 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandaPose: 3D Human Pose Lifting from a Single Image via Propagating 2D Pose Prior to 3D Anchor Space
Feb 01, 20263D human pose lifting from a single RGB image is a challenging task in 3D vision. Existing methods typically establish a direct joint-to-joint mapping from 2D to 3D poses based on 2D features. This formulation suffers from two fundamental limitations: inevitable error propagation from input predicted 2D pose to 3D predictions and inherent difficulties in handling self-occlusion cases. In this paper, we propose PandaPose, a 3D human pose lifting approach via propagating 2D pose prior to 3D anchor space as the unified intermediate representation. Specifically, our 3D anchor space comprises: (1) Joint-wise 3D anchors in the canonical coordinate system, providing accurate and robust priors to mitigate 2D pose estimation inaccuracies. (2) Depth-aware joint-wise feature lifting that hierarchically integrates depth information to resolve self-occlusion ambiguities. (3) The anchor-feature interaction decoder that incorporates 3D anchors with lifted features to generate unified anchor queries encapsulating joint-wise 3D anchor set, visual cues and geometric depth information. The anchor queries are further employed to facilitate anchor-to-joint ensemble prediction. Experiments on three well-established benchmarks (i.e., Human3.6M, MPI-INF-3DHP and 3DPW) demonstrate the superiority of our proposition. The substantial reduction in error by $14.7\%$ compared to SOTA methods on the challenging conditions of Human3.6M and qualitative comparisons further showcase the effectiveness and robustness of our approach.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
FACTS About Building Retrieval Augmented Generation-based Chatbots
Jul 10, 2024Enterprise chatbots, powered by generative AI, are emerging as key applications to enhance employee productivity. Retrieval Augmented Generation (RAG), Large Language Models (LLMs), and orchestration frameworks like Langchain and Llamaindex are crucial for building these chatbots. However, creating effective enterprise chatbots is challenging and requires meticulous RAG pipeline engineering. This includes fine-tuning embeddings and LLMs, extracting documents from vector databases, rephrasing queries, reranking results, designing prompts, honoring document access controls, providing concise responses, including references, safeguarding personal information, and building orchestration agents. We present a framework for building RAG-based chatbots based on our experience with three NVIDIA chatbots: for IT/HR benefits, financial earnings, and general content. Our contributions are three-fold: introducing the FACTS framework (Freshness, Architectures, Cost, Testing, Security), presenting fifteen RAG pipeline control points, and providing empirical results on accuracy-latency tradeoffs between large and small LLMs. To the best of our knowledge, this is the first paper of its kind that provides a holistic view of the factors as well as solutions for building secure enterprise-grade chatbots."
Temporal-Spatial Entropy Balancing for Causal Continuous Treatment-Effect Estimation
Dec 19, 2023In the field of intracity freight transportation, changes in order volume are significantly influenced by temporal and spatial factors. When building subsidy and pricing strategies, predicting the causal effects of these strategies on order volume is crucial. In the process of calculating causal effects, confounding variables can have an impact. Traditional methods to control confounding variables handle data from a holistic perspective, which cannot ensure the precision of causal effects in specific temporal and spatial dimensions. However, temporal and spatial dimensions are extremely critical in the logistics field, and this limitation may directly affect the precision of subsidy and pricing strategies. To address these issues, this study proposes a technique based on flexible temporal-spatial grid partitioning. Furthermore, based on the flexible grid partitioning technique, we further propose a continuous entropy balancing method in the temporal-spatial domain, which named TS-EBCT (Temporal-Spatial Entropy Balancing for Causal Continue Treatments). The method proposed in this paper has been tested on two simulation datasets and two real datasets, all of which have achieved excellent performance. In fact, after applying the TS-EBCT method to the intracity freight transportation field, the prediction accuracy of the causal effect has been significantly improved. It brings good business benefits to the company's subsidy and pricing strategies.
