 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Tracking Using Frenet Coordinates with Deep Deterministic Policy Gradient
Nov 21, 2024This paper studies the application of the DDPG algorithm in trajectory-tracking tasks and proposes a trajectorytracking control method combined with Frenet coordinate system. By converting the vehicle's position and velocity information from the Cartesian coordinate system to Frenet coordinate system, this method can more accurately describe the vehicle's deviation and travel distance relative to the center line of the road. The DDPG algorithm adopts the Actor-Critic framework, uses deep neural networks for strategy and value evaluation, and combines the experience replay mechanism and target network to improve the algorithm's stability and data utilization efficiency. Experimental results show that the DDPG algorithm based on Frenet coordinate system performs well in trajectory-tracking tasks in complex environments, achieves high-precision and stable path tracking, and demonstrates its application potential in autonomous driving and intelligent transportation systems. Keywords- DDPG; path tracking; robot navigation
A Neural Matrix Decomposition Recommender System Model based on the Multimodal Large Language Model
Jul 12, 2024


Recommendation systems have become an important solution to information search problems. This article proposes a neural matrix factorization recommendation system model based on the multimodal large language model called BoNMF. This model combines BoBERTa's powerful capabilities in natural language processing, ViT in computer in vision, and neural matrix decomposition technology. By capturing the potential characteristics of users and items, and after interacting with a low-dimensional matrix composed of user and item IDs, the neural network outputs the results. recommend. Cold start and ablation experimental results show that the BoNMF model exhibits excellent performance on large public data sets and significantly improves the accuracy of recommendations.
Prioritized experience replay-based DDQN for Unmanned Vehicle Path Planning
Jun 25, 2024



Path planning module is a key module for autonomous vehicle navigation, which directly affects its operating efficiency and safety. In complex environments with many obstacles, traditional planning algorithms often cannot meet the needs of intelligence, which may lead to problems such as dead zones in unmanned vehicles. This paper proposes a path planning algorithm based on DDQN and combines it with the prioritized experience replay method to solve the problem that traditional path planning algorithms often fall into dead zones. A series of simulation experiment results prove that the path planning algorithm based on DDQN is significantly better than other methods in terms of speed and accuracy, especially the ability to break through dead zones in extreme environments. Research shows that the path planning algorithm based on DDQN performs well in terms of path quality and safety. These research results provide an important reference for the research on automatic navigation of autonomous vehicles.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
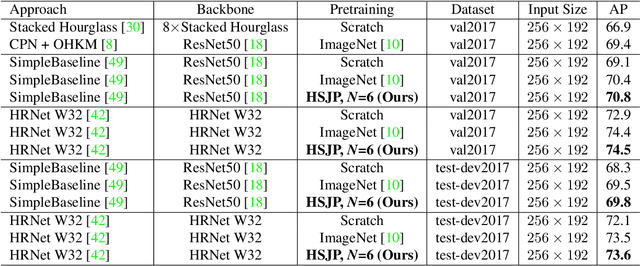

