 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Discrete Marks and Continuous Dynamics: Dual-Path Cross-Interaction for Marked Temporal Point Processes
Mar 12, 2026Predicting irregularly spaced event sequences with discrete marks poses significant challenges due to the complex, asynchronous dependencies embedded within continuous-time data streams.Existing sequential approaches capture dependencies among event tokens but ignore the continuous evolution between events, while Neural Ordinary Differential Equation (Neural ODE) methods model smooth dynamics yet fail to account for how event types influence future timing.To overcome these limitations, we propose NEXTPP, a dual-channel framework that unifies discrete and continuous representations via Event-granular Neural Evolution with Cross-Interaction for Marked Temporal Point Processes. Specifically, NEXTPP encodes discrete event marks via a self-attention mechanism, simultaneously evolving a latent continuous-time state using a Neural ODE. These parallel streams are then fused through a crossattention module to enable explicit bidirectional interaction between continuous and discrete representations. The fused representations drive the conditional intensity function of the neural Hawkes process, while an iterative thinning sampler is employed to generate future events. Extensive evaluations on five real-world datasets demonstrate that NEXTPP consistently outperforms state-of-the-art models. The source code can be found at https://github.com/AONE-NLP/NEXTPP.
How Uncertain Is the Grade? A Benchmark of Uncertainty Metrics for LLM-Based Automatic Assessment
Feb 17, 2026The rapid rise of large language models (LLMs) is reshaping the landscape of automatic assessment in education. While these systems demonstrate substantial advantages in adaptability to diverse question types and flexibility in output formats, they also introduce new challenges related to output uncertainty, stemming from the inherently probabilistic nature of LLMs. Output uncertainty is an inescapable challenge in automatic assessment, as assessment results often play a critical role in informing subsequent pedagogical actions, such as providing feedback to students or guiding instructional decisions. Unreliable or poorly calibrated uncertainty estimates can lead to unstable downstream interventions, potentially disrupting students' learning processes and resulting in unintended negative consequences. To systematically understand this challenge and inform future research, we benchmark a broad range of uncertainty quantification methods in the context of LLM-based automatic assessment. Although the effectiveness of these methods has been demonstrated in many tasks across other domains, their applicability and reliability in educational settings, particularly for automatic grading, remain underexplored. Through comprehensive analyses of uncertainty behaviors across multiple assessment datasets, LLM families, and generation control settings, we characterize the uncertainty patterns exhibited by LLMs in grading scenarios. Based on these findings, we evaluate the strengths and limitations of different uncertainty metrics and analyze the influence of key factors, including model families, assessment tasks, and decoding strategies, on uncertainty estimates. Our study provides actionable insights into the characteristics of uncertainty in LLM-based automatic assessment and lays the groundwork for developing more reliable and effective uncertainty-aware grading systems in the future.
Negative-Aware Diffusion Process for Temporal Knowledge Graph Extrapolation
Feb 09, 2026Temporal Knowledge Graph (TKG) reasoning seeks to predict future missing facts from historical evidence. While diffusion models (DM) have recently gained attention for their ability to capture complex predictive distributions, two gaps remain: (i) the generative path is conditioned only on positive evidence, overlooking informative negative context, and (ii) training objectives are dominated by cross-entropy ranking, which improves candidate ordering but provides little supervision over the calibration of the denoised embedding. To bridge this gap, we introduce Negative-Aware Diffusion model for TKG Extrapolation (NADEx). Specifically, NADEx encodes subject-centric histories of entities, relations and temporal intervals into sequential embeddings. NADEx perturbs the query object in the forward process and reconstructs it in reverse with a Transformer denoiser conditioned on the temporal-relational context. We further derive a cosine-alignment regularizer derived from batch-wise negative prototypes, which tightens the decision boundary against implausible candidates. Comprehensive experiments on four public TKG benchmarks demonstrate that NADEx delivers state-of-the-art performance.