Pseudo Label-Guided Data Fusion and Output Consistency for Semi-Supervised Medical Image Segmentation
Nov 17, 2023



Supervised learning algorithms based on Convolutional Neural Networks have become the benchmark for medical image segmentation tasks, but their effectiveness heavily relies on a large amount of labeled data. However, annotating medical image datasets is a laborious and time-consuming process. Inspired by semi-supervised algorithms that use both labeled and unlabeled data for training, we propose the PLGDF framework, which builds upon the mean teacher network for segmenting medical images with less annotation. We propose a novel pseudo-label utilization scheme, which combines labeled and unlabeled data to augment the dataset effectively. Additionally, we enforce the consistency between different scales in the decoder module of the segmentation network and propose a loss function suitable for evaluating the consistency. Moreover, we incorporate a sharpening operation on the predicted results, further enhancing the accuracy of the segmentation. Extensive experiments on three publicly available datasets demonstrate that the PLGDF framework can largely improve performance by incorporating the unlabeled data. Meanwhile, our framework yields superior performance compared to six state-of-the-art semi-supervised learning methods. The codes of this study are available at https://github.com/ortonwang/PLGDF.
PCDAL: A Perturbation Consistency-Driven Active Learning Approach for Medical Image Segmentation and Classification
Jun 29, 2023



In recent years, deep learning has become a breakthrough technique in assisting medical image diagnosis. Supervised learning using convolutional neural networks (CNN) provides state-of-the-art performance and has served as a benchmark for various medical image segmentation and classification. However, supervised learning deeply relies on large-scale annotated data, which is expensive, time-consuming, and even impractical to acquire in medical imaging applications. Active Learning (AL) methods have been widely applied in natural image classification tasks to reduce annotation costs by selecting more valuable examples from the unlabeled data pool. However, their application in medical image segmentation tasks is limited, and there is currently no effective and universal AL-based method specifically designed for 3D medical image segmentation. To address this limitation, we propose an AL-based method that can be simultaneously applied to 2D medical image classification, segmentation, and 3D medical image segmentation tasks. We extensively validated our proposed active learning method on three publicly available and challenging medical image datasets, Kvasir Dataset, COVID-19 Infection Segmentation Dataset, and BraTS2019 Dataset. The experimental results demonstrate that our PCDAL can achieve significantly improved performance with fewer annotations in 2D classification and segmentation and 3D segmentation tasks. The codes of this study are available at https://github.com/ortonwang/PCDAL.
Contrastive Credibility Propagation for Reliable Semi-Supervised Learning
Nov 17, 2022Inferencing unlabeled data from labeled data is an error-prone process. Conventional neural network training is highly sensitive to supervision errors. These two realities make semi-supervised learning (SSL) troublesome. Often, SSL approaches fail to outperform their fully supervised baseline. Proposed is a novel framework for deep SSL, specifically pseudo-labeling, called contrastive credibility propagation (CCP). Through an iterative process of generating and refining soft pseudo-labels, CCP unifies a novel contrastive approach to generating pseudo-labels and a powerful technique to overcome instance-based label noise. The result is a semi-supervised classification framework explicitly designed to overcome inevitable pseudo-label errors in an attempt to reliably boost performance over a supervised baseline. Our empirical evaluation across five benchmark classification datasets suggests one must choose between reliability or effectiveness with prior approaches while CCP delivers both. We also demonstrate an unsupervised signal to subsample pseudo-labels to eliminate errors between iterations of CCP and after its conclusion.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
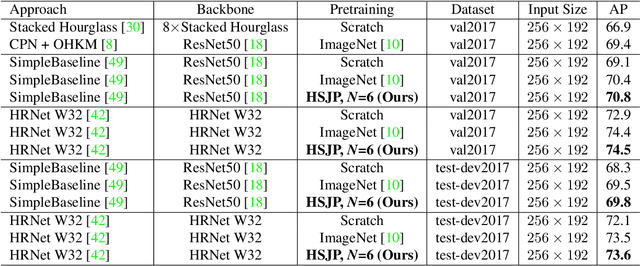

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.
