 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Medical Multimodal Diagnostic Framework Integrating Vision-Language Models and Logic Tree Reasoning
Dec 25, 2025With the rapid growth of large language models (LLMs) and vision-language models (VLMs) in medicine, simply integrating clinical text and medical imaging does not guarantee reliable reasoning. Existing multimodal models often produce hallucinations or inconsistent chains of thought, limiting clinical trust. We propose a diagnostic framework built upon LLaVA that combines vision-language alignment with logic-regularized reasoning. The system includes an input encoder for text and images, a projection module for cross-modal alignment, a reasoning controller that decomposes diagnostic tasks into steps, and a logic tree generator that assembles stepwise premises into verifiable conclusions. Evaluations on MedXpertQA and other benchmarks show that our method improves diagnostic accuracy and yields more interpretable reasoning traces on multimodal tasks, while remaining competitive on text-only settings. These results suggest a promising step toward trustworthy multimodal medical AI.
GroupRank: A Groupwise Reranking Paradigm Driven by Reinforcement Learning
Nov 10, 2025Large Language Models have shown strong potential as rerankers to enhance the overall performance of RAG systems. However, existing reranking paradigms are constrained by a core theoretical and practical dilemma: Pointwise methods, while simple and highly flexible, evaluate documents independently, making them prone to the Ranking Myopia Trap, overlooking the relative importance between documents. In contrast, Listwise methods can perceive the global ranking context, but suffer from inherent List Rigidity, leading to severe scalability and flexibility issues when handling large candidate sets. To address these challenges, we propose Groupwise, a novel reranking paradigm. In this approach, the query and a group of candidate documents are jointly fed into the model, which performs within-group comparisons to assign individual relevance scores to each document. This design retains the flexibility of Pointwise methods while enabling the comparative capability of Listwise methods. We further adopt GRPO for model training, equipped with a heterogeneous reward function that integrates ranking metrics with a distributional reward aimed at aligning score distributions across groups. To overcome the bottleneck caused by the scarcity of high quality labeled data, we further propose an innovative pipeline for synthesizing high quality retrieval and ranking data. The resulting data can be leveraged not only for training the reranker but also for training the retriever. Extensive experiments validate the effectiveness of our approach. On two reasoning intensive retrieval benchmarks, BRIGHT and R2MED.
Less is More: Denoising Knowledge Graphs For Retrieval Augmented Generation
Oct 16, 2025Retrieval-Augmented Generation (RAG) systems enable large language models (LLMs) instant access to relevant information for the generative process, demonstrating their superior performance in addressing common LLM challenges such as hallucination, factual inaccuracy, and the knowledge cutoff. Graph-based RAG further extends this paradigm by incorporating knowledge graphs (KGs) to leverage rich, structured connections for more precise and inferential responses. A critical challenge, however, is that most Graph-based RAG systems rely on LLMs for automated KG construction, often yielding noisy KGs with redundant entities and unreliable relationships. This noise degrades retrieval and generation performance while also increasing computational cost. Crucially, current research does not comprehensively address the denoising problem for LLM-generated KGs. In this paper, we introduce DEnoised knowledge Graphs for Retrieval Augmented Generation (DEG-RAG), a framework that addresses these challenges through: (1) entity resolution, which eliminates redundant entities, and (2) triple reflection, which removes erroneous relations. Together, these techniques yield more compact, higher-quality KGs that significantly outperform their unprocessed counterparts. Beyond the methods, we conduct a systematic evaluation of entity resolution for LLM-generated KGs, examining different blocking strategies, embedding choices, similarity metrics, and entity merging techniques. To the best of our knowledge, this is the first comprehensive exploration of entity resolution in LLM-generated KGs. Our experiments demonstrate that this straightforward approach not only drastically reduces graph size but also consistently improves question answering performance across diverse popular Graph-based RAG variants.
DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval
Aug 12, 2025Retrieval-augmented generation has achieved strong performance on knowledge-intensive tasks where query-document relevance can be identified through direct lexical or semantic matches. However, many real-world queries involve abstract reasoning, analogical thinking, or multi-step inference, which existing retrievers often struggle to capture. To address this challenge, we present \textbf{DIVER}, a retrieval pipeline tailored for reasoning-intensive information retrieval. DIVER consists of four components: document processing to improve input quality, LLM-driven query expansion via iterative document interaction, a reasoning-enhanced retriever fine-tuned on synthetic multi-domain data with hard negatives, and a pointwise reranker that combines LLM-assigned helpfulness scores with retrieval scores. On the BRIGHT benchmark, DIVER achieves state-of-the-art nDCG@10 scores of 41.6 and 28.9 on original queries, consistently outperforming competitive reasoning-aware models. These results demonstrate the effectiveness of reasoning-aware retrieval strategies in complex real-world tasks. Our code and retrieval model will be released soon.
Conversational Intent-Driven GraphRAG: Enhancing Multi-Turn Dialogue Systems through Adaptive Dual-Retrieval of Flow Patterns and Context Semantics
Jun 24, 2025We present CID-GraphRAG (Conversational Intent-Driven Graph Retrieval Augmented Generation), a novel framework that addresses the limitations of existing dialogue systems in maintaining both contextual coherence and goal-oriented progression in multi-turn customer service conversations. Unlike traditional RAG systems that rely solely on semantic similarity (Conversation RAG) or standard knowledge graphs (GraphRAG), CID-GraphRAG constructs dynamic intent transition graphs from goal achieved historical dialogues and implements a dual-retrieval mechanism that adaptively balances intent-based graph traversal with semantic search. This approach enables the system to simultaneously leverage both conversional intent flow patterns and contextual semantics, significantly improving retrieval quality and response quality. In extensive experiments on real-world customer service dialogues, we employ both automatic metrics and LLM-as-judge assessments, demonstrating that CID-GraphRAG significantly outperforms both semantic-based Conversation RAG and intent-based GraphRAG baselines across all evaluation criteria. Quantitatively, CID-GraphRAG demonstrates substantial improvements over Conversation RAG across automatic metrics, with relative gains of 11% in BLEU, 5% in ROUGE-L, 6% in METEOR, and most notably, a 58% improvement in response quality according to LLM-as-judge evaluations. These results demonstrate that the integration of intent transition structures with semantic retrieval creates a synergistic effect that neither approach achieves independently, establishing CID-GraphRAG as an effective framework for addressing the challenges of maintaining contextual coherence and goal-oriented progression in knowledge-intensive multi-turn dialogues.
POLYRAG: Integrating Polyviews into Retrieval-Augmented Generation for Medical Applications
Apr 21, 2025



Large language models (LLMs) have become a disruptive force in the industry, introducing unprecedented capabilities in natural language processing, logical reasoning and so on. However, the challenges of knowledge updates and hallucination issues have limited the application of LLMs in medical scenarios, where retrieval-augmented generation (RAG) can offer significant assistance. Nevertheless, existing retrieve-then-read approaches generally digest the retrieved documents, without considering the timeliness, authoritativeness and commonality of retrieval. We argue that these approaches can be suboptimal, especially in real-world applications where information from different sources might conflict with each other and even information from the same source in different time scale might be different, and totally relying on this would deteriorate the performance of RAG approaches. We propose PolyRAG that carefully incorporate judges from different perspectives and finally integrate the polyviews for retrieval augmented generation in medical applications. Due to the scarcity of real-world benchmarks for evaluation, to bridge the gap we propose PolyEVAL, a benchmark consists of queries and documents collected from real-world medical scenarios (including medical policy, hospital & doctor inquiry and healthcare) with multiple tagging (e.g., timeliness, authoritativeness) on them. Extensive experiments and analysis on PolyEVAL have demonstrated the superiority of PolyRAG.
Sparsity-Induced Global Matrix Autoregressive Model with Auxiliary Network Data
Mar 11, 2025Jointly modeling and forecasting economic and financial variables across a large set of countries has long been a significant challenge. Two primary approaches have been utilized to address this issue: the vector autoregressive model with exogenous variables (VARX) and the matrix autoregression (MAR). The VARX model captures domestic dependencies, but treats variables exogenous to represent global factors driven by international trade. In contrast, the MAR model simultaneously considers variables from multiple countries but ignores the trade network. In this paper, we propose an extension of the MAR model that achieves these two aims at once, i.e., studying both international dependencies and the impact of the trade network on the global economy. Additionally, we introduce a sparse component to the model to differentiate between systematic and idiosyncratic cross-predictability. To estimate the model parameters, we propose both a likelihood estimation method and a bias-corrected alternating minimization version. We provide theoretical and empirical analyses of the model's properties, alongside presenting intriguing economic insights derived from our findings.