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.
DNANet: De-Normalized Attention Based Multi-Resolution Network for Human Pose Estimation
Oct 21, 2019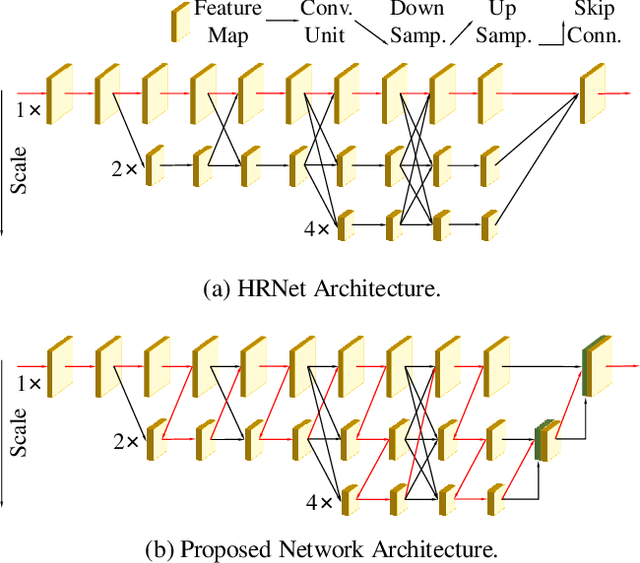
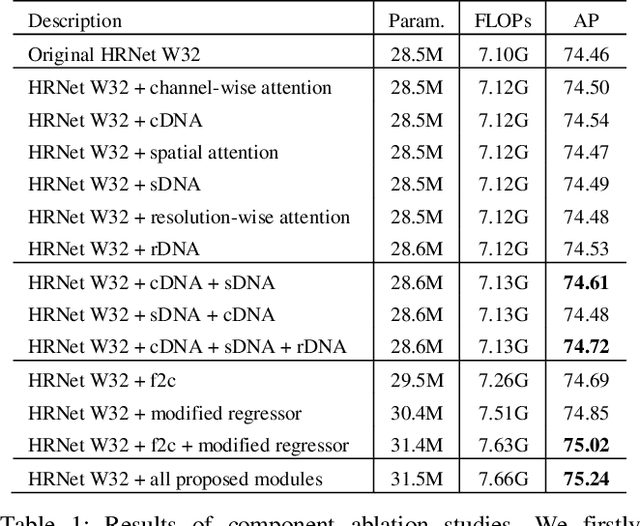
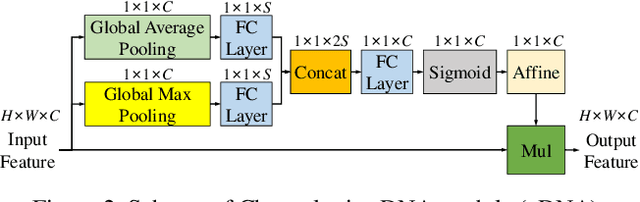
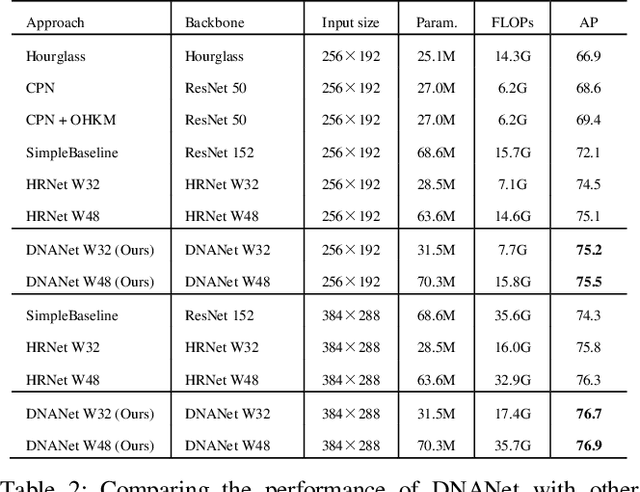
Recently, multi-resolution networks (such as Hourglass, CPN, HRNet, etc.) have achieved significant performance on the task of human pose estimation by combining features from various resolutions. In this paper, we propose a novel type of attention module, namely De-Normalized Attention (DNA) to deal with the feature attenuations of conventional attention modules. Our method extends the original HRNet with spatial, channel-wise and resolution-wise DNAs, which aims at evaluating the importance of features from different locations, channels and resolutions to enhance the network capability for feature representation. We also propose to add fine-to-coarse connections across high-to-low resolutions in-side each layer of HRNet to increase the maximum depth of network topology. In addition, we propose to modify the keypoint regressor at the end of HRNet for accurate keypoint heatmap prediction. The effectiveness of our proposed network is demonstrated on COCO keypoint detection dataset, achieving state-of-the-art performance at 77.6 AP score on COCO val2017 dataset without using extra keypoint training data. Our paper will be accompanied with publicly available codes at GitHub.