Free-riders in Federated Learning: Attacks and Defenses
Nov 28, 2019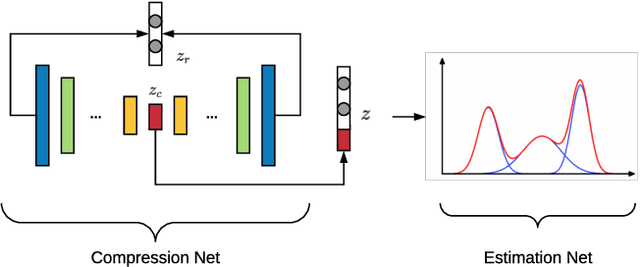
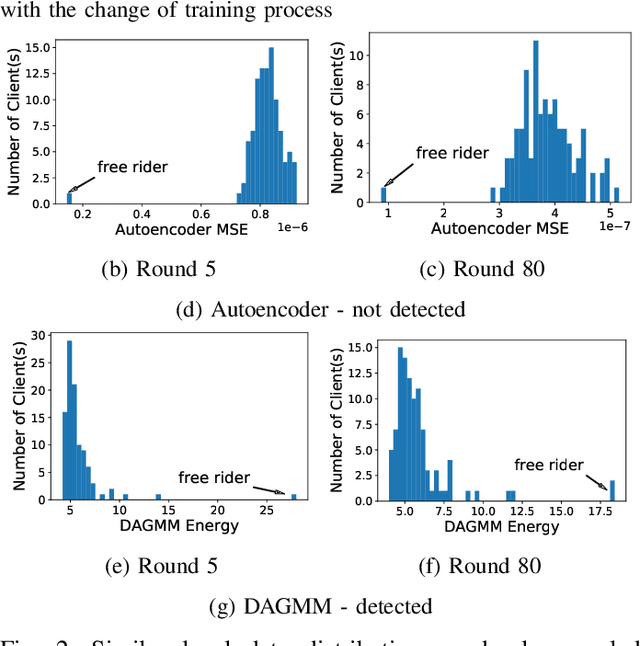
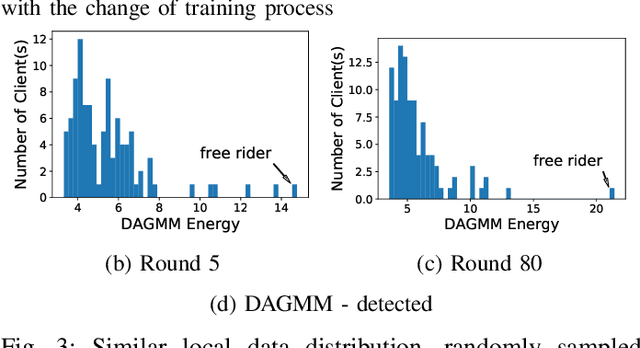
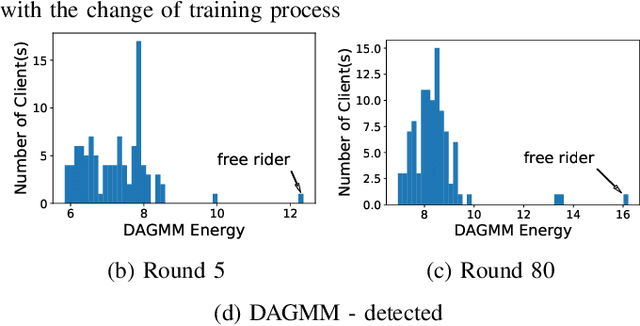
Federated learning is a recently proposed paradigm that enables multiple clients to collaboratively train a joint model. It allows clients to train models locally, and leverages the parameter server to generate a global model by aggregating the locally submitted gradient updates at each round. Although the incentive model for federated learning has not been fully developed, it is supposed that participants are able to get rewards or the privilege to use the final global model, as a compensation for taking efforts to train the model. Therefore, a client who does not have any local data has the incentive to construct local gradient updates in order to deceive for rewards. In this paper, we are the first to propose the notion of free rider attacks, to explore possible ways that an attacker may construct gradient updates, without any local training data. Furthermore, we explore possible defenses that could detect the proposed attacks, and propose a new high dimensional detection method called STD-DAGMM, which particularly works well for anomaly detection of model parameters. We extend the attacks and defenses to consider more free riders as well as differential privacy, which sheds light on and calls for future research in this field.