DrawSim-PD: Simulating Student Science Drawings to Support NGSS-Aligned Teacher Diagnostic Reasoning
Feb 02, 2026Developing expertise in diagnostic reasoning requires practice with diverse student artifacts, yet privacy regulations prohibit sharing authentic student work for teacher professional development (PD) at scale. We present DrawSim-PD, the first generative framework that simulates NGSS-aligned, student-like science drawings exhibiting controllable pedagogical imperfections to support teacher training. Central to our approach are apability profiles--structured cognitive states encoding what students at each performance level can and cannot yet demonstrate. These profiles ensure cross-modal coherence across generated outputs: (i) a student-like drawing, (ii) a first-person reasoning narrative, and (iii) a teacher-facing diagnostic concept map. Using 100 curated NGSS topics spanning K-12, we construct a corpus of 10,000 systematically structured artifacts. Through an expert-based feasibility evaluation, K--12 science educators verified the artifacts' alignment with NGSS expectations (>84% positive on core items) and utility for interpreting student thinking, while identifying refinement opportunities for grade-band extremes. We release this open infrastructure to overcome data scarcity barriers in visual assessment research.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Exploiting Inter-Session Information with Frequency-enhanced Dual-Path Networks for Sequential Recommendation
Nov 14, 2025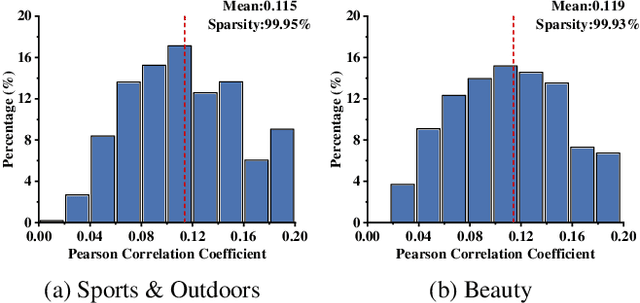
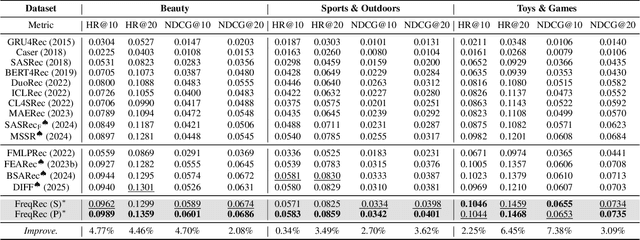
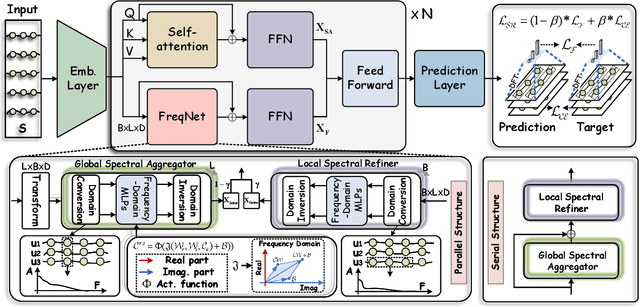
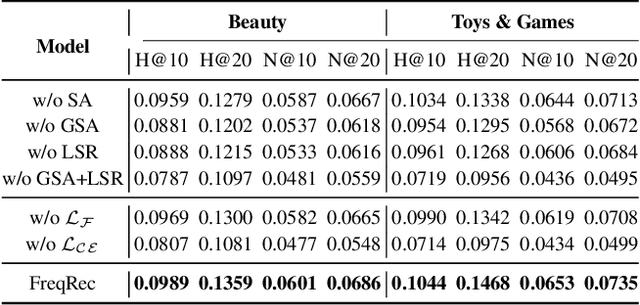
Sequential recommendation (SR) aims to predict a user's next item preference by modeling historical interaction sequences. Recent advances often integrate frequency-domain modules to compensate for self-attention's low-pass nature by restoring the high-frequency signals critical for personalized recommendations. Nevertheless, existing frequency-aware solutions process each session in isolation and optimize exclusively with time-domain objectives. Consequently, they overlook cross-session spectral dependencies and fail to enforce alignment between predicted and actual spectral signatures, leaving valuable frequency information under-exploited. To this end, we propose FreqRec, a Frequency-Enhanced Dual-Path Network for sequential Recommendation that jointly captures inter-session and intra-session behaviors via a learnable Frequency-domain Multi-layer Perceptrons. Moreover, FreqRec is optimized under a composite objective that combines cross entropy with a frequency-domain consistency loss, explicitly aligning predicted and true spectral signatures. Extensive experiments on three benchmarks show that FreqRec surpasses strong baselines and remains robust under data sparsity and noisy-log conditions.
RECALL: REpresentation-aligned Catastrophic-forgetting ALLeviation via Hierarchical Model Merging
Oct 23, 2025We unveil that internal representations in large language models (LLMs) serve as reliable proxies of learned knowledge, and propose RECALL, a novel representation-aware model merging framework for continual learning without access to historical data. RECALL computes inter-model similarity from layer-wise hidden representations over clustered typical samples, and performs adaptive, hierarchical parameter fusion to align knowledge across models. This design enables the preservation of domain-general features in shallow layers while allowing task-specific adaptation in deeper layers. Unlike prior methods that require task labels or incur performance trade-offs, RECALL achieves seamless multi-domain integration and strong resistance to catastrophic forgetting. Extensive experiments across five NLP tasks and multiple continual learning scenarios show that RECALL outperforms baselines in both knowledge retention and generalization, providing a scalable and data-free solution for evolving LLMs.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.