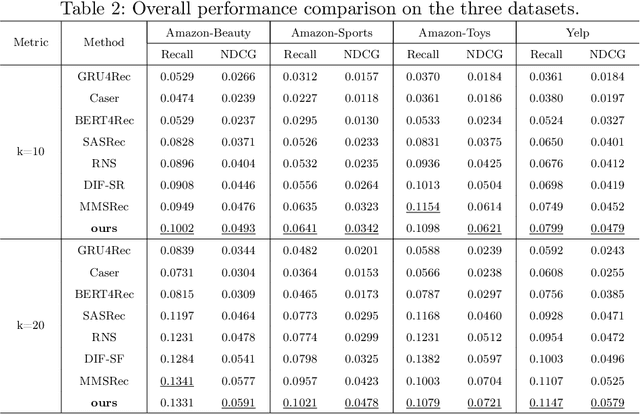
Sequential recommender systems explore users' preferences and behavioral patterns from their historically generated data. Recently, researchers aim to improve sequential recommendation by utilizing massive user-generated multi-modal content, such as reviews, images, etc. This content often contains inevitable noise. Some studies attempt to reduce noise interference by suppressing cross-modal inconsistent information. However, they could potentially constrain the capturing of personalized user preferences. In addition, it is almost impossible to entirely eliminate noise in diverse user-generated multi-modal content. To solve these problems, we propose a trustworthy sequential recommendation method via noisy user-generated multi-modal content. Specifically, we explicitly capture the consistency and complementarity of user-generated multi-modal content to mitigate noise interference. We also achieve the modeling of the user's multi-modal sequential preferences. In addition, we design a trustworthy decision mechanism that integrates subjective user perspective and objective item perspective to dynamically evaluate the uncertainty of prediction results. Experimental evaluation on four widely-used datasets demonstrates the superior performance of our model compared to state-of-the-art methods. The code is released at https://github.com/FairyMeng/TrustSR.
A Dual Latent State Learning Approach: Exploiting Regional Network Similarities for QoS Prediction
Oct 07, 2023



Individual objects, whether users or services, within a specific region often exhibit similar network states due to their shared origin from the same city or autonomous system (AS). Despite this regional network similarity, many existing techniques overlook its potential, resulting in subpar performance arising from challenges such as data sparsity and label imbalance. In this paper, we introduce the regional-based dual latent state learning network(R2SL), a novel deep learning framework designed to overcome the pitfalls of traditional individual object-based prediction techniques in Quality of Service (QoS) prediction. Unlike its predecessors, R2SL captures the nuances of regional network behavior by deriving two distinct regional network latent states: the city-network latent state and the AS-network latent state. These states are constructed utilizing aggregated data from common regions rather than individual object data. Furthermore, R2SL adopts an enhanced Huber loss function that adjusts its linear loss component, providing a remedy for prevalent label imbalance issues. To cap off the prediction process, a multi-scale perception network is leveraged to interpret the integrated feature map, a fusion of regional network latent features and other pertinent information, ultimately accomplishing the QoS prediction. Through rigorous testing on real-world QoS datasets, R2SL demonstrates superior performance compared to prevailing state-of-the-art methods. Our R2SL approach ushers in an innovative avenue for precise QoS predictions by fully harnessing the regional network similarities inherent in objects.
Probabilistic Deep Supervision Network: A Noise-Resilient Approach for QoS Prediction
Aug 03, 2023



Quality of Service (QoS) prediction is an essential task in recommendation systems, where accurately predicting unknown QoS values can improve user satisfaction. However, existing QoS prediction techniques may perform poorly in the presence of noise data, such as fake location information or virtual gateways. In this paper, we propose the Probabilistic Deep Supervision Network (PDS-Net), a novel framework for QoS prediction that addresses this issue. PDS-Net utilizes a Gaussian-based probabilistic space to supervise intermediate layers and learns probability spaces for both known features and true labels. Moreover, PDS-Net employs a condition-based multitasking loss function to identify objects with noise data and applies supervision directly to deep features sampled from the probability space by optimizing the Kullback-Leibler distance between the probability space of these objects and the real-label probability space. Thus, PDS-Net effectively reduces errors resulting from the propagation of corrupted data, leading to more accurate QoS predictions. Experimental evaluations on two real-world QoS datasets demonstrate that the proposed PDS-Net outperforms state-of-the-art baselines, validating the effectiveness of our approach.