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Jun 20, 2024

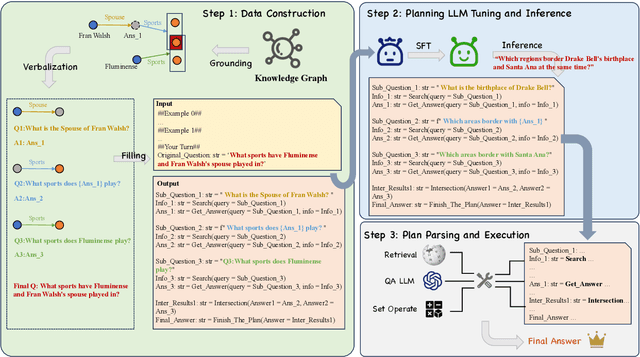
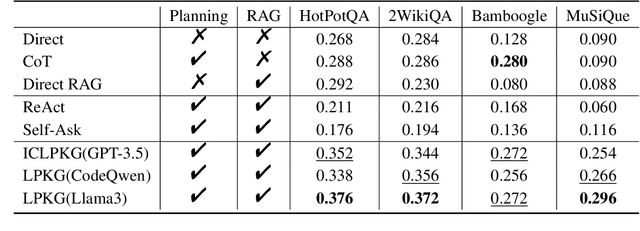
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
May 30, 2024



In recent years, large language models (LLMs) have made remarkable achievements in various domains. However, the untimeliness and cost of knowledge updates coupled with hallucination issues of LLMs have curtailed their applications in knowledge intensive tasks, where retrieval augmented generation (RAG) can be of help. Nevertheless, existing retrieval augmented models typically use similarity as a bridge between queries and documents and follow a retrieve then read procedure. In this work, we argue that similarity is not always the panacea and totally relying on similarity would sometimes degrade the performance of retrieval augmented generation. To this end, we propose MetRag, a Multi layEred Thoughts enhanced Retrieval Augmented Generation framework. To begin with, beyond existing similarity oriented thought, we embrace a small scale utility model that draws supervision from an LLM for utility oriented thought and further come up with a smarter model by comprehensively combining the similarity and utility oriented thoughts. Furthermore, given the fact that the retrieved document set tends to be huge and using them in isolation makes it difficult to capture the commonalities and characteristics among them, we propose to make an LLM as a task adaptive summarizer to endow retrieval augmented generation with compactness-oriented thought. Finally, with multi layered thoughts from the precedent stages, an LLM is called for knowledge augmented generation. Extensive experiments on knowledge-intensive tasks have demonstrated the superiority of MetRag.
Know Your Needs Better: Towards Structured Understanding of Marketer Demands with Analogical Reasoning Augmented LLMs
Jan 09, 2024In this paper, we explore a new way for user targeting, where non-expert marketers could select their target users solely given demands in natural language form. The key to this issue is how to transform natural languages into practical structured logical languages, i.e., the structured understanding of marketer demands. Considering the impressive natural language processing ability of large language models (LLMs), we try to leverage LLMs to solve this issue. Past research indicates that the reasoning ability of LLMs can be effectively enhanced through chain-of-thought (CoT) prompting. But existing methods still have some limitations: (1) Previous methods either use simple "Let's think step by step" spells or provide fixed examples in demonstrations without considering compatibility between prompts and questions, making LLMs ineffective in some complex reasoning tasks such as structured language transformation. (2) Previous methods are often implemented in closed-source models or excessively large models, which is not suitable in industrial practical scenarios. Based on these, we propose ARALLM (i.e., Analogical Reasoning Augmented Large Language Models) consisting of two modules: Analogical Reasoning based Prompting and Reasoning-Augmented Multi-Task Model Distillation.