 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
Constraints Matrix Diffusion based Generative Neural Solver for Vehicle Routing Problems
Mar 08, 2026Over the past decade, neural network solvers powered by generative artificial intelligence have garnered significant attention in the domain of vehicle routing problems (VRPs), owing to their exceptional computational efficiency and superior reasoning capabilities. In particular, autoregressive solvers integrated with reinforcement learning have emerged as a prominent trend. However, much of the existing work emphasizes large-scale generalization of neural approaches while neglecting the limited robustness of attention-based methods across heterogeneous distributions of problem parameters. Their improvements over heuristic search remain largely restricted to hand-curated, fixed-distribution benchmarks. Furthermore, these architectures tend to degrade significantly when node representations are highly similar or when tasks involve long decision horizons. To address the aforementioned limitations, we propose a novel fusion neural network framework that employs a discrete noise graph diffusion model to learn the underlying constraints of vehicle routing problems and generate a constraint assignment matrix. This matrix is subsequently integrated adaptively into the feature representation learning and decision process of the autoregressive solver, serving as a graph structure mask that facilitates the formation of solutions characterized by both global vision and local feature integration. To the best of our knowledge, this work represents the first comprehensive experimental investigation of neural network model solvers across a 378-combinatorial space spanning four distinct dimensions within the CVRPlib public dataset. Extensive experimental evaluations demonstrate that our proposed fusion model effectively captures and leverages problem constraints, achieving state-of-the-art performance across multiple benchmark datasets.
WorldCompass: Reinforcement Learning for Long-Horizon World Models
Feb 09, 2026This work presents WorldCompass, a novel Reinforcement Learning (RL) post-training framework for the long-horizon, interactive video-based world models, enabling them to explore the world more accurately and consistently based on interaction signals. To effectively "steer" the world model's exploration, we introduce three core innovations tailored to the autoregressive video generation paradigm: 1) Clip-level rollout Strategy: We generate and evaluate multiple samples at a single target clip, which significantly boosts rollout efficiency and provides fine-grained reward signals. 2) Complementary Reward Functions: We design reward functions for both interaction-following accuracy and visual quality, which provide direct supervision and effectively suppress reward-hacking behaviors. 3) Efficient RL Algorithm: We employ the negative-aware fine-tuning strategy coupled with various efficiency optimizations to efficiently and effectively enhance model capacity. Evaluations on the SoTA open-source world model, WorldPlay, demonstrate that WorldCompass significantly improves interaction accuracy and visual fidelity across various scenarios.
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Dec 16, 2025This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.
MoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
Dec 08, 2025Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: https://lizhiqi49.github.io/MoCA
StyleSculptor: Zero-Shot Style-Controllable 3D Asset Generation with Texture-Geometry Dual Guidance
Sep 16, 2025Creating 3D assets that follow the texture and geometry style of existing ones is often desirable or even inevitable in practical applications like video gaming and virtual reality. While impressive progress has been made in generating 3D objects from text or images, creating style-controllable 3D assets remains a complex and challenging problem. In this work, we propose StyleSculptor, a novel training-free approach for generating style-guided 3D assets from a content image and one or more style images. Unlike previous works, StyleSculptor achieves style-guided 3D generation in a zero-shot manner, enabling fine-grained 3D style control that captures the texture, geometry, or both styles of user-provided style images. At the core of StyleSculptor is a novel Style Disentangled Attention (SD-Attn) module, which establishes a dynamic interaction between the input content image and style image for style-guided 3D asset generation via a cross-3D attention mechanism, enabling stable feature fusion and effective style-guided generation. To alleviate semantic content leakage, we also introduce a style-disentangled feature selection strategy within the SD-Attn module, which leverages the variance of 3D feature patches to disentangle style- and content-significant channels, allowing selective feature injection within the attention framework. With SD-Attn, the network can dynamically compute texture-, geometry-, or both-guided features to steer the 3D generation process. Built upon this, we further propose the Style Guided Control (SGC) mechanism, which enables exclusive geometry- or texture-only stylization, as well as adjustable style intensity control. Extensive experiments demonstrate that StyleSculptor outperforms existing baseline methods in producing high-fidelity 3D assets.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation
Jun 04, 2025Real-world applications like video gaming and virtual reality often demand the ability to model 3D scenes that users can explore along custom camera trajectories. While significant progress has been made in generating 3D objects from text or images, creating long-range, 3D-consistent, explorable 3D scenes remains a complex and challenging problem. In this work, we present Voyager, a novel video diffusion framework that generates world-consistent 3D point-cloud sequences from a single image with user-defined camera path. Unlike existing approaches, Voyager achieves end-to-end scene generation and reconstruction with inherent consistency across frames, eliminating the need for 3D reconstruction pipelines (e.g., structure-from-motion or multi-view stereo). Our method integrates three key components: 1) World-Consistent Video Diffusion: A unified architecture that jointly generates aligned RGB and depth video sequences, conditioned on existing world observation to ensure global coherence 2) Long-Range World Exploration: An efficient world cache with point culling and an auto-regressive inference with smooth video sampling for iterative scene extension with context-aware consistency, and 3) Scalable Data Engine: A video reconstruction pipeline that automates camera pose estimation and metric depth prediction for arbitrary videos, enabling large-scale, diverse training data curation without manual 3D annotations. Collectively, these designs result in a clear improvement over existing methods in visual quality and geometric accuracy, with versatile applications.
Towards Constraint-Based Adaptive Hypergraph Learning for Solving Vehicle Routing: An End-to-End Solution
Mar 13, 2025



The application of learning based methods to vehicle routing problems has emerged as a pivotal area of research in combinatorial optimization. These problems are characterized by vast solution spaces and intricate constraints, making traditional approaches such as exact mathematical models or heuristic methods prone to high computational overhead or reliant on the design of complex heuristic operators to achieve optimal or near optimal solutions. Meanwhile, although some recent learning-based methods can produce good performance for VRP with straightforward constraint scenarios, they often fail to effectively handle hard constraints that are common in practice. This study introduces a novel end-to-end framework that combines constraint-oriented hypergraphs with reinforcement learning to address vehicle routing problems. A central innovation of this work is the development of a constraint-oriented dynamic hyperedge reconstruction strategy within an encoder, which significantly enhances hypergraph representation learning. Additionally, the decoder leverages a double-pointer attention mechanism to iteratively generate solutions. The proposed model is trained by incorporating asynchronous parameter updates informed by hypergraph constraints and optimizing a dual loss function comprising constraint loss and policy gradient loss. The experiment results on benchmark datasets demonstrate that the proposed approach not only eliminates the need for sophisticated heuristic operators but also achieves substantial improvements in solution quality.
Phidias: A Generative Model for Creating 3D Content from Text, Image, and 3D Conditions with Reference-Augmented Diffusion
Sep 17, 2024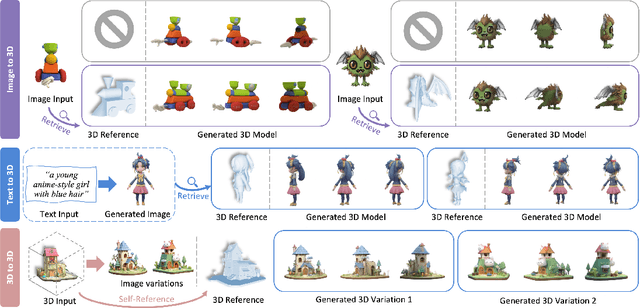
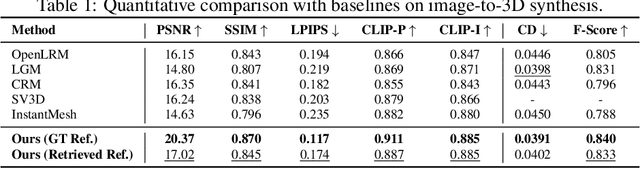
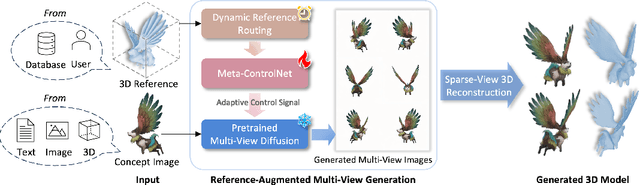
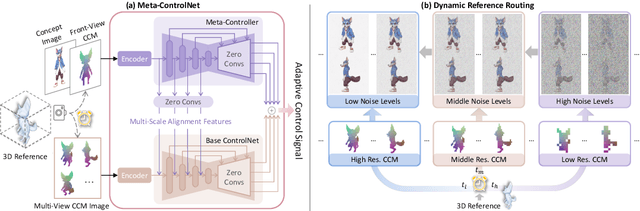
In 3D modeling, designers often use an existing 3D model as a reference to create new ones. This practice has inspired the development of Phidias, a novel generative model that uses diffusion for reference-augmented 3D generation. Given an image, our method leverages a retrieved or user-provided 3D reference model to guide the generation process, thereby enhancing the generation quality, generalization ability, and controllability. Our model integrates three key components: 1) meta-ControlNet that dynamically modulates the conditioning strength, 2) dynamic reference routing that mitigates misalignment between the input image and 3D reference, and 3) self-reference augmentations that enable self-supervised training with a progressive curriculum. Collectively, these designs result in a clear improvement over existing methods. Phidias establishes a unified framework for 3D generation using text, image, and 3D conditions with versatile applications.